Analice automáticamente el contenido del PDF y extraiga el texto y las tablas de los servicios de código abierto

Introducción general
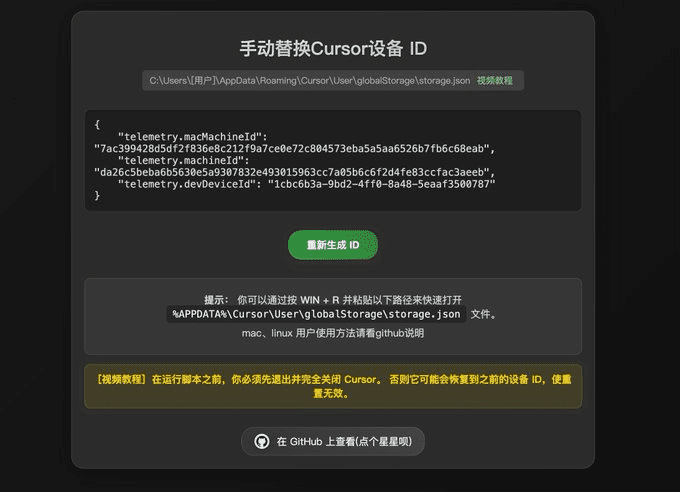
它能自动分析PDF文档的布局,识别页面中的文字、标题、图片、表格、公式等元素,并判断它们的正确顺序。工具支持OCR功能,可以把扫描PDF转为可搜索文本。它基于Docker运行,提供两种模型:视觉模型(Vision Grid Transformer,简称VGT)和LightGBM模型。前者精度高但耗资源,后者速度快且省资源。当前版本是v0.0.21,免费开放在GitHub上,适合需要处理PDF的研究人员、档案管理员等。

Lista de funciones
- 自动识别PDF页面中的文字、标题、图片、表格、公式等元素。
- 支持OCR功能,将扫描PDF转为可搜索文本。
- 判断页面元素的正确阅读顺序。
- 提供视觉模型(VGT)和LightGBM模型两种分析模式。
- 提取表格并支持多种格式输出,如Markdown、LaTeX、HTML。
- 提取公式并默认输出LaTeX格式。
- 支持多语言OCR,如英语、韩语等。
- 提供API接口,可集成到其他项目。
- 支持可视化输出,生成带标注的PDF。
Utilizar la ayuda
Proceso de instalación
这个工具用Docker运行,安装步骤如下:
- Preparar el entorno
先安装Docker。去Docker官网下载并安装。安装后,在终端输入:
docker --version
如果显示版本号,说明成功。如果用GPU,还需安装NVIDIA容器工具包,参考安装指南.
- 拉取镜像
在终端输入命令,拉取工具镜像:
- 有GPU:
docker pull huridocs/pdf-document-layout-analysis:v0.0.21 - 无GPU:
docker pull huridocs/pdf-document-layout-analysis:v0.0.21
- 运行服务
启动服务,分两种情况:
- 有GPU:
docker run --rm --name pdf-analysis --gpus '"device=0"' -p 5060:5060 huridocs/pdf-document-layout-analysis:v0.0.21 - 无GPU:
docker run --rm --name pdf-analysis -p 5060:5060 huridocs/pdf-document-layout-analysis:v0.0.21
服务启动后,默认监听5060端口。如果端口被占用,可改成其他端口,如5061。
- 验证服务
Abra su navegador y visitehttp://localhost:5060/info,如果返回版本信息,说明运行正常。
Cómo utilizar las principales funciones
工具通过API操作,常用功能如下:
1. OCR功能
要把扫描PDF转为可搜索文本,可以用OCR。
- procedimiento::
准备一个PDF,比如test.pdf,在终端运行:
curl -X POST -F 'language=en' -F 'file=@/path/to/test.pdf' localhost:5060/ocr --output result.pdf
language=en是英语,可换成kor(韩语)等。支持语言可通过curl localhost:5060/info查看。/path/to/test.pdf是文件路径,如/home/user/test.pdf.- 输出文件
result.pdf会保存在当前目录。 - al final::
得到一个可搜索的PDF,文字能复制。
2. 布局分析
要提取PDF中的元素并分析布局:
- procedimiento::
Corriendo:
curl -X POST -F 'file=@/path/to/test.pdf' localhost:5060 --output analysis.json
- 输出文件
analysis.json包含元素信息,如位置、类型(文字、表格等)。 - al final::
JSON文件列出每个元素的详细信息。
3. 快速模式
想更快处理,用LightGBM模型,加参数fast=true::
curl -X POST -F 'file=@/path/to/test.pdf' -F 'fast=true' localhost:5060 --output fast_analysis.json
- tenga en cuenta:速度快,但精度略低。
4. 表格和公式提取
- 提取表格::
指定格式(如Markdown):
curl -X POST -F 'file=@/path/to/test.pdf' -F 'extraction_format=markdown' localhost:5060 --output table.json
支持markdownylatexyhtmlFormato.
- 提取公式::
默认输出LaTeX格式,直接用布局分析命令即可。
5. 可视化输出
想看到标注后的PDF:
curl -X POST -F 'file=@/path/to/test.pdf' localhost:5060/visualize --output visualized.pdf
- al final::
输出PDF会标注每个元素的位置和类型。
6. 添加语言支持
默认支持少数语言,想加更多语言(如中文):
- 进入容器:
docker exec -it --user root pdf-analysis /bin/bash
- 安装语言包,例如中文:
apt-get install tesseract-ocr-chi-sim
- 检查:
curl localhost:5060/info
看到chi_sim说明成功。
7. 停止服务
停止服务:
docker stop pdf-analysis
输出元素顺序
分析结果按特定顺序排列。工具用Poppler确定初始阅读顺序,再根据元素类型调整:
- 页眉(header)排最前,按内部顺序排序。
- 普通元素(文字、表格等)按平均阅读顺序排列。
- 页脚(footer)和脚注(footnote)放最后。
- 无文字的元素(如图片)根据最近有文字的元素顺序排列。
advertencia
- requisitos de hardware:视觉模型需GPU和5GB显存,无GPU时用CPU会很慢。LightGBM只用CPU,需2GB内存。
- 速度:15页学术论文,快速模式0.42秒/页,VGT(GPU)1.75秒/页,VGT(CPU)13.5秒/页。
- ajustar los componentes durante las pruebas:出错时查看日志:
docker logs pdf-analysis
这些功能和步骤能帮你快速上手,处理各种PDF需求。
escenario de aplicación
- investigación académica
研究人员用它提取论文中的表格和公式,整理数据更高效。 - 档案管理
档案员把老文档扫描件转为可搜索PDF,查找方便。 - 法律工作
律师分析合同PDF,快速定位条款和表格。
CONTROL DE CALIDAD
- 收费吗?
不收费。这是开源工具,GitHub上免费下载使用。 - ¿Necesito trabajar en red?
下载镜像需联网,之后可离线运行。 - ¿Es compatible con el chino?
支持。需手动安装中文包(如tesseract-ocr-chi-sim),效果比英文略差但可用。
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Artículos relacionados

Sin comentarios...