
Guía para evitar las trampas: ¿Paquete de instalación de Taobao DeepSeek R1 upsell de pago? Le enseñamos la instalación local gratuita (con el instalador de un solo clic)

Recientemente, en la plataforma Taobao DeepSeek El fenómeno de la venta de paquetes de instalación ha suscitado una preocupación generalizada. Resulta sorprendente que algunas empresas se estén beneficiando de este modelo de IA gratuito y de código abierto. Esto también es un reflejo del auge del despliegue local que están generando los modelos de DeepSeek.

Buscando "DeepSeek" en plataformas de comercio electrónico como Taobao y Jinduoduo, se pueden encontrar muchos comerciantes que venden recursos que podrían haberse obtenido de forma gratuita, incluyendo paquetes de instalación, paquetes de palabras clave, tutoriales, etc. Incluso algunos vendedores han marcado tutoriales relacionados con DeepSeek para la venta. Algunos vendedores incluso venden tutoriales relacionados con DeepSeek a un precio marcado, pero en realidad, los usuarios pueden encontrar fácilmente un gran número de enlaces de descarga gratuita simplemente utilizando un motor de búsqueda.

Entonces, ¿a cuánto se venden estos recursos? Se ha observado que el precio del paquete de "instalador + tutoriales + consejos" por lo general oscila entre $ 10 a $ 30, y la mayoría de los comerciantes también proporcionan un cierto grado de soporte de servicio al cliente. Entre ellos, muchos de los bienes se han vendido cientos de copias, unos pocos bienes populares e incluso достигают mil personas a pagar la escala. Más sorprendentemente, un precio de $ 100 paquetes de software y tutoriales, sino también 22 personas optan por comprar.

Las oportunidades de negocio que presenta el vacío de información son, pues, evidentes.
En este artículo, explicaremos al lector cómo desplegar modelos DeepSeek localmente sin coste alguno. Antes, analizaremos brevemente la necesidad del despliegue local.
¿Por qué desplegar DeepSeek-R1 localmente?
DeepSeek-R1 aunque puede que no sean los modelos de inferencia de mayor rendimiento disponibles en la actualidad, son sin duda una opción muy solicitada en el mercado. Sin embargo, cuando se utilizan directamente los servicios de plataformas de alojamiento oficiales o de terceros, los usuarios suelen experimentar congestiones en los servidores.
Un modelo de despliegue local puede sortear eficazmente este problema. En pocas palabras, el despliegue local significa instalar modelos de IA en los propios dispositivos de los usuarios, en lugar de depender de API en la nube o servicios en línea. Entre los métodos habituales de despliegue local se incluyen los siguientes:
- Razonamiento local ligero: Se ejecuta en un PC o en un dispositivo móvil, por ejemplo, en los modelos Llama.cpp, Whisper, formato GGUF.
- Despliegue de servidores y estaciones de trabajoEjecuta modelos de gran tamaño con GPUs o TPUs de alto rendimiento, como las NVIDIA RTX 4090, A100, etc.
- Servidores privados de nube/intranetDespliegue en servidores locales, por ejemplo, utilizando herramientas como TensorRT, ONNX Runtime, vLLM.
- Despliegue de dispositivos periféricosEjecuta modelos de IA en sistemas integrados o dispositivos IoT, como Jetson Nano, Raspberry Pi, etc.
Los distintos métodos de despliegue son adecuados para diferentes escenarios de aplicación. Las tecnologías desplegadas localmente han demostrado su valor único en varios ámbitos, por ejemplo:
- Aplicaciones de IA locales: Construya chatbots privados, sistemas de análisis de documentos, etc.
- cálculos de investigación científicaAplicaciones en análisis de datos y formación de modelos en biomedicina, simulación física y otros campos.
- Funciones de IA sin conexión: Ofrece funciones de reconocimiento de voz, OCR y procesamiento de imágenes en un entorno sin red.
- Auditoría y supervisión de la seguridadFunciones: Ayudar en los análisis de conformidad en los sectores jurídico, financiero y otros.
En este artículo, nos centraremos en la inferencia local ligera, que es la opción de despliegue más relevante para una amplia gama de usuarios individuales.
Ventajas de la implantación local
Además de resolver el problema de raíz del "servidor ocupado", la implantación local ofrece una serie de ventajas:
- Privacidad y seguridad de los datosLa implementación local de modelos de IA elimina la necesidad de subir datos confidenciales a la nube, lo que evita el riesgo de fuga de datos. Esto es fundamental para sectores como el financiero, el sanitario y el jurídico, que requieren altos niveles de seguridad de los datos. Además, el despliegue local también ayuda a las empresas u organizaciones a cumplir los requisitos de conformidad de datos, como la Ley de Seguridad de Datos de China y el GDPR de la UE.
- Baja latencia y rendimiento en tiempo realLa velocidad de inferencia depende totalmente de las prestaciones de cálculo del dispositivo local. Por tanto, siempre que el rendimiento del dispositivo sea suficiente, los usuarios pueden obtener una excelente respuesta en tiempo real, lo que hace que la implantación local sea ideal para escenarios de aplicaciones exigentes en tiempo real, como el reconocimiento de voz, la conducción automatizada y la inspección industrial.
- Rentabilidad a largo plazoDespliegue nativo: el despliegue nativo elimina las cuotas de suscripción a la API, lo que permite un despliegue único y un uso a largo plazo. En el caso de las aplicaciones con requisitos de rendimiento bajos, los costes de hardware también pueden reducirse desplegando modelos ligeros, como los modelos cuantificados INT de 8 o 4 bits.
- Disponibilidad fuera de líneaLos modelos de IA pueden utilizarse incluso cuando no hay conexión a la red, lo que resulta adecuado para edge computing, oficinas offline, entornos remotos y otros escenarios. La capacidad de funcionar sin conexión también garantiza la continuidad de los servicios críticos y evita las interrupciones del negocio debidas a la desconexión de la red.
- Altamente personalizable y controlableLa implantación local permite a los usuarios ajustar y optimizar el modelo para adaptarlo mejor a las necesidades específicas de su empresa. Por ejemplo, el modelo DeepSeek-R1 ha dado lugar a numerosas versiones perfeccionadas y destiladas, incluida la versión sin restricciones deepseek-r1-abliterated. Además, las implantaciones locales no están sujetas a cambios en las políticas de terceros, lo que proporciona un mayor control y evita riesgos potenciales como ajustes en el precio de la API o restricciones de acceso.
Limitaciones de la implantación local
Las ventajas de la implantación local son significativas, pero no se pueden ignorar sus limitaciones, entre las que destaca la potencia de cálculo necesaria para los modelos a gran escala.
- Costes de hardwareLos usuarios individuales a menudo tienen dificultades para ejecutar modelos con parámetros de gran tamaño sin problemas en sus equipos locales, mientras que los modelos con parámetros más pequeños pueden comprometer el rendimiento. Por lo tanto, los usuarios tienen que elegir entre el coste del hardware y el rendimiento del modelo. La búsqueda de modelos de alto rendimiento requerirá inevitablemente una inversión adicional en hardware.
- Capacidad de procesamiento de tareas a gran escalaEl objetivo: cuando nos enfrentamos a tareas que requieren un procesamiento de datos a gran escala, a menudo es necesario un soporte de hardware a nivel de servidor para llevarlas a cabo con eficacia. Los dispositivos personales tienen un cuello de botella natural en cuanto a potencia de procesamiento.
- umbral tecnológicoEl despliegue local: frente a la comodidad de los servicios en la nube, que pueden utilizarse simplemente visitando una página web o configurando una API, existe una barrera técnica para el despliegue local. Si los usuarios necesitan ajustar aún más sus modelos, la implantación será aún más difícil. Afortunadamente, las barreras técnicas a la implantación local se están reduciendo gradualmente.
- coste de mantenimientoEl usuario: Las actualizaciones e iteraciones del modelo y las herramientas asociadas pueden causar problemas con la configuración del entorno, lo que requiere que el usuario invierta tiempo y esfuerzo en el mantenimiento y la resolución de problemas.
Por lo tanto, la elección del despliegue local o del modelo en línea debe considerarse en función de la situación real del usuario. A continuación se resumen brevemente los escenarios en los que es y no es aplicable el despliegue local:
- Escenarios adecuados para la implantación localAltos requisitos de privacidad, bajos requisitos de latencia, uso a largo plazo (por ejemplo, asistentes de IA para empresas, sistemas de análisis jurídico, etc.).
- Escenarios no adecuados para el despliegue localValidación de pruebas a corto plazo, altos requisitos aritméticos, dependencia de modelos muy grandes (por ejemplo, nivel de parámetros 70B+).
El despliegue privado utilizando servidores gratuitos en la nube también es un buen camino, recomendado hace tiempo, pero requiere una cierta base técnica:Implantación en línea del modelo de código abierto DeepSeek-R1 con potencia de GPU gratuita
Despliegue local de DeepSeek-R1 en acción
Hay muchas formas de desplegar DeepSeek-R1 localmente, pero en este artículo vamos a presentar dos opciones sencillas: basadas en el método Ollama métodos de despliegue y escenarios de despliegue de código cero mediante LM Studio.
Opción 1: despliegue de DeepSeek-R1 basado en Ollama
Ollama es el marco dominante para desplegar y ejecutar modelos lingüísticos nativos. Es ligero y altamente escalable, y ha cobrado importancia desde el lanzamiento de la familia de modelos Llama de Meta. A pesar de su nombre, el proyecto Ollama está impulsado por la comunidad y no está directamente relacionado con el desarrollo de Meta y la familia de modelos Llama.

El proyecto Ollama está creciendo rápidamente, y la variedad de modelos y ecosistemas que soporta se amplía con rapidez.
Algunos de los modelos y ecologías apoyados por Ollama
El primer paso para utilizar Ollama es descargar e instalar el software de Ollama. Visite la página oficial de descargas de Ollama y seleccione la versión que coincida con su sistema operativo.
Descargar: https://ollama.com/download
Después de instalar Ollama, es necesario configurar el modelo de IA para el dispositivo. Tomemos como ejemplo DeepSeek-R1. Visite la biblioteca de modelos en el sitio web de Ollama para examinar los modelos y versiones compatibles:
https://ollama.com/search
DeepSeek-R1 está disponible en 29 versiones diferentes de la biblioteca de modelos Ollama en escalas que van de 1,5B a 67B, incluidas versiones afinadas, destiladas o cuantificadas basadas en los modelos de código abierto Llama y Qwen.

La versión a elegir depende de la configuración de hardware del usuario. Avnish, de la comunidad de desarrolladores dev.to, ha escrito un artículo en el que resume los requisitos de hardware para las versiones de DeepSeek-R1 de distintos tamaños:
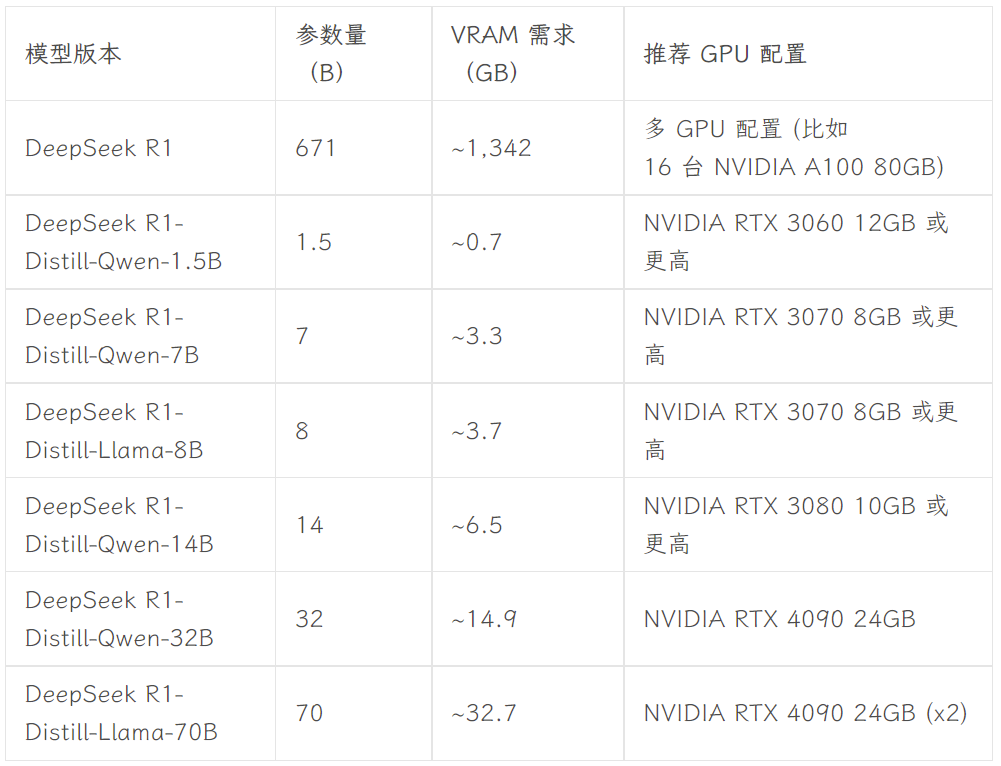
Fuente de la imagen: https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
Este artículo toma la versión 8B como ejemplo para la demostración. Abra el terminal del dispositivo y ejecute el siguiente comando:
ollama run deepseek-r1:8b
A continuación, espere a que el modelo termine de descargarse. (Ollama también admite la descarga de modelos directamente desde Hugging Face, con el comando ollama run hf.co/{username}/{library}:{quantified version}, por ejemplo, ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0).
Una vez descargado el modelo, puede hablar con la versión 8B de DeepSeek-R1 en el terminal.

Sin embargo, este tipo de diálogo terminal no es intuitivo ni cómodo para el usuario medio. Por lo tanto, se necesita una interfaz gráfica de fácil uso. Existe una amplia gama de front-ends entre los que elegir, como el Abrir WebUI Conseguir algo como ChatGPT También puede optar por Chatbox y otras aplicaciones de escritorio. Puede encontrar más opciones de front-end en la documentación oficial de Ollama:
https://github.com/ollama/ollama
- Abrir WebUI
Si eliges Abrir WebUI, simplemente ejecuta las siguientes dos líneas de código en el terminal:
Instalar Open WebUI:
pip install open-webui
Ejecuta el servicio Open WebUI:
open-webui serve
Después de eso, visite http://localhost:8080 en su navegador para experimentar la interfaz web similar a ChatGPT. En la lista de modelos en Open WebUI, puede ver varios modelos que han sido configurados por la Ollama local, incluyendo las versiones DeepSeek-R1 7B y 8B, así como otros modelos como Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder y así sucesivamente. El modelo DeepSeek-R1 8B es el elegido para las pruebas:

- Chatbox
Si prefieres utilizar una aplicación de escritorio independiente, puedes considerar herramientas como Chatbox. Los pasos de configuración son igualmente sencillos, empezando por descargar e instalar la aplicación Chatbox:
https://chatboxai.app/zh
Después de lanzar Chatbox, entre en la interfaz "Settings", seleccione OLLAMA API en "Model Provider", y luego seleccione el modelo que desea utilizar en la columna "Model". A continuación, seleccione el modelo que desea utilizar en el campo "Modelo", y configure los parámetros como el número máximo de mensajes contextuales y la Temperatura según sus necesidades (también puede mantener la configuración por defecto).

Una vez configurado, se puede mantener una conversación fluida con el modelo DeepSeek-R1 desplegado localmente en Chatbox. Sin embargo, los resultados de las pruebas muestran que el modelo DeepSeek-R1 7B tiene un rendimiento ligeramente inferior al procesar comandos complejos. Esto confirma el punto anterior de que los usuarios individuales normalmente sólo pueden ejecutar modelos con un rendimiento relativamente limitado en dispositivos locales. Sin embargo, es previsible que, a medida que la tecnología de hardware siga evolucionando, las barreras al uso local de modelos de grandes parámetros para usuarios individuales se reduzcan aún más en el futuro, y puede que ese día no esté demasiado lejos.

**Tanto Open WebUI como Chatbox admiten el acceso a los modelos de DeepSeek, ChatGPT y Claude a través de API, Géminis y otros modelos de negocio. Los usuarios pueden utilizarlos como interfaz front-end para el uso cotidiano de las herramientas de IA. Además, los modelos configurados en Ollama pueden integrarse en otras herramientas, como aplicaciones de toma de notas como Obsidian y Civic Notes.
Opción 2: Despliegue DeepSeek-R1 sin código utilizando LM Studio
Los usuarios que no estén familiarizados con el funcionamiento de la línea de comandos o con el código pueden utilizar LM Studio para implantar DeepSeek-R1 sin código. En primer lugar, visite la página oficial de descargas de LM Studio para descargar el programa que se adapte a su sistema operativo:
https://lmstudio.ai
Una vez finalizada la instalación, inicie LM Studio. En la pestaña "Mis modelos", defina la carpeta de almacenamiento local de los modelos:
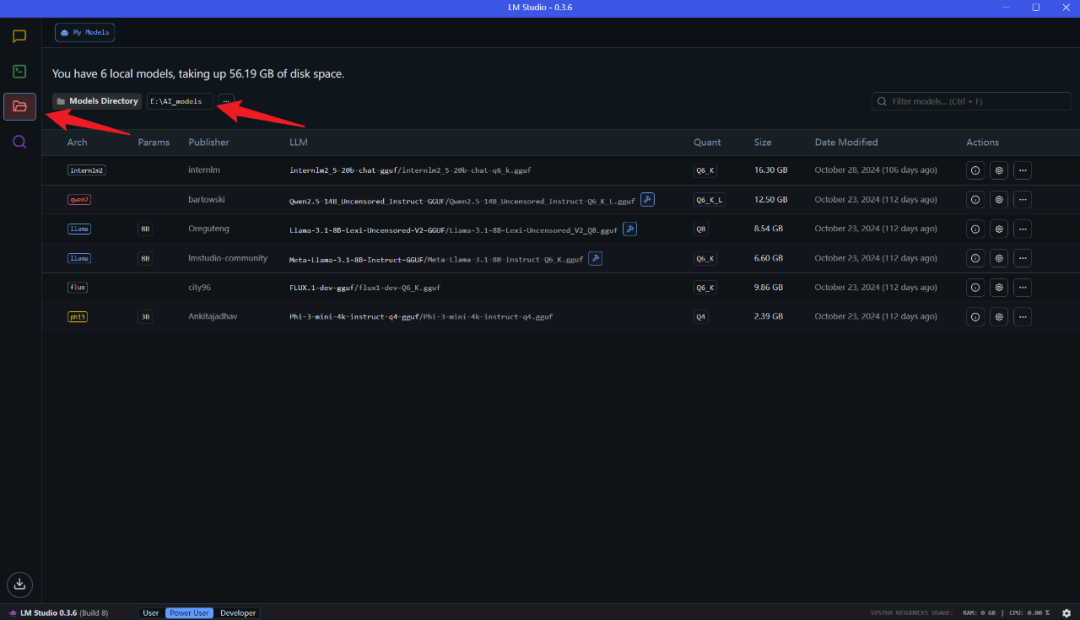
A continuación, descargue de Hugging Face los archivos de modelo de idioma necesarios y colóquelos en la carpeta anterior según la estructura de directorios especificada (LM Studio tiene una función de búsqueda de modelos incorporada, pero no funciona bien en la práctica). Tenga en cuenta que debe descargar los archivos de modelo en formato .gguf. Por ejemplo Desenredar Una colección de modelos DeepSeek-R1 proporcionados por la organización:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
Teniendo en cuenta la configuración del hardware, en este trabajo elegimos la versión DeepSeek-R1 Distillate (número de parámetro 14B) basada en el ajuste fino del modelo Qwen, y la versión cuantificada de 4 bits: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf.
Una vez finalizada la descarga, coloque los archivos del modelo en la carpeta establecida previamente de acuerdo con la siguiente estructura de directorios:
Carpeta modelo /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Por último, abra LM Studio y seleccione el modelo que desea cargar en la parte superior de la interfaz de la aplicación para hablar con el modelo local.

La mayor ventaja de LM Studio es que es completamente de código cero, no hay necesidad de utilizar un terminal o escribir cualquier código - sólo tiene que instalar el software y configurar las carpetas, por lo que es muy fácil de usar.
resúmenes
Los tutoriales proporcionados en este artículo sólo proporcionan un nivel básico de despliegue local de DeepSeek-R1. Para integrar este popular modelo de forma más profunda en los flujos de trabajo locales se requiere una configuración más detallada, como la configuración de avisos del sistema y un ajuste más avanzado del modelo, RAG Integración, función de búsqueda, capacidades multimodales y capacidades de invocación de herramientas. Al mismo tiempo, a medida que el hardware específico de IA y las tecnologías de modelos pequeños sigan evolucionando, creo que las barreras para desplegar grandes modelos localmente seguirán disminuyendo en el futuro. Después de leer este artículo, ¿estás dispuesto a intentar desplegar el modelo DeepSeek-R1 por tu cuenta?
Paquete adjunto de instalación en un clic de DeepSeek R1+OpenwebUI
El paquete de instalación de un solo clic proporcionado por Sword27 integra específicamente para DeepSeek el Abrir WebUI
DeepSeek despliegue local de ejecución de un solo clic, desempaquetado para usar Soporte 1.5b 7b 8b 14b 32b, soporte mínimo para tarjeta gráfica 2G
Proceso de instalación
1.Descarga del entorno AI: https://pan.quark.cn/s/1b1ad88c7244
2. Descarga del paquete de instalación: https://pan.quark.cn/s/7ec8d85b2f95
Obtenga ayuda en el artículo original: https://www.jian27.com/html/1396.html
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Artículos relacionados


Sin comentarios...