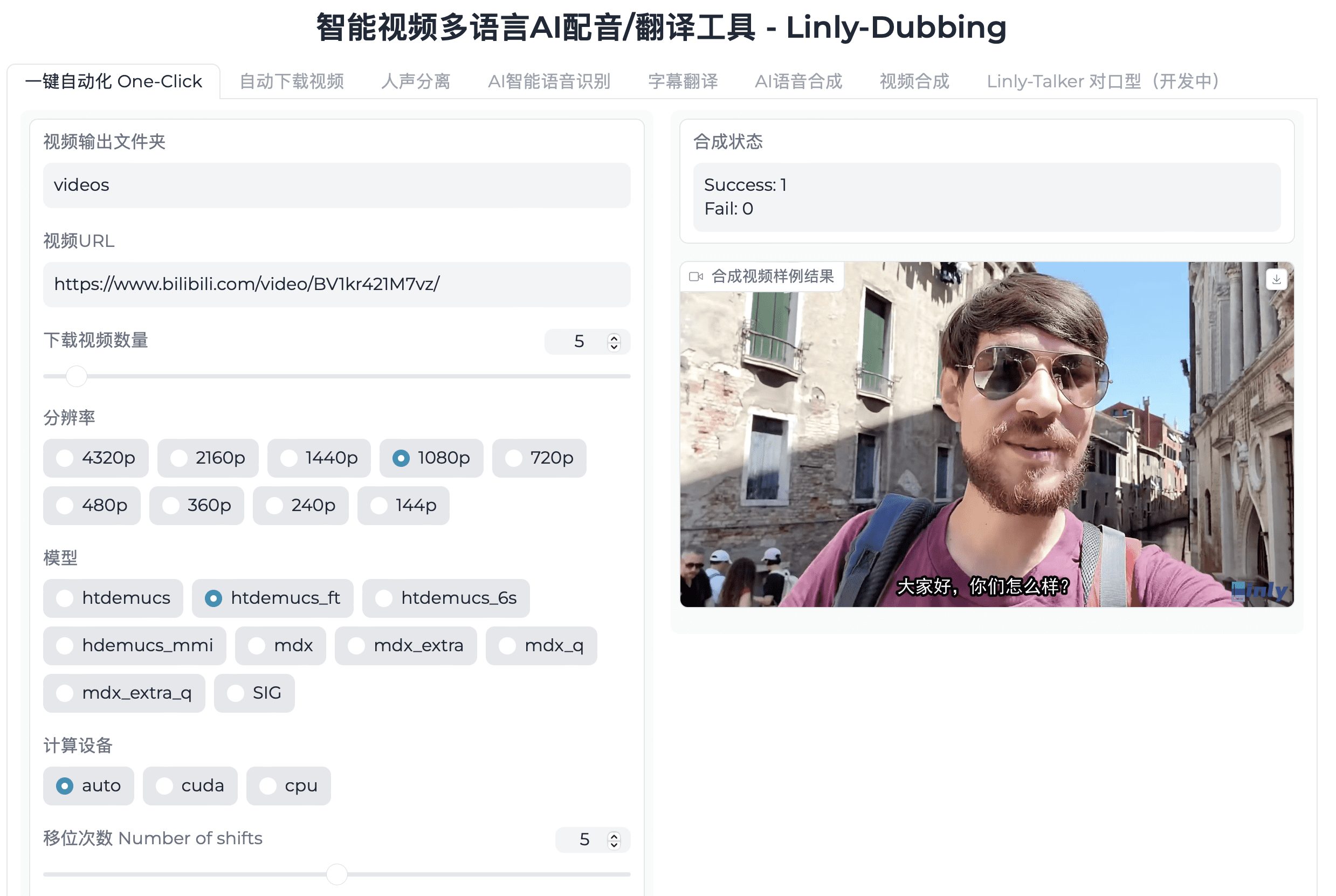
RealtimeSTT: herramienta de conversión de voz a texto en tiempo real para el reconocimiento del habla en streaming de baja latencia basada en Whisper.

Introducción general
RealtimeSTT es una eficaz biblioteca de conversión de voz a texto en tiempo real de baja latencia con detección avanzada de la actividad del habla y activación de palabras de despertador. Ha sido desarrollada por Kolja Beigel para aplicaciones que requieren una transcripción de voz a texto rápida y precisa. Tanto si se trata de un asistente de voz como de una aplicación que requiera una transcripción de voz precisa, RealtimeSTT ofrece un excelente rendimiento y facilidad de uso.

Lista de funciones
- Voz a texto en tiempo real: transcribe voz a texto en tiempo real para una gran variedad de escenarios de aplicación.
- Detección de la actividad del habla: detecta automáticamente cuándo un usuario empieza y deja de hablar, lo que mejora la precisión de la transcripción.
- Activación por palabra despertador: Soporta la función de palabra despertador, los usuarios pueden activar el sistema mediante palabras específicas.
- Baja latencia: Garantice una baja latencia en el proceso de voz a texto para mejorar la experiencia del usuario.
- Compatibilidad multiplataforma: Compatible con múltiples sistemas operativos y plataformas para facilitar la integración.
- Código fuente abierto: proporcione un código fuente abierto completo para que los desarrolladores puedan llevar a cabo el desarrollo secundario y la personalización.
Utilizar la ayuda
Proceso de instalación
- Almacén de proyectos de clonación:
git clone https://github.com/KoljaB/RealtimeSTT.git
- Vaya al catálogo de proyectos:
cd RealtimeSTT
- Instale la dependencia:
pip install -r requirements.txt
- (Opcional) Instale el soporte GPU:
pip install -r requirements-gpu.txt
Utilización
Iniciar el servidor
- Inicie el servidor de voz a texto:
stt-server
- Una vez iniciado el servidor, espere a que aparezca el mensaje "hable ahora".
Uso del cliente
- Inicie el cliente y conéctese al servidor:
stt
- Una vez iniciado el cliente, empieza a hablar y el sistema transcribirá la voz a texto en tiempo real.
Funciones principales
conversión de voz a texto en tiempo real
- importar (datos)
AudioToTextRecorderClase:
from RealtimeSTT import AudioToTextRecorder
- Define funciones que procesan texto:
def process_text(text):
print(text)
- Inicia la grabación y procesa el texto:
if __name__ == '__main__':
print("Wait until it says 'speak now'")
recorder = AudioToTextRecorder()
while True:
recorder.text(process_text)
Detección de actividad vocal
- El sistema detecta automáticamente cuándo el usuario empieza y deja de hablar, sin necesidad de configuración adicional.
activación del despertador
- Configure la función de palabra despertador, los usuarios pueden activar el sistema mediante palabras específicas, por favor consulte la documentación del proyecto para la configuración específica.
Ejemplo detallado de funcionamiento
Escriba todo lo que se dice
- importar (datos)
AudioToTextRecorderresponder cantandopyautogui::
from RealtimeSTT import AudioToTextRecorder
import pyautogui
- Define funciones que procesan texto:
def process_text(text):
pyautogui.typewrite(text + " ")
- Inicia la grabación y procesa el texto:
if __name__ == '__main__':
print("Wait until it says 'speak now'")
recorder = AudioToTextRecorder()
while True:
recorder.text(process_text)© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Artículos relacionados


Sin comentarios...