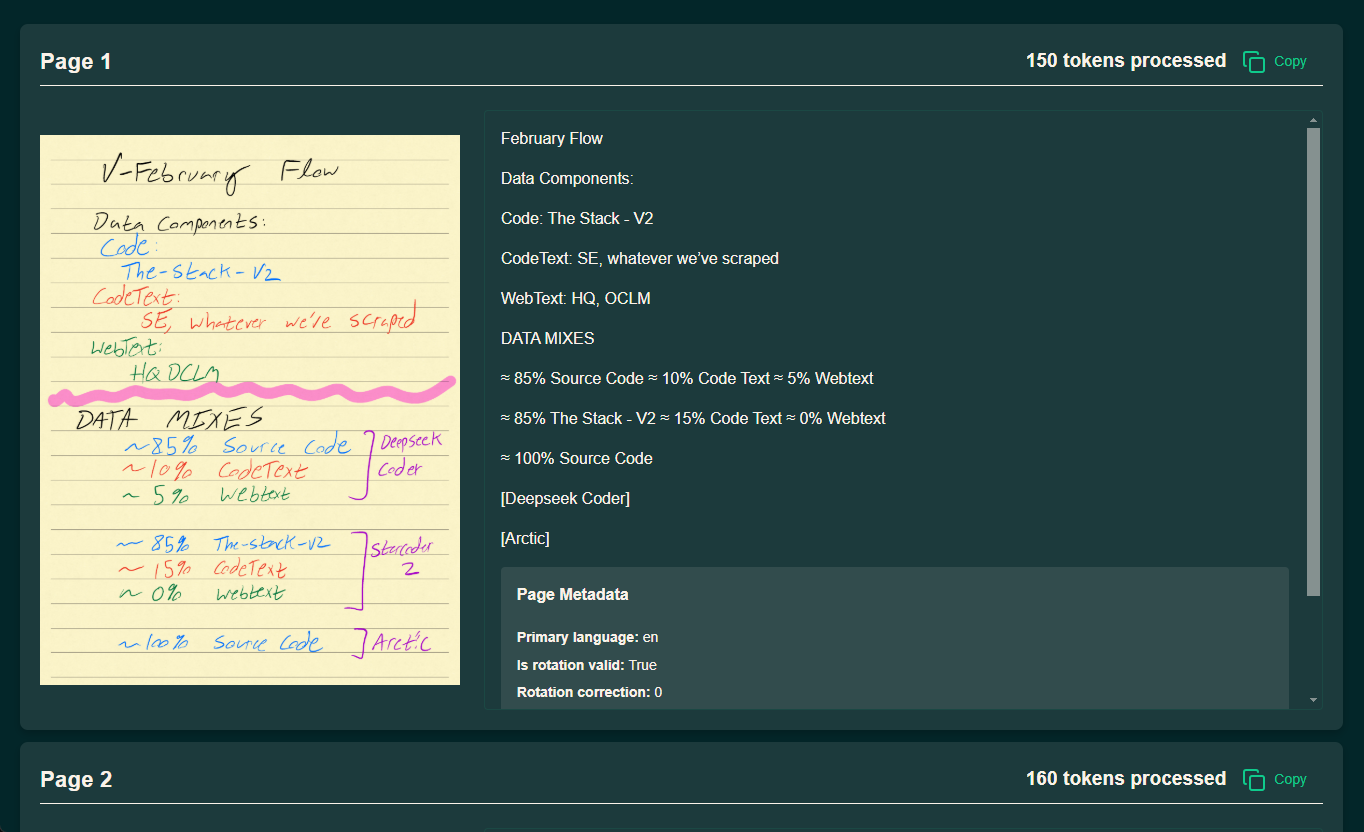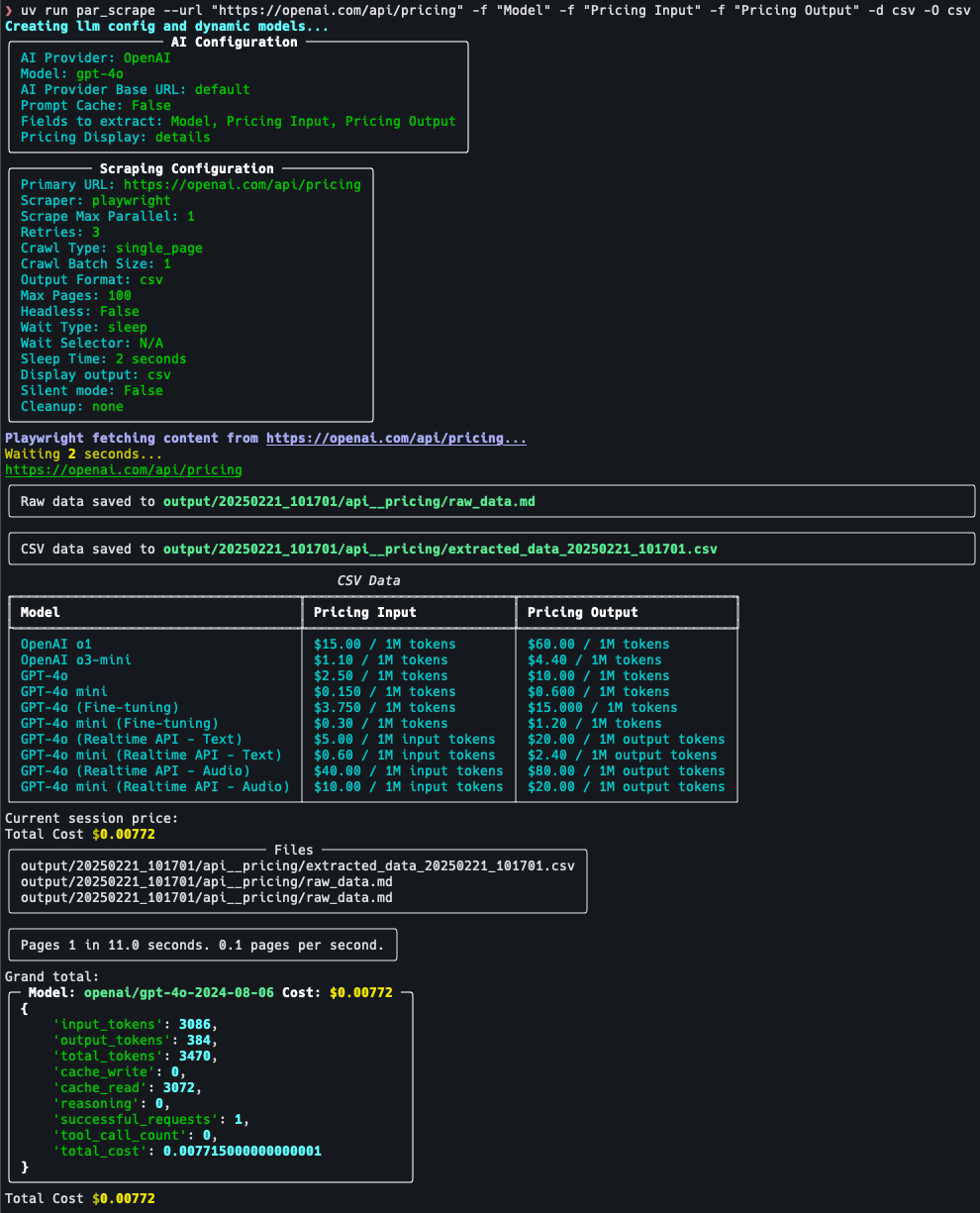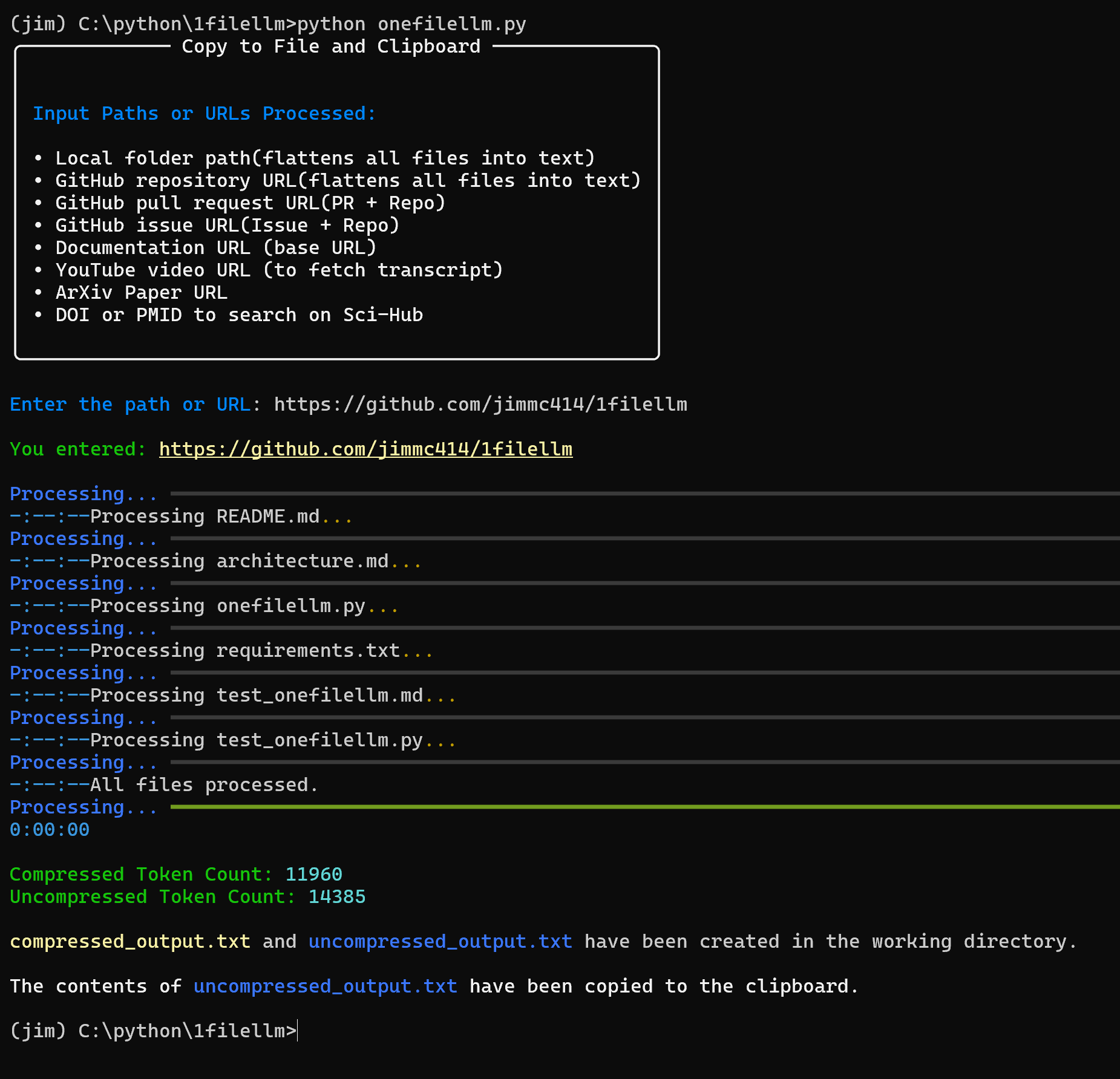
OneFileLLM: Integration mehrerer Datenquellen in eine einzige Textdatei
Umfassende Einführung OneFileLLM ist ein Open-Source-Befehlszeilen-Tool, das entwickelt wurde, um mehrere Datenquellen in einer einzigen Textdatei für die einfache Eingabe in Large Language Models (LLMs) zu konsolidieren. Es unterstützt die Verarbeitung von GitHub-Repositories, ArXiv-Papers, YouTube-Videotranskriptionen,...