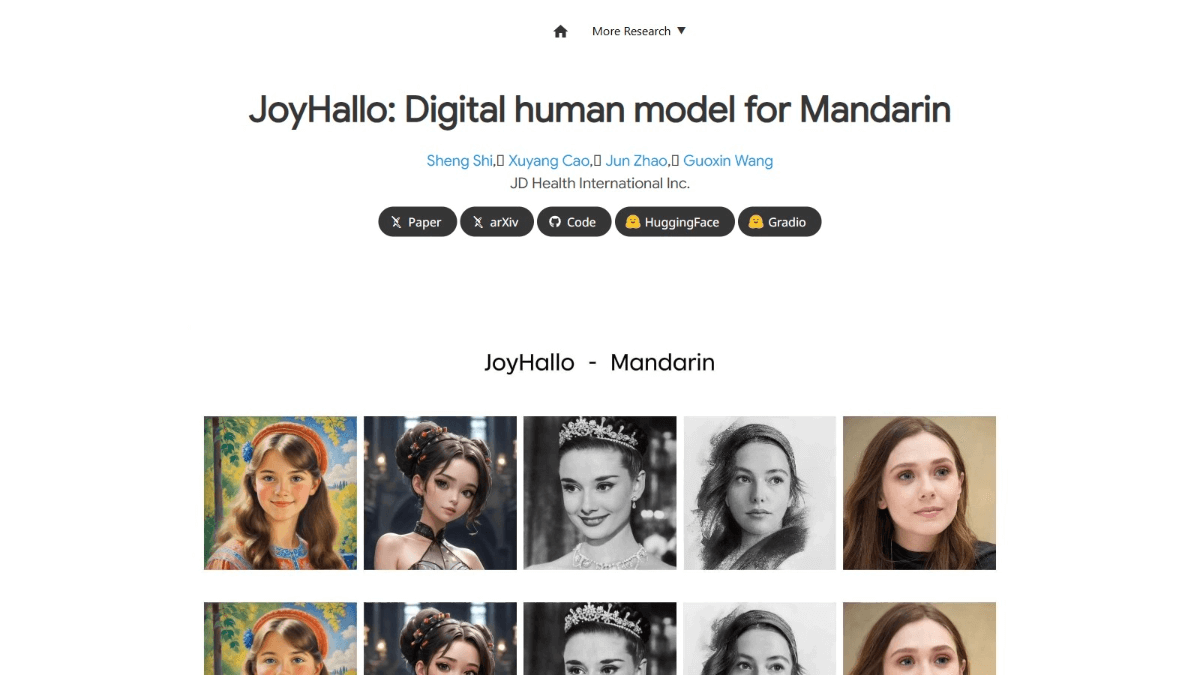
JoyHallo - Jingdong's open source AI digital human model
What's JoyHallo?
JoyHallo is an open source AI digital human model from Jingdong, designed for Mandarin, supporting the conversion of audio into realistic speaking videos.JoyHallo embeds audio features based on the wav2vec2 model with a semi-decoupled structure to improve lip movement prediction accuracy and support the generation of English videos.JoyHallo training dataset covers Mandarin videos of multiple ages and styles. JoyHallo has a wide range of applications in the fields of virtual anchor, online education, customer service and advertisement production, which can provide efficient, vivid and personalized service experience and promote the intelligent development of related industries.
Key Features of JoyHallo
- Audio-driven video generation: Based on the incoming audio signal, automatically generates a talking video that matches it.
- Cross-language generation capabilities: In addition to specializing in Mandarin video generation, JoyHallo has the ability to generate English speaking videos.
- Lip Synchronization: The model accurately synchronizes lip movements in audio and video.
- Facial expression generation: Generate appropriate facial expressions based on the emotion and tone of voice in the audio.
JoyHallo's official website address
- Project website::https://jdh-algo.github.io/JoyHallo/
- GitHub repository::https://github.com/jdh-algo/JoyHallo
- HuggingFace Model Library::https://huggingface.co/jdh-algo/JoyHallo-v1
- arXiv Technical Paper::https://arxiv.org/pdf/2409.13268
How to use JoyHallo
- environmental preparation::
- hardware requirement: It is recommended that computers with high performance GPUs, such as NVIDIA series graphics cards (e.g., RTX 30 series or higher), be used to accelerate the inference process of the model.
- software environment: Ensure that Python is installed on your system (recommended version 3.8 and above). Install PyTorch based on the following command (choose the appropriate installation command based on the CUDA version):
pip install torch torchvision torchaudio- Installation of dependencies::
- Cloning of JoyHallo's GitHub repository::
git clone https://github.com/jdh-algo/JoyHallo.git
cd JoyHallo- Install project dependencies::
pip install -r requirements.txt- Data preparation: If training or fine-tuning with your own data, you need to prepare the data according to JoyHallo's data format.JoyHallo's dataset usually contains audio files and corresponding video files. The audio files need to be in wav format and the video files need to be in mp4 format. If you are just using the pre-trained model for inference, skip this step directly.
- Model Loading and Inference::
- Loading pre-trained models: JoyHallo's pre-trained models are loaded based on the Hugging Face model library.
from transformers import AutoModelForAudioToVideo, AutoProcessor
model_name = "jdh-algo/JoyHallo-v1"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForAudioToVideo.from_pretrained(model_name)- Audio pre-processing: converts audio files to the format required by the model::
from datasets import load_dataset
dataset = load_dataset("audiofolder", data_dir="path/to/your/audio/files")
inputs = processor(dataset[0]["audio"], return_tensors="pt")- Generate Video: Reasoning with models to generate videos:
outputs = model(**inputs)
video = processor.postprocess_video(outputs)
video.save("output_video.mp4")JoyHallo's core strengths
- Mandarin optimization: JoyHallo is designed for Mandarin and can accurately match lip movements to accurately simulate the complex consonant and rhyme sounds in Mandarin, such as "zh", "ch", "sh zh", "ch", "sh", etc. It supports generating rich facial expressions based on the emotions and intonations in the audio, making the video more infectious.
- cross-language competenceJoyHallo has the ability to generate English videos in addition to Mandarin, supporting multilingual application scenarios such as customer service for multinational corporations, international education, and so on, with a wide range of applicability.
- Efficient structures: Based on a semi-decoupled structure, the audio feature embedding and video generation processes are separated to significantly improve the inference speed, which is 14.31 TP3T faster than the traditional fully coupled model.
- Rich application scenarios: JoyHallo is applicable to a variety of industries and scenarios, including virtual anchor (news broadcast, weather forecast, sports event commentary), online education (language learning, online courses), customer service (virtual customer service representative) and other scenarios.
- open source resource: Provide an open source dataset (jdh-Hallo dataset) containing Mandarin video datasets of multiple ages and speaking styles, covering everyday conversations and specialized medical topics. The project provides detailed model training methods and code to facilitate developers' customization and optimization.
Who JoyHallo is for
- content creator: Video producers and social media mavens quickly generate high-quality, personalized video content, saving time and costs and increasing content appeal.
- educator: Generate virtual teacher images for online education platforms, schools and training institutions to enrich teaching resources and provide a vivid teaching experience.
- Companies & Brands: Corporate customer service departments generate virtual customer service representatives to enhance service satisfaction; marketing teams create personalized advertising videos to enhance advertising appeal.
- Entertainment industry practitioners: Film and TV production companies and game development companies to generate character facial animation, improve production efficiency, reduce production costs, and enhance the immersion and realism of the work.
- Researchers and Developers: Artificial intelligence researchers and software developers conduct research and development to promote technological advances and expand application scenarios.
© Copyright notes
The article is copyrighted and should not be reproduced without permission.

Related articles


No comments...