DragonV2.1 - Zero-Sample Speech Synthesis Model from Microsoft
What is DragonV2.1?
DragonV2.1 is an advanced zero-sample text-to-speech (TTS) model from Microsoft. The model is based on Transformer The architecture supports multi-language and zero-sample speech cloning, generating natural, expressive speech in just 5-90 seconds of voice prompts. The model offers significant improvements in pronunciation accuracy, naturalness and control, with support for SSML phoneme tags and custom dictionaries for precise control of pronunciation and accent. The model integrates watermarking technology to ensure the compliance and security of speech synthesis. DragonV2.1 can be widely used in a variety of fields such as video content creation, intelligent customer service, education and training, intelligent assistants, and enterprise branding, providing users with efficient and personalized speech synthesis solutions.
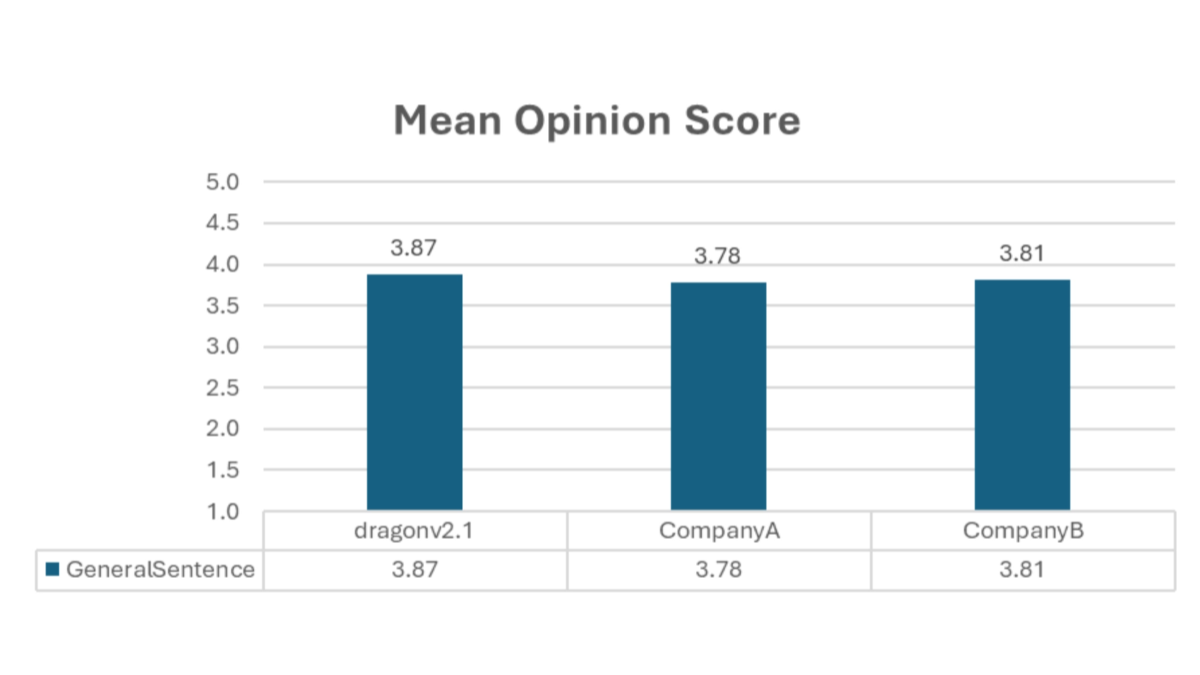
Key Features of DragonV2.1
- Getting voice samples: Prepare a 5-90 second voice prompt to be used in generating personalized voice copy.
- Select language and accent: Select supported languages and specific accents (e.g. British English, American English, etc.) on demand.
- Controlling Pronunciation with SSML: Precise control over pronunciation, intonation and rhythm of speech based on SSML tags and customized dictionaries.
- Generate Speech: The text is fed into the model, which generates natural, expressive speech based on the settings.
- Applied watermarking techniques: Ensure that generated voice content is watermarked to prevent misuse.
DragonV2.1 official website address
- Project website: https://techcommunity.microsoft.com/blog/azure-ai-services-blog/personal-voice-upgraded-to-v2-1-in-azure-ai-speech-more- expressive-than-ever-bef/4435233
How to use DragonV2.1
Getting the model
- Getting the model: Modeled in mid-August 2025, through the Azure AI Speech Service's
BaseModels_ListOperation Find and Get Model NameDragonV2.1NeuralThe - Preparing voice samples: Record a clear 5-90 second voice sample that can be used to generate a personalized copy of your voice for uploading to Azure Storage or other supported storage services.
- Configuring Voice Cloning: Log in to the Azure AI Speech service, select the DragonV2.1 voice cloning feature, upload voice samples and set parameters such as language and accent.
- Preparation of SSML documents: Files are written in SSML (Speech Synthesis Markup Language), which are used to accurately control the articulation, intonation, and rhythm of speech, and uploaded to the speech service.
- Generate Speech: Invoke the DragonV2.1 model via the Azure AI Speech service's API or the Azure portal, enter text or SSML files, generate speech, and check the generation results.
Core Benefits of DragonV2.1
- Low-threshold personalized speech generation: Only very short voice samples are needed to generate personalized voice, which greatly reduces the technical threshold of voice cloning and allows more users to easily obtain exclusive voice.
- Highly efficient real-time interactions: With ultra-low latency and high real-time, it can quickly generate speech to meet the needs of real-time interaction scenarios, such as intelligent customer service and live broadcasting.
- High quality voice outputThe newest addition to the Transformer architecture is a new generation of natural and smooth speech, which significantly improves the overall quality of speech synthesis and provides users with a better listening experience.
- Flexible voice customization: Users are highly customized to meet diverse application scenarios based on specific needs.
- Powerful language adaptability: Automatically adjusts emotion and accent according to context, adapting to the needs of speech synthesis in different language environments.
- Security in Speech Synthesis: Effectively prevents the misuse of speech synthesized content and provides guarantees for speech synthesis compliance and security.
Who can use DragonV2.1?
- content creator: Video producers and audio content creators add personalized voiceovers to their work to enhance the appeal of their content.
- Companies & Brands: Enterprises quickly create brand-specific voice images to use in advertising and customer service to enhance brand recognition.
- Educational institutions and teachers: The field of education helps students to practice pronunciation and listening to improve teaching and learning.
- Technology Developer: Developers integrate natural voice interaction features into smart assistants, smart homes and other applications to enhance user experience.
- individual user: Individual users, especially language learners, practice pronunciation and improve their language skills through high-quality speech synthesis.
© Copyright notes
The article is copyrighted and should not be reproduced without permission.

Related posts

No comments...