
dots.ocr是什么
dots.ocr是小红书hi lab开源的多语言文档解析模型,基于17亿参数的视觉语言模型(VLM),能高效地进行文档布局检测和内容识别,同时保持良好的阅读顺序。dots.ocr支持多种语言,能解析文本、表格、公式和图片等元素,推理速度快,性能在业界处于领先水平。通过简单的输入提示词切换,模型能灵活应对不同的文档解析任务,输出格式多样,包括JSON和Markdown等。dots.ocr在小语种解析和公式识别方面表现出色,适用学术研究、金融文档处理、教育资料解析等多种场景。
dots.ocr的主要功能
- 多语言支持与多样化内容解析:dots.ocr 能处理多种语言的文档,并精准解析其中的文本、表格、公式和图片等元素,满足不同场景下的内容提取需求。
- 统一的布局与内容处理:模型将文档的布局检测和内容识别整合于一体,能自动识别不同区域并保持合理的阅读顺序,避免传统方法中布局与内容分离的问题。
- 高效推理与大规模处理能力:基于 17 亿参数的视觉语言模型,模型推理速度快,适合大规模文档处理,能高效应对大量文档的解析需求。
- 灵活的任务切换:基于简单的输入提示词,轻松切换不同任务,如布局检测、内容识别、公式解析等,无需复杂的模型调整。
- 多样化的输出格式:支持 JSON、Markdown 等多种输出格式,提供布局可视化图像,方便用户根据需求进行后续处理。
- 小语种解析优势:在小语种文档解析方面,模型表现出色,能精准处理小语种内容,满足多语言环境下的文档解析需求。
dots.ocr的官网地址
- GitHub仓库:https://github.com/rednote-hilab/dots.ocr
- HuggingFace模型库:https://huggingface.co/rednote-hilab/dots.ocr
- 在线体验Demo:https://dotsocr.xiaohongshu.com/
如何使用dots.ocr
- 访问在线体验地址:访问dots.ocr的Demo体验地址。
- 上传文档:点击“上传文件”按钮,选择需要解析的 PDF 或图片文件。
- 选择任务:根据需求选择任务,如布局检测、内容识别、公式解析或表格提取。
- 开始解析:点击“开始解析”按钮,模型将自动处理文档。
- 查看结果:解析完成后,选择不同输出格式。
- 下载或复制结果:点击“下载”或“复制”按钮,保存或使用解析结果。
dots.ocr的核心优势
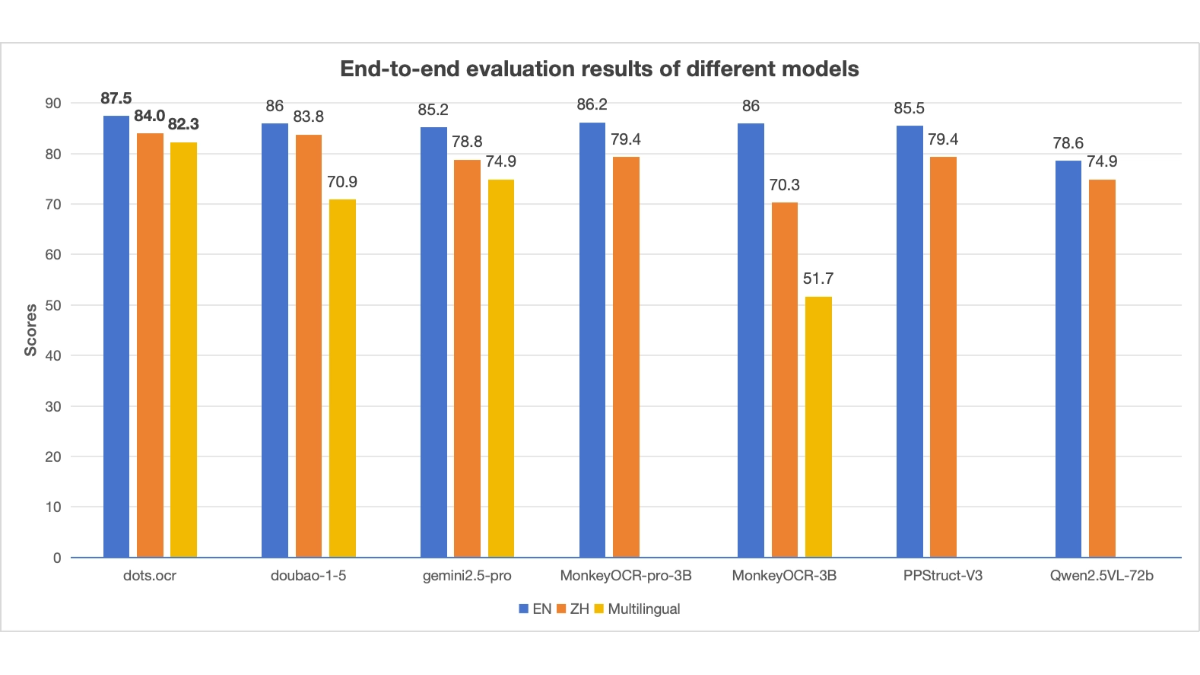
- 高性能与小模型优势:模型参数量仅为 17 亿,性能达到业界领先水平,推理速度快,资源消耗低。
- 多语言与小语种专长:支持多种主流语言,且在小语种文档解析上表现卓越,适用范围广。
- 灵活的任务适应性:通过简单的输入提示词即可切换不同任务,无需重新训练或调整模型架构,适应性强。
- 统一的布局与内容处理:将布局检测和内容识别整合到一个模型中,避免传统方法中布局与内容分离的问题,确保解析结果的连贯性。
- 多样化的输出与可视化:支持多种输出格式,并提供布局可视化图像,方便用户直观理解和后续处理。
- 开源与社区支持:开源代码和详细的文档支持,方便开发者进行二次开发和定制,社区活跃度高。
dots.ocr的适用人群
- 研究人员与学者:dots.ocr 能快速解析学术文献中的公式和图表,助力研究人员高效获取关键信息,加速学术研究。
- 金融行业从业者:金融分析师和合规人员自动提取财务报告中的数据和表格,提升金融数据分析和合规检查的效率。
- 教育工作者与学生:教师和学生用 dots.ocr 解析教材和试卷,辅助教学和学习,推动教育信息化。
- 企业内部文档管理人员:企业行政人员和项目经理处理会议记录和项目报告,提取关键信息,优化文档管理流程。
- 开发人员与技术团队:开发人员将模型集成到应用程序中,实现文档解析功能,满足多样化开发需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章


暂无评论...