GraphGen: Fine-tuning Language Models Using Knowledge Graphs to Generate Synthetic Data
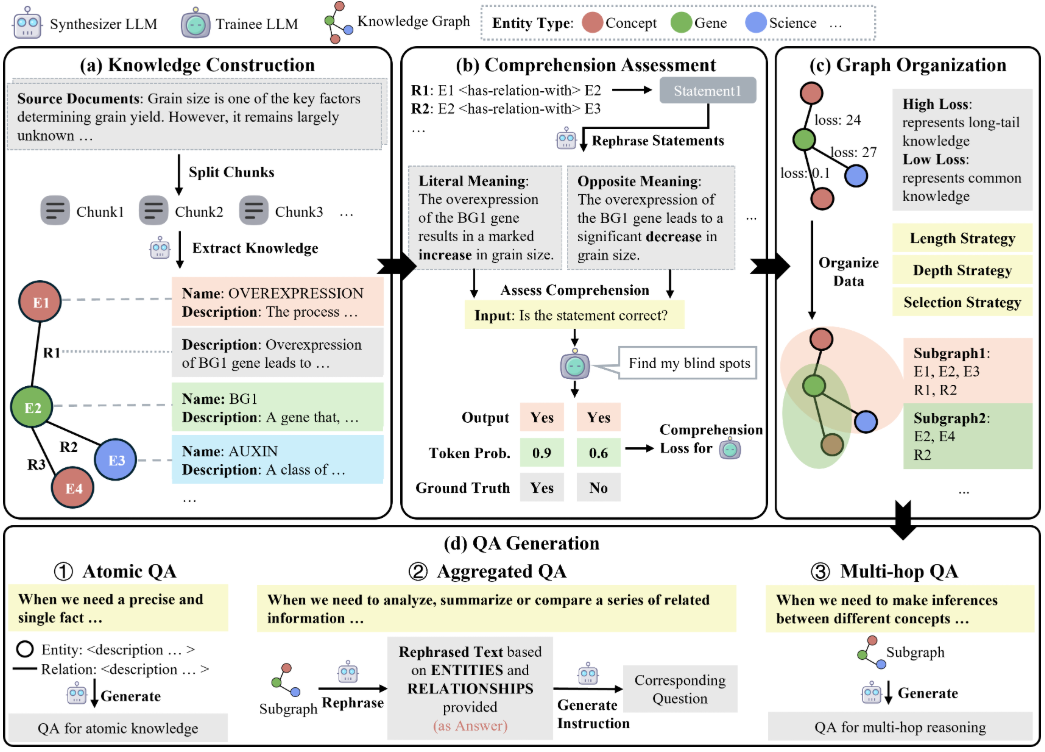
Comprehensive Introduction GraphGen is an open source framework developed by OpenScienceLab, an AI lab in Shanghai, hosted on GitHub, focused on optimizing supervised fine-tuning of Large Language Models (LLMs) by guiding synthetic data generation through knowledge graphs. It was developed from ...