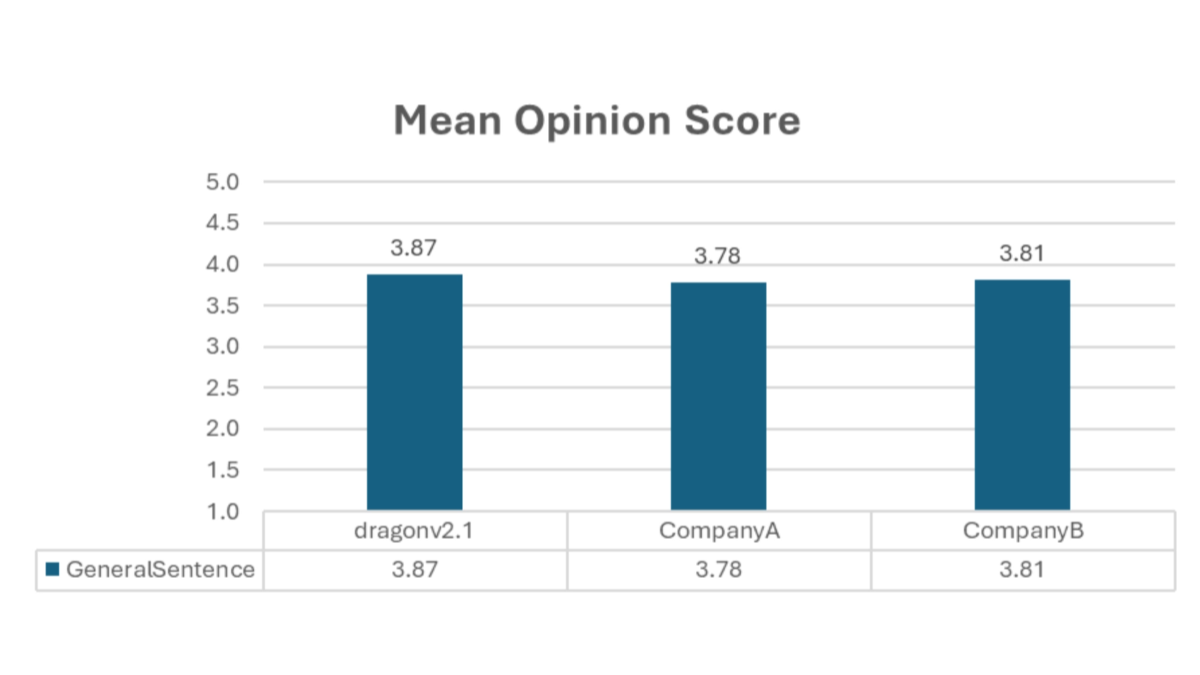
DragonV2.1是什么
DragonV2.1 是微软推出的先进的零样本文本到语音(TTS)模型。模型基于 Transformer 架构,支持多语言和零样本语音克隆,仅需 5-90 秒的语音提示能生成自然、富有表现力的语音。模型在发音准确性、语音自然度和可控性方面进行显著改进,支持 SSML 音素标签和自定义词典,能精确控制发音和口音。模型集成水印技术,确保语音合成的合规性和安全性。DragonV2.1 能广泛应用在视频内容创作、智能客服、教育与培训、智能助手及企业品牌推广等多个领域,为用户提供高效、个性化的语音合成解决方案。
DragonV2.1的主要功能
- 获取语音样本:准备一段 5-90 秒的语音提示,用在生成个性化的语音副本。
- 选择语言和口音:根据需求选择支持的语言和特定口音(如英式英语、美式英语等)。
- 使用 SSML 控制发音:基于 SSML 标签和自定义词典,精确控制语音的发音、语调和节奏。
- 生成语音:将文本输入模型,模型根据设置生成自然、富有表现力的语音。
- 应用水印技术:确保生成的语音内容带有水印,防止滥用。
DragonV2.1的官网地址
- 项目官网:https://techcommunity.microsoft.com/blog/azure-ai-services-blog/personal-voice-upgraded-to-v2-1-in-azure-ai-speech-more-expressive-than-ever-bef/4435233
如何使用DragonV2.1
获取模型
- 获取模型:模型在 2025 年 8 月中旬,通过 Azure AI Speech Service 的
BaseModels_List操作查找并获取模型名称DragonV2.1Neural。 - 准备语音样本:录制一段 5-90 秒的清晰语音样本,用在生成个性化的语音副本,将其上传到 Azure 存储或其他支持的存储服务中。
- 配置语音克隆:登录 Azure AI Speech 服务,选择 DragonV2.1 的语音克隆功能,上传语音样本并设置语言和口音等参数。
- 编写 SSML 文件:用 SSML(语音合成标记语言)编写文件,用来精确控制语音的发音、语调和节奏,并上传到语音服务中。
- 生成语音:通过 Azure AI Speech 服务的 API 或 Azure 门户调用 DragonV2.1 模型,输入文本或 SSML 文件,生成语音,并检查生成结果。
DragonV2.1的核心优势
- 低门槛个性化语音生成:仅需极短语音样本即可生成个性化语音,极大地降低语音克隆的技术门槛,让更多用户能轻松获得专属语音。
- 高效率实时交互:具备超低延迟和高实时性,能快速生成语音,满足实时交互场景的需求,如智能客服和直播等。
- 高质量语音输出:基于先进的 Transformer 架构,生成的语音自然流畅,显著提升语音合成的整体质量,为用户带来更佳的听觉体验。
- 灵活的语音定制:用户根据具体需求进行高度定制化,满足多样化的应用场景。
- 强大的语言适应性:根据上下文自动调整情感和口音,适应不同语言环境下的语音合成需求。
- 语音合成的安全性:有效防止语音合成内容的滥用,为语音合成的合规性和安全性提供保障。
DragonV2.1的适用人群
- 内容创作者:视频制作者和音频内容创作者为作品添加个性化配音,提升内容吸引力。
- 企业与品牌:企业快速创建品牌专属语音形象,用在广告和客服,增强品牌识别度。
- 教育机构与教师:教育领域帮助学生练习发音和听力,提升教学效果。
- 技术开发者:开发者将自然语音交互功能集成到智能助手、智能家居等应用中,提升用户体验。
- 个人用户:个人用户,尤其是语言学习者,通过高质量语音合成练习发音,提升语言能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...