Crawl4LLM: Ein effizientes Web Crawling Tool für LLM Pre-Training
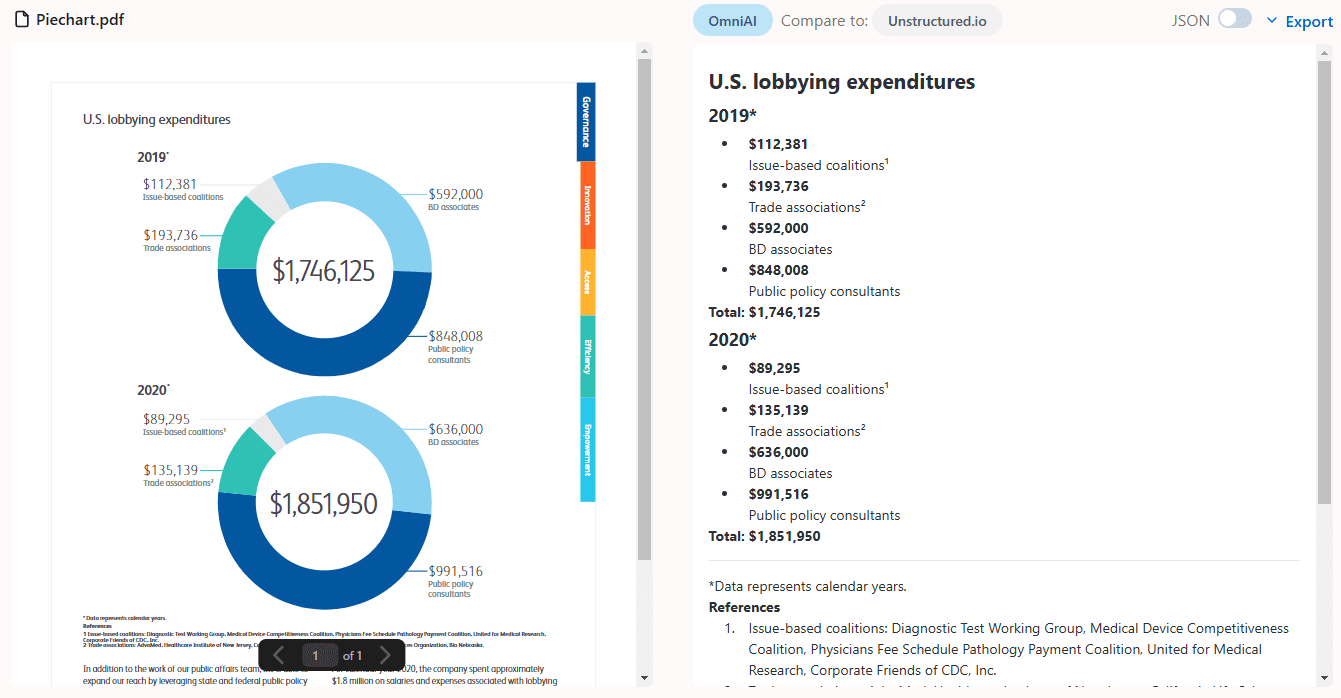
Umfassende Einführung Crawl4LLM ist ein Open-Source-Projekt, das gemeinsam von der Tsinghua University und der Carnegie Mellon University entwickelt wurde und sich auf die Optimierung der Effizienz des Web-Crawlings für das Pre-Training von großen Modellen (LLM) konzentriert. Es reduziert ineffektives Crawling durch intelligente Auswahl qualitativ hochwertiger Webdaten erheblich und behauptet, ursprünglich 1...