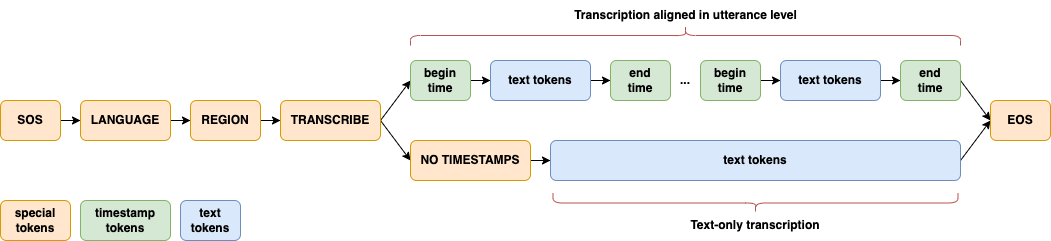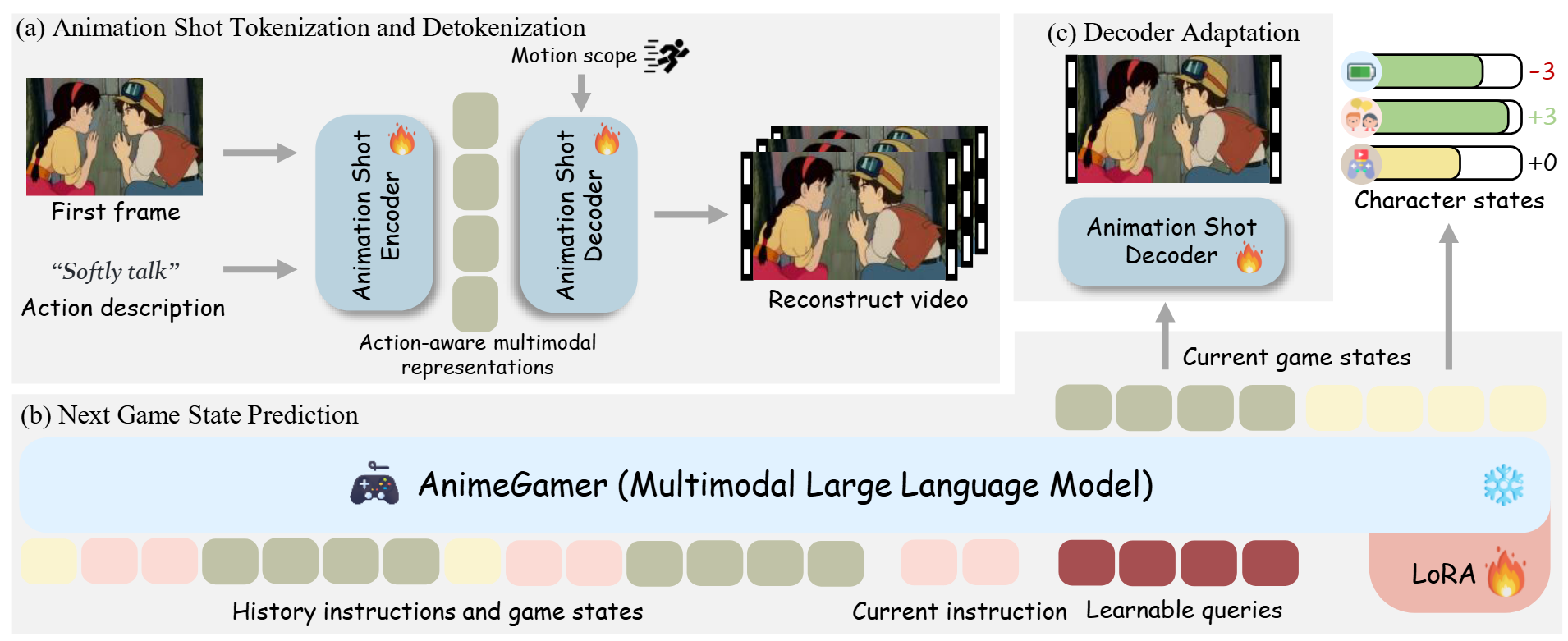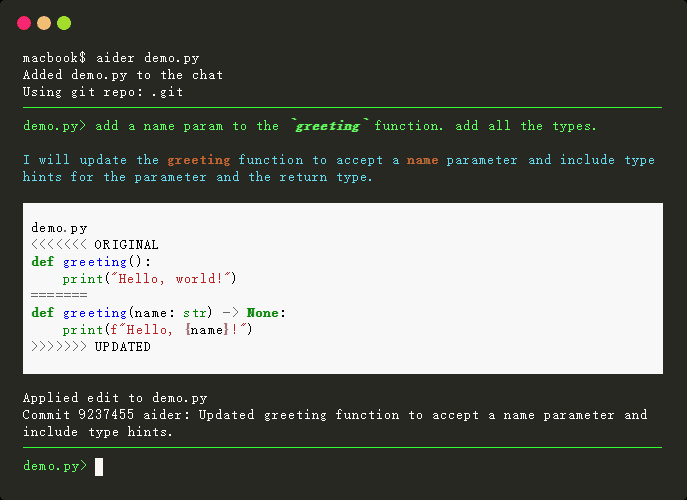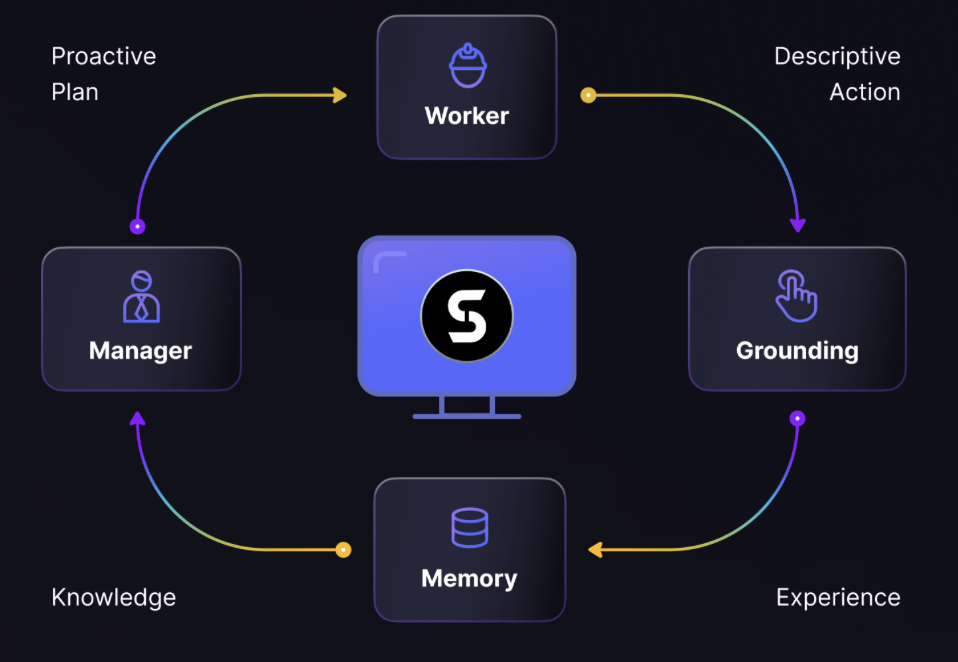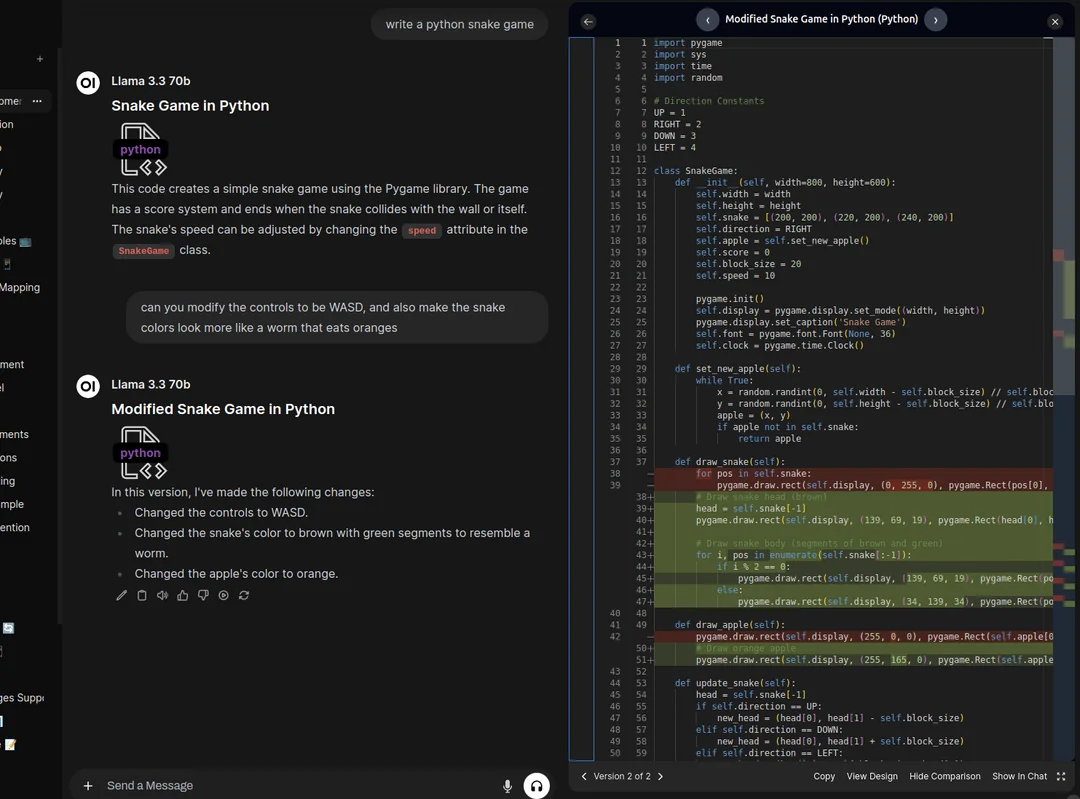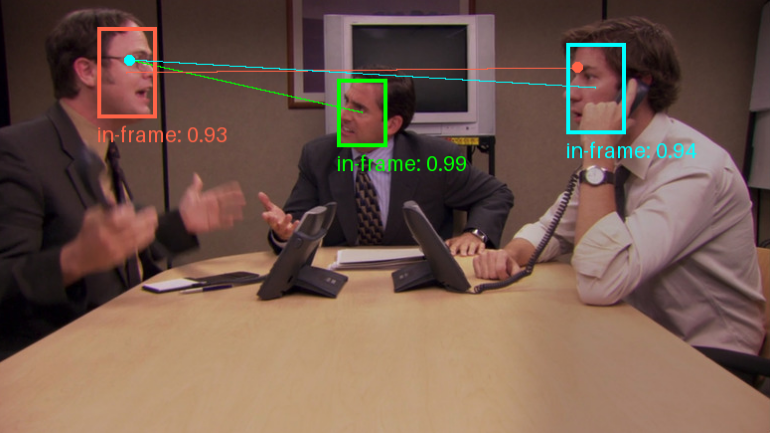
Automatisches Parsen von PDF-Inhalten und Extrahieren von Text und Tabellen von Open-Source-Diensten
Umfassende Einführung Es analysiert automatisch das Layout von PDF-Dokumenten, identifiziert Text, Titel, Bilder, Tabellen, Formeln und andere Elemente auf der Seite und bestimmt ihre richtige Reihenfolge. Das Tool unterstützt OCR-Funktionalität und kann gescannte PDFs in durchsuchbaren Text umwandeln. Es läuft auf Docker und bietet zwei Modelle...