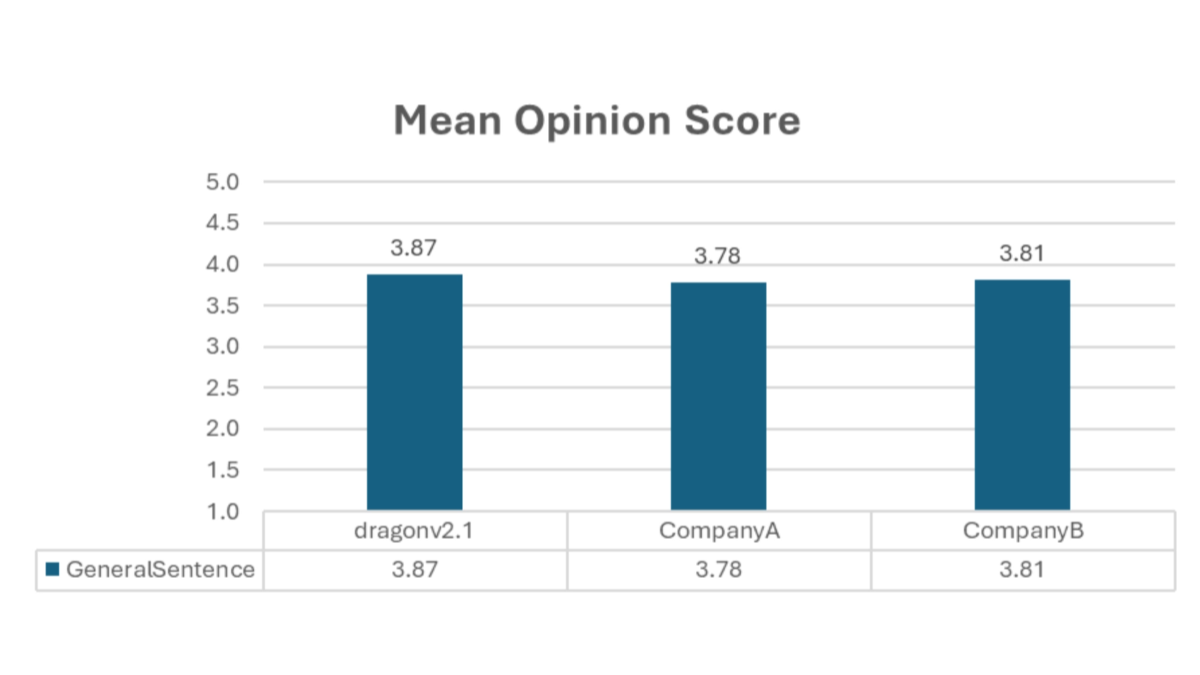
DragonV2.1 - Modelos de síntesis de voz sin muestras de Microsoft
Últimos recursos sobre IAActualizado hace 6 horas Círculo de intercambio de inteligencia artificial 447 00
¿Qué es DragonV2.1?
DragonV2.1 es un modelo avanzado de texto a voz (TTS) de muestra cero de Microsoft. El modelo se basa en Transformador La arquitectura admite la clonación del habla en varios idiomas y sin muestras, lo que genera un habla natural y expresiva en sólo 5-90 segundos de indicaciones de voz. El modelo ofrece mejoras significativas en la precisión, naturalidad y control de la articulación, y admite el etiquetado de fonemas SSML y diccionarios personalizados para un control preciso de la pronunciación y el acento. DragonV2.1 puede utilizarse ampliamente en la creación de contenidos de vídeo, el servicio inteligente de atención al cliente, la educación y la formación, los asistentes inteligentes y la creación de marcas empresariales, proporcionando a los usuarios soluciones de síntesis de voz eficaces y personalizadas.
Características principales de DragonV2.1
- Obtener muestras de vozPreparar un mensaje de voz de 5 a 90 segundos que se utilizará para generar un mensaje de voz personalizado.
- Seleccionar idioma y acento: Seleccione los idiomas admitidos y los acentos específicos (por ejemplo, inglés británico, inglés americano, etc.) según sea necesario.
- Control de la pronunciación con SSML: Control preciso de la pronunciación, la entonación y el ritmo del habla basado en etiquetas SSML y diccionarios personalizados.
- Generar discursoEl texto se introduce en el modelo, que genera un habla natural y expresiva basada en la configuración.
- Técnicas de marca de agua aplicadasGarantía de que los contenidos de voz generados llevan una marca de agua para evitar usos indebidos.
Sitio web oficial de DragonV2.1
- Página web del proyecto: https://techcommunity.microsoft.com/blog/azure-ai-services-blog/personal-voice-upgraded-to-v2-1-in-azure-ai-speech-more- expressive-than-ever-bef/4435233
Cómo utilizar DragonV2.1
Obtener el modelo
- Obtener el modeloa mediados de agosto de 2025 a través del servicio Azure AI Speech Service's
BaseModels_ListOperación Buscar y obtener nombre de modeloDragonV2.1Neural. - Preparar muestras de voz: Graba una muestra de voz clara de 5-90 segundos que puede utilizarse para generar una copia personalizada de tu voz para subirla a Azure Storage u otros servicios de almacenamiento compatibles.
- Configuración de la clonación de vozInicie sesión en el servicio Azure AI Speech, seleccione la función de clonación de voz DragonV2.1, cargue muestras de voz y establezca parámetros como el idioma y el acento.
- Redacción de documentos SSML: Los archivos se escriben en SSML (Speech Synthesis Markup Language), que se utiliza para controlar con precisión la articulación, la entonación y el ritmo del habla, y se cargan en el servicio de voz.
- Generar discursoInvocar el modelo DragonV2.1 mediante la API del servicio Azure AI Speech o el portal Azure, introducir texto o archivos SSML, generar voz y comprobar los resultados de la generación.
Principales ventajas de DragonV2.1
- Generación de voz personalizada de bajo umbralLa nueva tecnología está diseñada para generar una voz personalizada con sólo una muestra de voz muy corta, lo que reduce enormemente el umbral técnico de la clonación de voz y permite a más usuarios obtener fácilmente su propia voz.
- Interacciones en tiempo real de gran eficacia: Con una latencia ultrabaja y un tiempo real elevado, puede generar rápidamente voz para satisfacer las necesidades de los escenarios de interacción en tiempo real, como la atención al cliente inteligente y la retransmisión en directo.
- Salida de voz de alta calidadLa última incorporación a la arquitectura Transformer es una nueva generación de habla natural y suave, que mejora significativamente la calidad general de la síntesis de voz y proporciona a los usuarios una mejor experiencia auditiva.
- Personalización flexible de la voz: Altamente personalizable por los usuarios en función de sus necesidades específicas para responder a diversos escenarios de aplicación.
- Potente adaptabilidad lingüística: Ajusta automáticamente la emoción y el acento según el contexto, adaptándose a las necesidades de la síntesis de voz en distintos entornos lingüísticos.
- Seguridad en la síntesis de voz: Evitar eficazmente el uso indebido de los contenidos de síntesis de voz y garantizar el cumplimiento de las normas y la seguridad de la síntesis de voz.
¿Quién puede utilizar DragonV2.1?
- creador de contenidosLos productores de vídeo y los creadores de contenidos de audio añaden voces en off personalizadas a sus trabajos para aumentar el atractivo de sus contenidos.
- Empresas y marcas: Las empresas crean rápidamente imágenes de voz específicas de su marca para utilizarlas en publicidad y atención al cliente con el fin de mejorar el reconocimiento de la marca.
- Instituciones educativas y profesores: El ámbito de la educación ayuda a los estudiantes a practicar la pronunciación y la comprensión oral para mejorar la enseñanza y el aprendizaje.
- Desarrollador tecnológico: Los desarrolladores integran funciones de interacción de voz natural en asistentes inteligentes, hogares inteligentes y otras aplicaciones para mejorar la experiencia del usuario.
- usuario individual: Los usuarios particulares, especialmente los estudiantes de idiomas, practican la pronunciación y mejoran sus conocimientos lingüísticos gracias a la síntesis de voz de alta calidad.
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Puestos relacionados

Sin comentarios...