kimi lanciert visuelle Version von o1, um Probleme visuell zu denken und zu lösen大家都在用AI工具,我们看着AI一步一步发展壮大,以前大部分是我们仅仅用文字跟它们聊天,有些时候果核就会在想:要是什么时候能对图片进行很好的思考就好了。 研究了一堆AI之后,后面用起Kimi,发现它的...AI-Nachrichtenvor 6 Monaten01.1K0
OpenAI veröffentlicht offiziell o3 und o3-mini, die ersten KI-Modelle, die die ARC-AGI-Benchmarks brechen 今天凌晨2点,OpenAI的12天直播,终于来到了最终章。OpenAI o3正式发布! o3 是 o1 系列模型的继任者。这类模型的特点是让模型在回答问题之前花更多时间思考(推理),从而提高回答的...AI-Nachrichtenvor 6 Monaten02.3K0
免费!! Github联合Azure免费向开发者提供包括o1在内顶级闭源开源模型API调用屏幕上密密麻麻的代码中夹杂着各种模型API的配置信息,桌上的咖啡早已凉透。 这是许多开发者在尝试构建AI应用时的真实写照:环境配置繁琐、API成本高昂、文档支持不足...... "如果能有一个统一的平...AI-Nachrichtenvor 6 Monaten09880
7 AI-Audioproduktionstools, die man kennen muss, um Sound, Stimme und Musik zu verbessern und zu erzeugen在不断发展的 音频制作 领域,人工智能正在取得显著进展,提供了一套能够彻底改变创作者在 声音设计 中方法的工具。对于播客制作者、音乐人和内容创作者来说,这些进步意味着更高效的工作流程和更高质量的音频效...AI-Nachrichtenvor 6 Monaten01K0
10 großartige kostenlose AI-Tools zur Erstellung von Texten, Bildern, Videos und mehr im Jahr 2024如果您正在寻找经济实惠的人工智能(AI)工具,帮助您开始将 AI 日常化的旅程,从电子邮件到视频制作都可以轻松完成。这篇快速入门指南介绍了 10 个令人惊叹的 AI 服务和平台,让您无需花费辛苦赚来的...AI-Nachrichtenvor 6 Monaten01.1K0
Glean vs. Microsoft Copilot: Welches KI-Tool ist besser für Sie?每个人都希望在工作中提升自己的生产力和效率。无论是快速处理 Excel 表格的小技巧,还是能够轻松同步到现有工作流程的工具,在竞争激烈且动态多变的职场中,每一点优势都至关重要。⚡ 这正是像 Glean...AI-Nachrichtenvor 6 Monaten01.2K0
Google veröffentlicht sein eigenes KI-Modell: Gemini 2.0 Flash Thinking ExperimentalGoogle 发布了一款被称为全新“推理”AI模型的产品——但目前还处于实验阶段,从我们的简短测试来看,该模型确实还有提升空间。 这款新模型名为 Gemini 2.0 Flash Thinking E...AI-Nachrichtenvor 6 Monaten09730
Das Startup Perplexity schließt eine Finanzierung mit einer Bewertung von 9 Mrd. Dollar ab该公司的估值自 6 月以来已翻了三倍。 Perplexity AI Inc. 是一家人工智能初创公司,正在开发一款搜索产品以与 Alphabet Inc. 的 Google 竞争。据知情人士透露...AI-Nachrichtenvor 6 Monaten08900
OpenAI erleidet eine weitere personelle Umstrukturierung, da der Vater von GPT das Unternehmen verlässt 重磅消息在AI圈炸响。被业界誉为"GPT之父"的OpenAI传奇研究员Alec Radford宣布离职,转向独立研究。作为ChatGPT背后核心技术GPT系列的首席设计师,Radford的这一决定...AI-Nachrichtenvor 6 Monaten01.2K0
GitHub hat offiziell den GitHub Copilot Free Plan angekündigt, der jetzt für alle Nutzer verfügbar ist! GitHub 日前宣布,其 AI 编程助手 GitHub Copilot 推出免费计划,现已在 Visual Studio Code 中向所有用户开放。用户只需拥有 GitHub 账户即可开始使用...AI-Nachrichtenvor 6 Monaten01.1K0
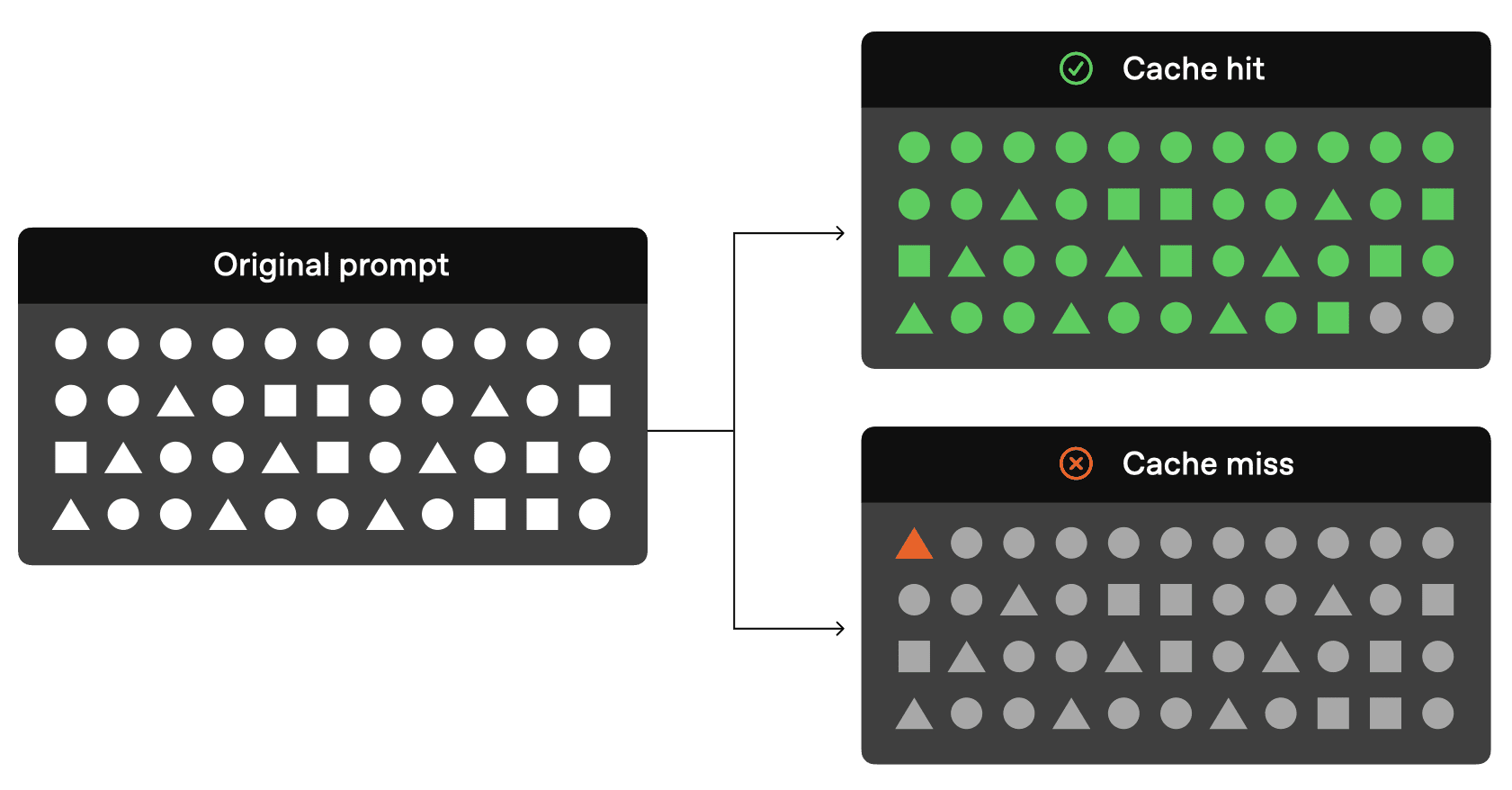
OpenAI hat damit begonnen, Prompt Caching für große Modelle (Modelle der GPT-Serie) anzubieten: Der Preis für Modelleingaben der GPT-4o-Serie wurde halbiert, und die Zugriffsgeschwindigkeit wurde um 801 TP3T erhöht在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近...AI-Nachrichtenvor 6 Monaten01.2K0
Offizieller Claude-Insight-Bericht: Chinesische Benutzer lieben das Schreiben von Romanen mit ClaudeClio: 一个用于保护隐私的真实世界 AI 使用洞察系统 人们使用 AI 模型做什么?尽管大语言模型的流行度迅速增长,但直到现在,我们对它们的具体使用方式还缺乏深入的了解。 这不仅仅是好奇心的问题...AI-Nachrichtenvor 6 Monaten09990
HuggingFace stellt die technischen Details von o1 vor und stellt sie als Open Source zur Verfügung!如果给小模型更长的思考时间,它们性能可以超越更大规模的模型。 最近一段时间,业内对小模型的研究热情空前地高涨,通过一些「实用技巧」让它们在性能上超越更大规模的模型。 可以说,将目光放到提升较小...AI-Nachrichtenvor 6 Monaten09690
Auf Wiedersehen LangChain, Atomic Agents ist in Flammen!像LangChain、CrewAI和AutoGen这样的框架通过提供构建人工智能系统的高级抽象而广受欢迎。然而,包括我在内的许多开发人员都发现,这些工具弊大于利,常常给开发过程带来不必要的复杂性和挫折...AI-Nachrichtenvor 6 Monaten08610
Cohere AI bringt Rerank 3.5 auf den Markt: Eine neue Ära der Technologie zur Sortierung von relevantem Wissen概述 在信息爆炸的时代,企业对搜索技术的依赖已不仅仅是为了找到内容,而是为了提升效率和生产力。然而,传统搜索模型往往难以真正理解用户意图,导致搜索结果不准确、不相关甚至不完整。这种体验不仅让用户倍感挫...AI-Nachrichtenvor 6 Monaten09330
OpenAi auf dem neuen Projekt, 0 Basis zu bauen Forschung Wissensbasis! Die Beseitigung der künstlichen ist eine ausgemachte Sache每个人0基础自定义“科研知识库模型”。模型淘汰人工客服已成定局! 【Openai发布Project功能】 1.支持文件上传到 Project,构建特定领域的知识库。 2.支持联网搜索,实时获取最新...AI-Nachrichtenvor 6 Monaten08880
Befehl R7B: Verbesserte Abfrage und Schlussfolgerungen, mehrsprachige Unterstützung, schnelle und effiziente generative KI我们 R 系列中最小的模型提供顶级的速度、效率和质量,可在普通 GPU 和边缘设备上构建强大的 AI 应用程序。 今天,我们很高兴发布 Command R7B,这是我们专为企业开发的大语言模型(LLM...AI-Nachrichtenvor 5 Monaten01K0
Smart Spectrum veröffentlicht ein kostenloses Vision-Modell GLM-4V-Flash Gleichzeitigkeitsgrenze auf 10 erhöht, dieses Mal genug für ProduktionsumgebungenGLM-4V系列 GLM-4V系列包含3款模型,分别适用于不同的应用场景。 GLM-4V-Plus:具备卓越的多模态理解能力,可同时处理最多5张图像,并支持视频内容理解,适用于复杂的多媒体分析场景。 ...AI-Nachrichtenvor 6 Monaten08950
Google veröffentlicht neu AI Video Veo2, AI Mapping Imagen3今年早些时候,谷歌推出了视频生成模型 Veo 和最新的图像生成模型 Imagen 3。从那时起,看到人们通过这些模型将他们的创意变为现实,令我们感到兴奋:YouTube 创作者正在探索为 YouTub...AI-Nachrichtenvor 6 Monaten08360