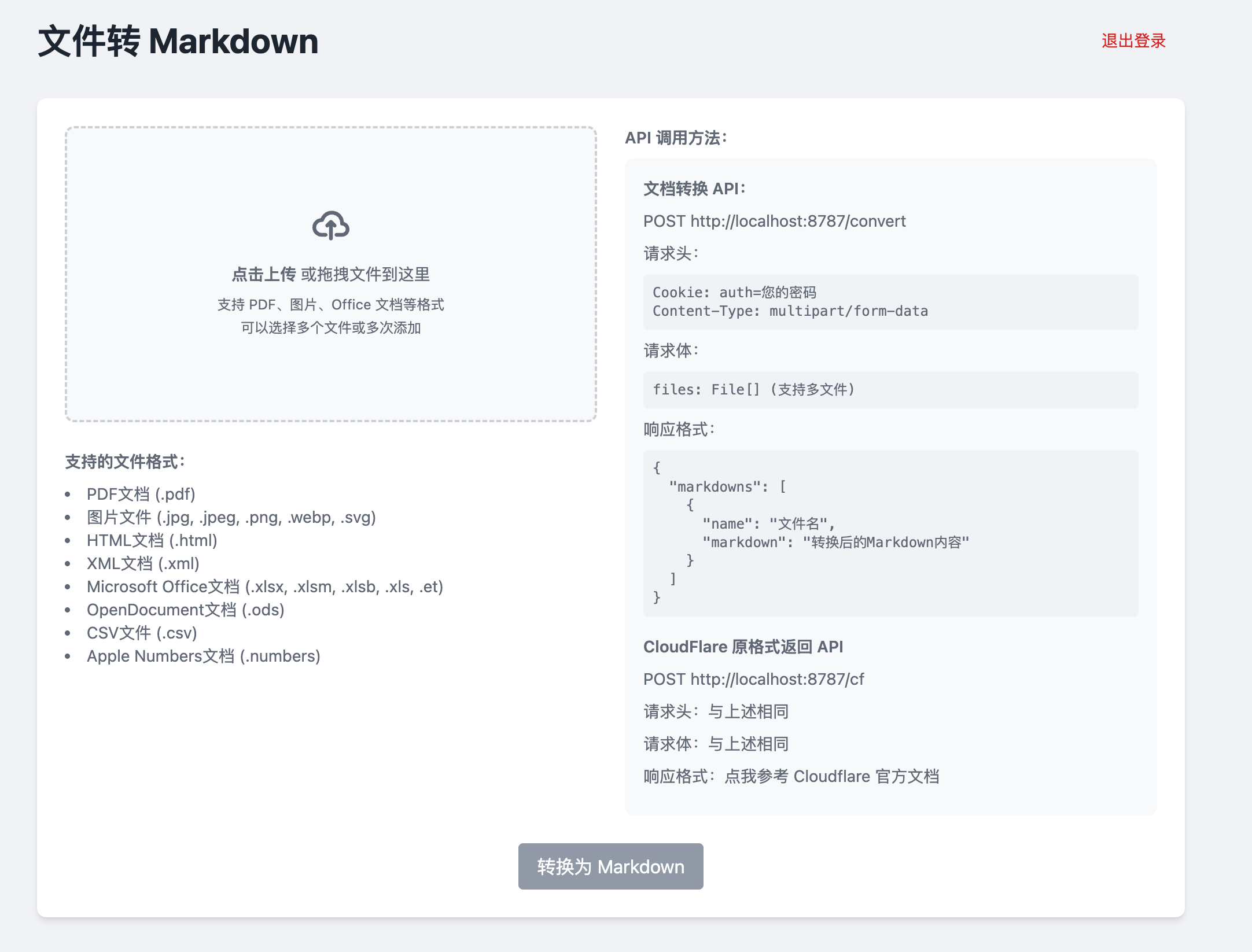
Kreuzberg: Open-Source-Tool zum Extrahieren von Text aus beliebigen Dokumenten

Allgemeine Einführung
Kreuzberg ist eine Bibliothek zur Vereinfachung der Textextraktion aus PDF-Dateien, entwickelt, um eine einfache, problemlose Lösung zur Textextraktion zu bieten. Die Bibliothek eignet sich besonders gut für RAG-Dienste (Retrieval-Augmented Generation), die eine Textextraktion erfordern.Kreuzberg unterstützt den lokalen Betrieb, ist einfach zu steuern und kostengünstig. Sie kombiniert eine Vielzahl von Open-Source- und kommerziellen Optionen, um flexible Textextraktionsmöglichkeiten zu bieten.

Funktionsliste
- PDF-Text-ExtraktionExtrahieren von Textinhalten aus PDF-Dateien.
- Bild/PDF OCRTesseract-OCR: Optische Zeichenerkennung von Bildern und PDFs mit Tesseract-OCR.
- Extraktion von Nicht-PDF-TextPandoc: Extraktion von Text in anderen Formaten über Pandoc.
- lokaler BetriebUnterstützt lokale Installation und Bedienung, einfache Steuerung und Verwaltung.
- Quelloffen und kostenlos: Basiert auf der MIT-Lizenz, Open Source, kostenlos.
Hilfe verwenden
Einbauverfahren
- Installation von Python-Paketen::
pip install kreuzberg
- Installation von Systemabhängigkeiten::
- Pandocfür Nicht-PDF-Textextraktion (GPL v2.0-Lizenz, nur als CLI verwendet).
- Tesseract-OCROCR für Bilder und PDFs (Apache-Lizenz).
Leitlinien für die Verwendung
- Grundlegende Verwendung::
- Importieren Sie die Bibliothek und initialisieren Sie sie:
python
from kreuzberg import Kreuzberg
extractor = Kreuzberg() - PDF-Text extrahieren:
python
text = extractor.extract_text('path/to/pdf/file.pdf')
print(text)
- Importieren Sie die Bibliothek und initialisieren Sie sie:
- OCR-Funktion::
- OCR eines Bildes oder einer PDF-Datei:
python
ocr_text = extractor.ocr('path/to/image_or_pdf')
print(ocr_text)
- OCR eines Bildes oder einer PDF-Datei:
- Extraktion von Nicht-PDF-Text::
- Verwenden Sie Pandoc, um Text in anderen Formaten zu extrahieren:
python
other_text = extractor.extract_text('path/to/other/file')
print(other_text)
- Verwenden Sie Pandoc, um Text in anderen Formaten zu extrahieren:
Detaillierte Funktionsabläufe
- PDF-Text-Extraktion::
- Stellen Sie sicher, dass der Pfad der PDF-Datei korrekt ist.
- ausnutzen
extract_textMethode, um den Text zu extrahieren. - Verarbeiten Sie die extrahierten Textdaten für nachfolgende Operationen.
- OCR-Funktion::
- Installieren und konfigurieren Sie Tesseract-OCR.
- ausnutzen
ocrMethode zur OCR-Verarbeitung von Bildern oder PDFs. - OCR-Ergebnisse abrufen und verarbeiten.
- Extraktion von Nicht-PDF-Text::
- Installieren und konfigurieren Sie Pandoc.
- ausnutzen
extract_textMethode, um Text in anderen Formaten zu extrahieren. - Verarbeiten Sie die extrahierten Textdaten für nachfolgende Operationen.
Durch die oben beschriebenen Schritte können die Benutzer leicht mit Kreuzberg Textextraktionsoperationen beginnen, um eine Vielzahl von Textverarbeitungsanforderungen zu erfüllen.
© urheberrechtliche Erklärung
Der Artikel ist urheberrechtlich geschützt und darf nicht ohne Genehmigung vervielfältigt werden.

Ähnliche Artikel


Keine Kommentare...