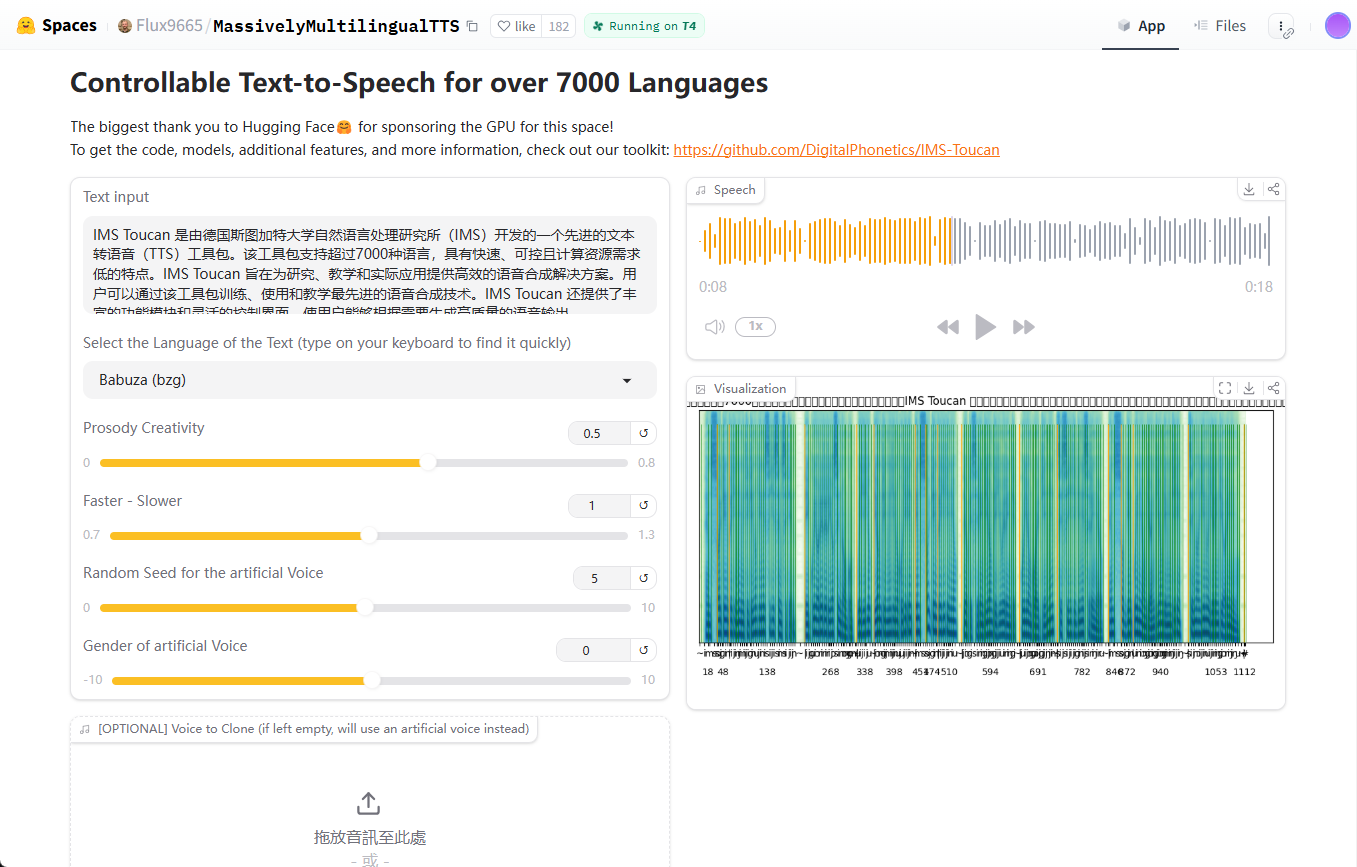
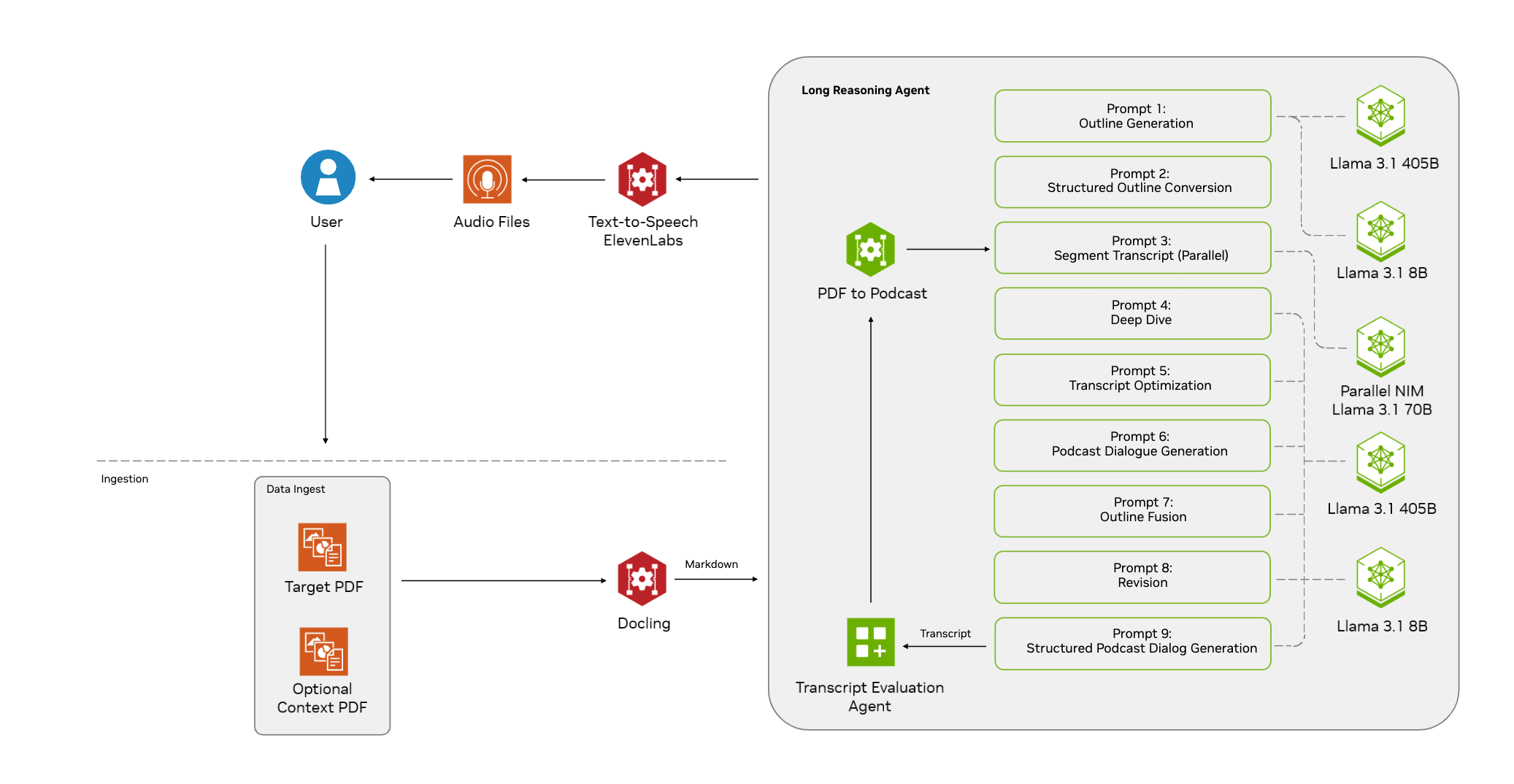
Allgemeine Einführung NVIDIA AI Blueprint: PDF to Podcast ist ein von NVIDIA entwickeltes Open-Source-Projekt zur Umwandlung von PDF-Dokumenten in ansprechende Audioinhalte. Das Projekt nutzt NVIDIA NIM (NVIDIA...
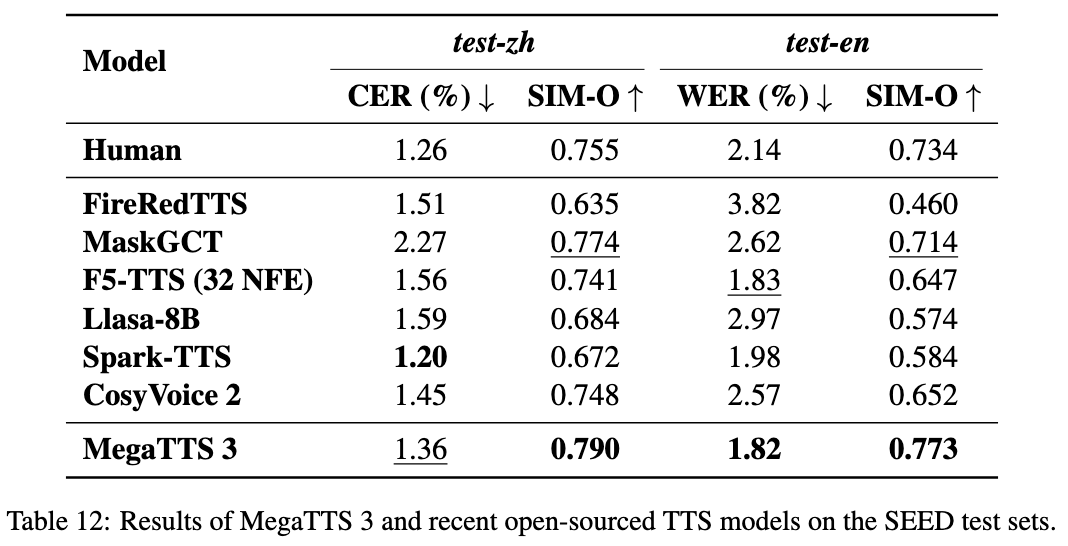
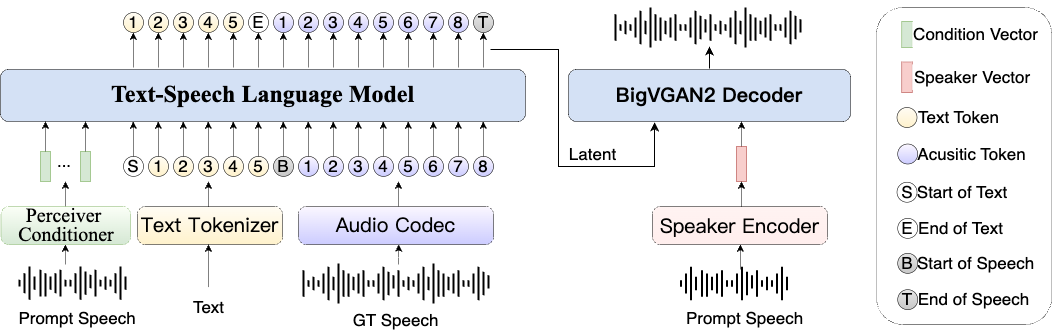
Umfassende Einführung MegaTTS3 ist ein Open-Source-Sprachsynthese-Tool, das von ByteDance in Zusammenarbeit mit der Zhejiang University entwickelt wurde und sich auf die Erzeugung hochwertiger chinesischer und englischer Sprache konzentriert. Sein Kernmodell besteht aus nur 0,45B Parametern, ist leichtgewichtig und effizient und unterstützt die Erzeugung gemischter chinesischer und englischer Sprache sowie das Klonen von Sprache. Das Projekt wird gehostet auf ...
Allgemeine Einführung PlayHT ist eine effiziente Online-Plattform, die sich auf die KI-Spracherzeugung konzentriert, um Nutzern zu helfen, Text schnell in natürliche und realistische Sprache umzuwandeln. Sie bietet mehr als 600 KI-Stimmen, die mehr als 60 Sprachen und verschiedene Akzente für die Produktion von Podcasts, Bildungsinhalten, Marketingwerbung...
Allgemeine Einführung MLX-Audio ist ein Open-Source-Tool, das auf der Grundlage des MLX-Frameworks von Apple entwickelt wurde und sich auf Text-to-Speech- (TTS) und Speech-to-Speech- (STS) Funktionen konzentriert. Es nutzt die Leistungsfähigkeit von Apple Silicon (z.B. Chips der M-Serie)...
Allgemeine Einführung IndexTTS ist ein Open-Source-Text-to-Speech (TTS)-Tool auf GitHub gehostet und vom index-tts-Team entwickelt. Es basiert auf XTTS und Tortoise Technologie, durch die Verbesserung des Moduldesigns, um eine effiziente und ...
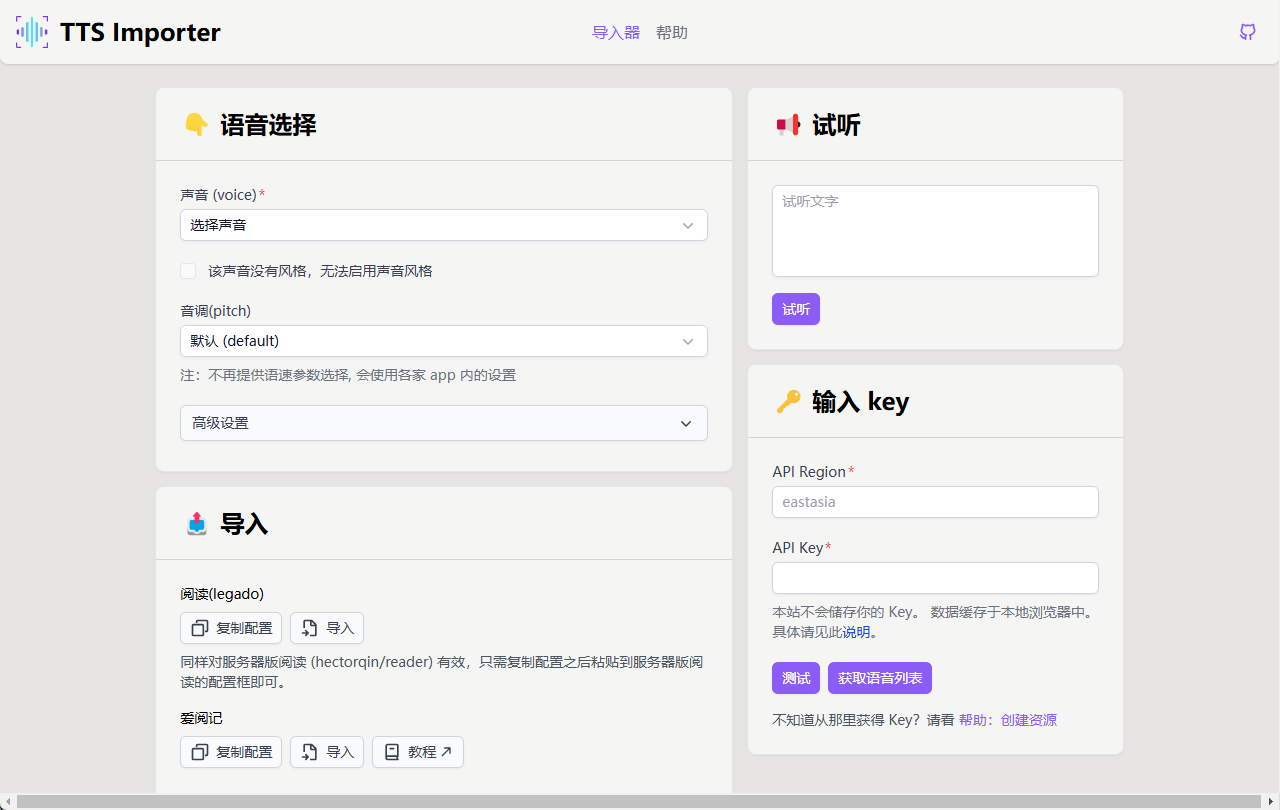
Allgemeine Einführung TTS Importer ist ein Open-Source-Projekt, das den einfachen Import von Azure TTS (Text-to-Speech) Sprachsynthesediensten in eine Vielzahl von Lesesoftware ermöglicht. Das Tool unterstützt mehrere beliebte Leseprogramme, darunter Read (legado...
Allgemeine Einführung "Cat & Star" (maoyuxing.com) ist eine interaktive Plattform zur Erstellung von Geschichten für Kinder, die es Eltern und Kindern ermöglicht, über mobile Anwendungen gemeinsam personalisierte Märchen zu erstellen. Die Nutzer können Informationen wie den Namen des Kindes und seine Vorlieben eingeben, um einzigartige Märcheninhalte zu erstellen...
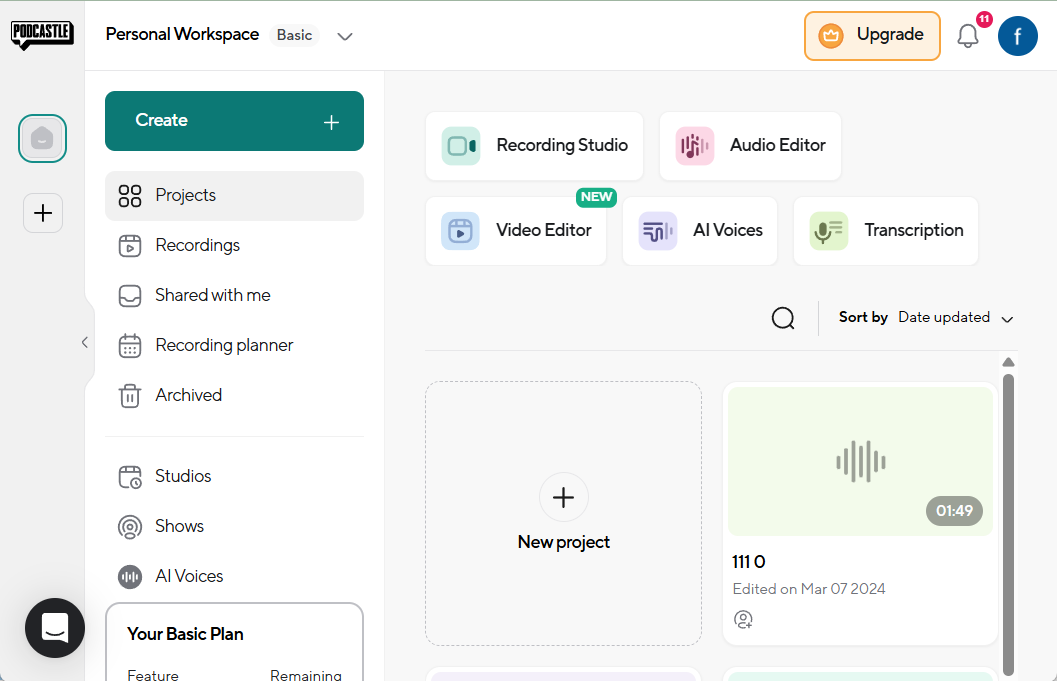
Allgemeine Einführung Podcastle ist eine KI-basierte Online-Plattform, die darauf spezialisiert ist, Nutzern bei der schnellen Erstellung und Bearbeitung hochwertiger Podcasts zu helfen. Sie integriert Aufnahme-, Bearbeitungs- und Veröffentlichungsfunktionen, und die Nutzer können dies alles über einen Browser erledigen, ohne dass sie spezielle Geräte oder komplexe Software benötigen. Die Plattform nutzt die ...
Umfassende Einführung csm-mlx basiert auf dem von Apple entwickelten MLX-Framework, das speziell für das Apple Silicon (Apple Silicon) CSM (Conversation Speech Model) Sprachdialogmodell optimiert ist. Dieses Projekt ermöglicht die Verwendung...
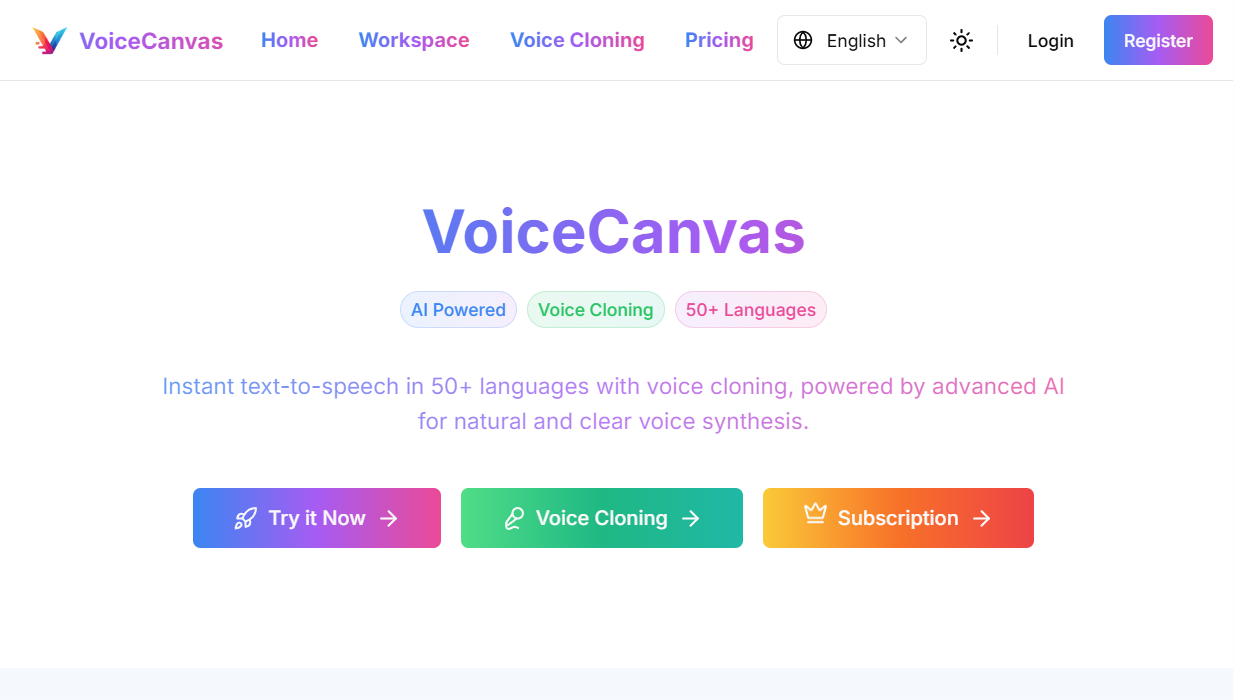
Allgemeine Einführung Open-VoiceCanvas ist eine Open-Source-Plattform für Sprachsynthese, die vom ItusiAI-Team entwickelt wurde. Sie unterstützt mehr als 50 Sprachen, kann Text in natürliche Sprache umwandeln und durch Hochladen von Audiodaten personalisierte Stimmen klonen. Das Projekt integriert Ope...
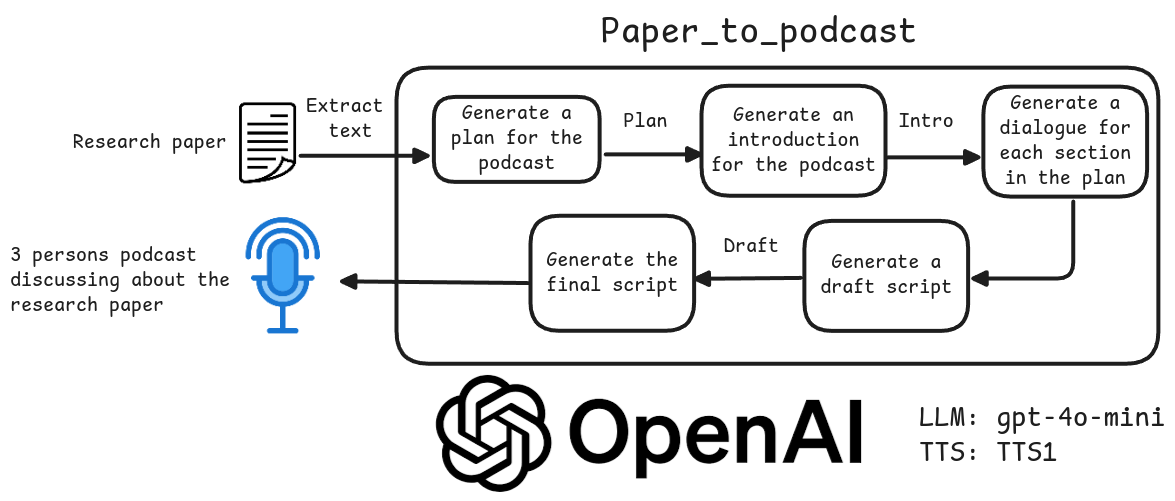
Allgemeine Einführung Paper to Podcast ist ein Open-Source-Tool, das darauf spezialisiert ist, akademische Forschungsarbeiten in lebendige und unterhaltsame Podcasts zu verwandeln. Es nutzt die Technologie der künstlichen Intelligenz, um ein PDF-formatiertes Papier in einen Dialog zwischen drei Charakteren - dem Moderator, dem Lernenden und dem Experten - zu verwandeln, um komplexe...
Umfassende Einführung MiniMax Audio ist ein KI-Sprachgenerierungstool von MiniMax, dessen Hauptfunktion die schnelle Umwandlung von Text in natürliche Sprache mit hoher Ähnlichkeit ist. Es basiert auf dem Modell Speech-02, mit einer Sprachsynthese-Ähnlichkeit von bis zu 99...
Allgemeine Einführung Autiobooks ist ein Open-Source-Tool, das Benutzern helfen soll, eBooks im .epub-Format schnell in Hörbücher im .m4b-Format zu konvertieren. Es verwendet die hochwertige Sprachsynthese-Technologie von Kokoro, um einen natürlichen und flüssigen Ton zu erzeugen. Dieses Tool wurde entwickelt von...
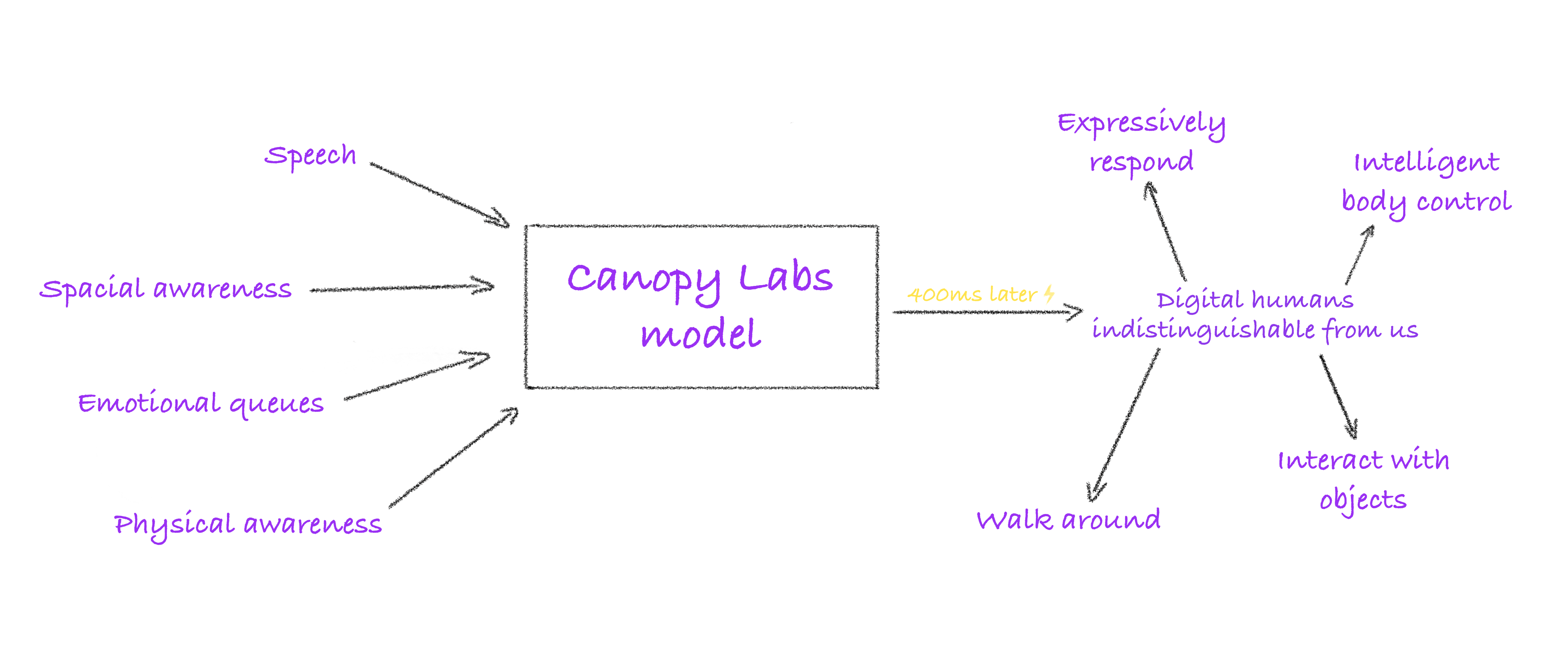
Allgemeine Einführung Orpheus-TTS ist ein Open-Source-Text-to-Speech (TTS)-System, das auf der Llama-3b-Architektur mit dem Ziel entwickelt wurde, Audio nahe der natürlichen menschlichen Sprache zu erzeugen. Es wird vom Canopy AI Team entwickelt und unterstützt Englisch, Spanisch, Französisch...
Allgemeine Einführung Text2Voice ist ein Open-Source-Tool, das Text-to-Speech-Funktionalität auf der Grundlage einer Silizium-basierten Mobilitäts-API bietet, mit einer sauberen grafischen Benutzeroberfläche (GUI) als seine beste Eigenschaft. Es wurde vom Entwickler Sheldon Lee auf GitHub erstellt, um...
Umfassende Einführung Vapi ist eine Sprach-KI-Plattform für Entwickler. Sie ermöglicht es Anwendern, Sprach-KI-Assistenten in Minutenschnelle zu erstellen, zu testen und einzusetzen und löst damit das Problem der zeitaufwändigen und schwer skalierbaren Entwicklung herkömmlicher Sprachanwendungen.Vapi bietet komplette Tools und Infrastrukturen zur Unterstützung von Echtzeitgesprächen,...
Allgemeine Einführung ElevenLabs MCP ist ein offizielles Open-Source-Projekt von ElevenLabs, das auf GitHub gehostet wird. Es ist ein Dienst, der auf dem Model Control Protocol (Model Context Protocol, MCP) basiert...
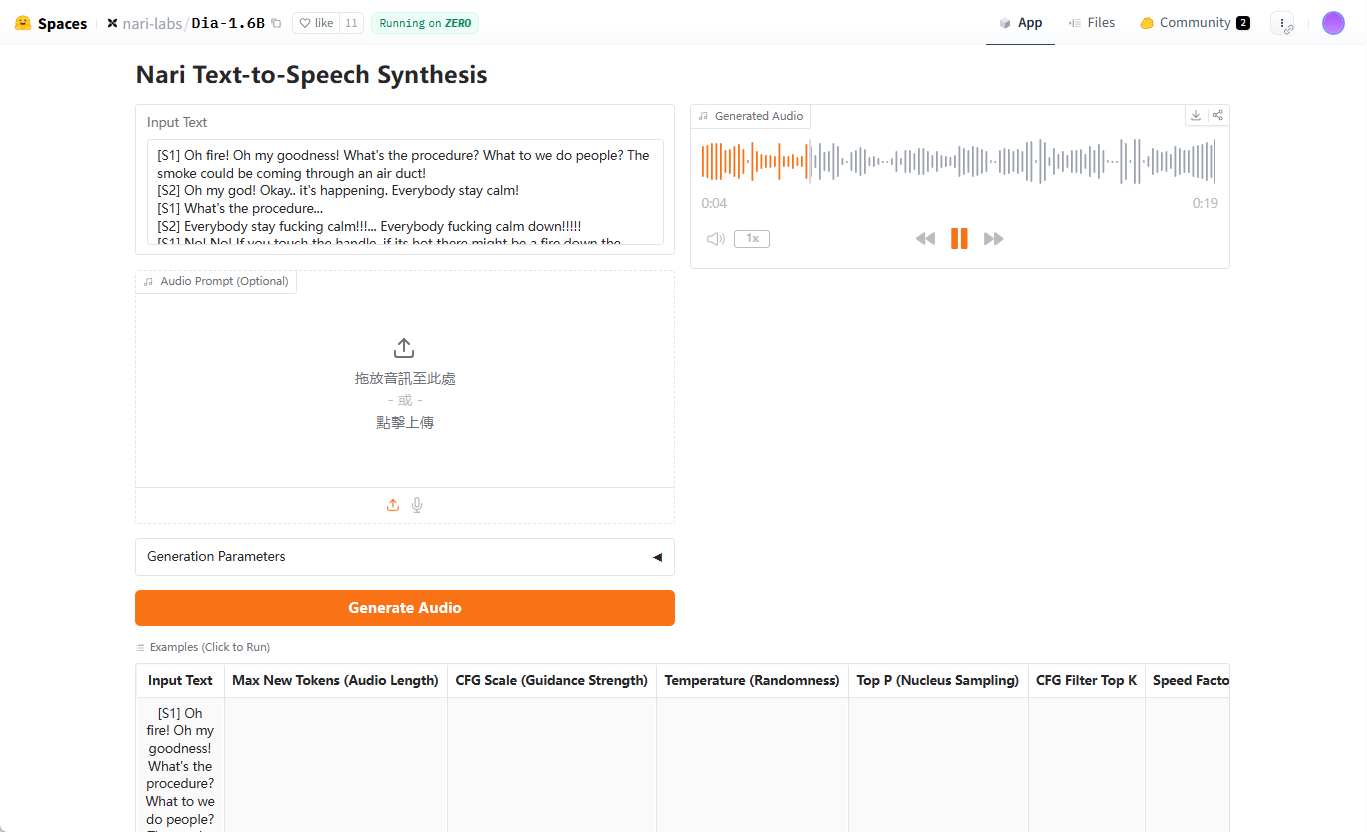
Allgemeine Einführung Dia ist ein Open-Source-Text-to-Speech (TTS)-Modell, das von Nari Labs entwickelt wurde und sich auf die Erzeugung von hyperrealistischem Dialog-Audio konzentriert. Es wandelt Text-Skripte in einem einzigen Prozess in realistische Multi-Charakter-Dialoge um, unterstützt Emotions- und Intonationskontrolle und generiert sogar nonverbale Repräsentationen...