SmolDocling: un modelo de lenguaje visual para el tratamiento eficaz de documentos de pequeño volumen

Introducción general
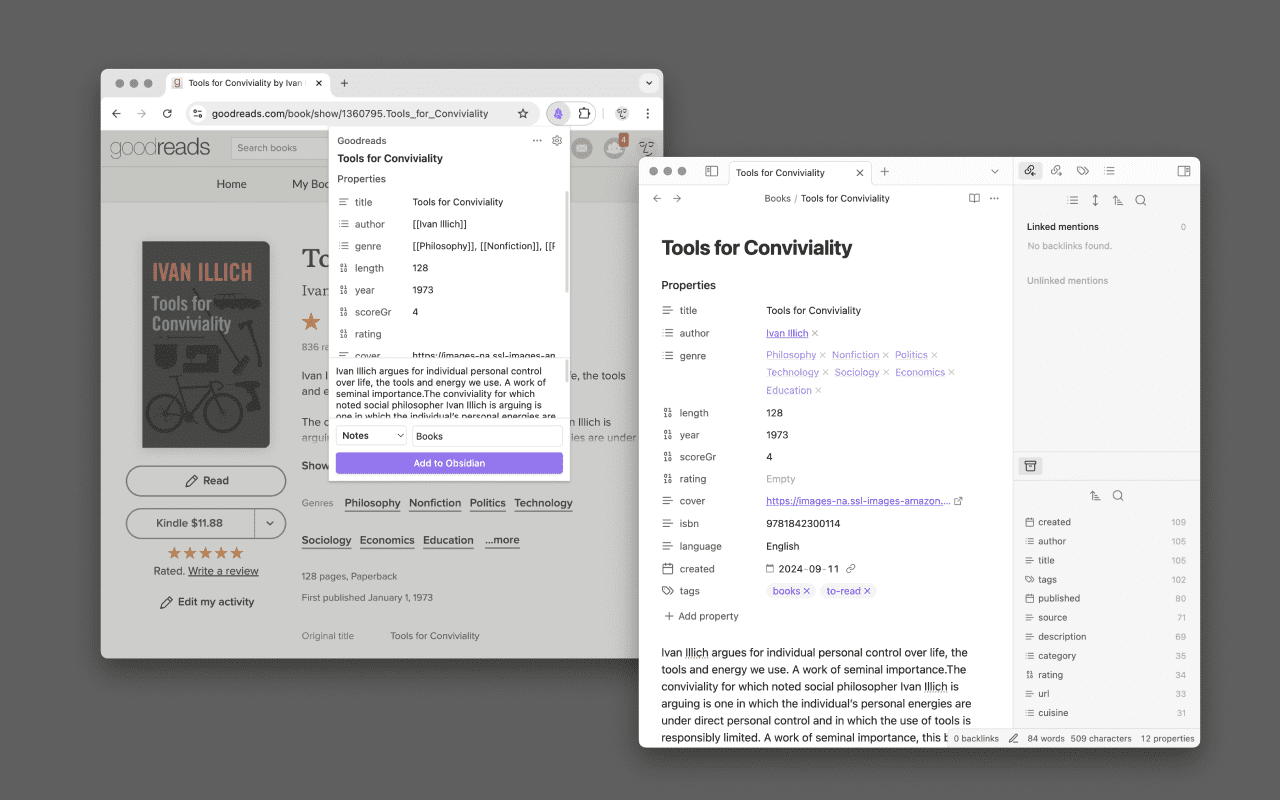
SmolDocling es un modelo de lenguaje visual (VLM) desarrollado por el equipo ds4sd en colaboración con IBM, basado en SmolVLM-256M y alojado en la plataforma Hugging Face. Es el VLM más pequeño del mundo, con sólo 256M de parámetros, y su función principal es extraer texto de imágenes, reconocer diseños, códigos, fórmulas y diagramas, y generar documentos estructurados en formato DocTags. smolDocling puede ejecutarse en dispositivos corrientes, con gran eficacia y bajo consumo de recursos. El equipo de desarrollo comparte este modelo a través del código abierto con la esperanza de ayudar a más personas a enfrentarse a las tareas documentales. Forma parte de la familia SmolVLM, que se centra en la conversión de documentos y es adecuada para usuarios que necesitan procesar documentos complejos con rapidez.


Lista de funciones
- Extracción de texto (OCR): Reconoce y extrae texto de imágenes, admite varios idiomas.
- Identificación del diseño: Analiza la estructura del documento en la imagen, por ejemplo, la posición de los títulos, los párrafos, las tablas.
- reconocimiento de códigosExtrae bloques de código y conserva la sangría y el formato.
- reconocimiento de fórmulas: Detecta fórmulas matemáticas y las convierte en texto editable.
- reconocimiento de cartasAnaliza el contenido del gráfico en la imagen y extrae los datos.
- Tratamiento de formularios: Identifica la estructura de la tabla y conserva la información de filas y columnas.
- Salida DocTagsConvertir los resultados del tratamiento en un formato de etiquetado uniforme para facilitar su uso posterior.
- Tratamiento de imágenes de alta resolución: Admite la entrada de imágenes de mayor resolución para mejorar la precisión del reconocimiento.
Utilizar la ayuda
El uso de SmolDocling se divide en dos partes: instalación y funcionamiento. A continuación se detallan los pasos para ayudar a los usuarios a empezar rápidamente.
Proceso de instalación
- Preparar el entorno
- Asegúrese de que tiene Python 3.8 o posterior instalado en su ordenador.
- Instale la biblioteca de dependencias introduciendo el siguiente comando en el terminal:
pip install torch transformers docling_core - Si tienes una GPU, se recomienda instalar PyTorch con soporte CUDA para correr más rápido. Comprueba la metodología:
import torch print("GPU可用:" if torch.cuda.is_available() else "使用CPU")
- Modelos de carga
- SmolDocling no necesita descargarse manualmente, está disponible directamente desde Hugging Face a través de un código.
- Asegúrese de que la red está abierta y de que los archivos del modelo se descargan automáticamente en la primera ejecución.
Pasos de uso
- Preparar la imagen
- Busca una imagen que contenga texto, como un documento escaneado o una captura de pantalla.
- Carga la imagen con código:
from transformers.image_utils import load_image image = load_image("你的图片路径.jpg")
- Inicialización de modelos y procesadores
- Carga el procesador y el modelo de SmolDocling:
from transformers import AutoProcessor, AutoModelForVision2Seq DEVICE = "cuda" if torch.cuda.is_available() else "cpu" processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview") model = AutoModelForVision2Seq.from_pretrained( "ds4sd/SmolDocling-256M-preview", torch_dtype=torch.bfloat16 ).to(DEVICE)
- Carga el procesador y el modelo de SmolDocling:
- Generar DocTags
- Configure las entradas y ejecute el modelo:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Convert this page to docling."}]}] prompt = processor.apply_chat_template(messages, add_generation_prompt=True) inputs = processor(text=prompt, images=[image], return_tensors="pt").to(DEVICE) generated_ids = model.generate(**inputs, max_new_tokens=8192) doctags = processor.batch_decode(generated_ids[:, inputs.input_ids.shape[1]:], skip_special_tokens=False)[0].lstrip() print(doctags)
- Configure las entradas y ejecute el modelo:
- Conversión a formatos comunes
- Convierte DocTags a Markdown u otros formatos:
from docling_core.types.doc import DoclingDocument doc = DoclingDocument(name="我的文档") doc.load_from_doctags(doctags) print(doc.export_to_markdown())
- Convierte DocTags a Markdown u otros formatos:
- Uso avanzado (opcional)
- Gestión de documentos de varias páginas: Procesa múltiples imágenes en un bucle y luego fusiona DocTags.
- optimizar el rendimiento: Ajustes
torch_dtype=torch.bfloat16Ahorro de memoria, los usuarios de GPU pueden activarflash_attention_2Aceleración:model = AutoModelForVision2Seq.from_pretrained( "ds4sd/SmolDocling-256M-preview", torch_dtype=torch.bfloat16, _attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager" ).to(DEVICE)
habilidad operativa
- Requisitos de imagenLas imágenes deben ser claras y el texto legible; cuanto mayor sea la resolución, mejor.
- Parámetros de ajusteSi el resultado es incompleto, añada
max_new_tokens(por defecto 8192). - archivo por lotes: Se pueden pasar varias imágenes como una lista
images=[image1, image2]. - Método de puesta en servicio: Salida de comprobación de resultados intermedios, por ejemplo, imprimir
inputsCompruebe si la entrada es correcta.
advertencia
- Se requiere acceso a Internet para la primera ejecución, después de lo cual se puede utilizar sin conexión.
- Las imágenes demasiado grandes pueden provocar falta de memoria, por lo que se recomienda recortarlas y ocuparse de ellas.
- Si se encuentra con un error, compruebe que la versión de Python y las bibliotecas dependientes están instaladas correctamente.
Con los pasos anteriores, los usuarios pueden convertir imágenes en documentos estructurados con SmolDocling. Todo el proceso es sencillo y adecuado tanto para principiantes como para usuarios profesionales.
escenario de aplicación
- investigación académica
Convierta documentos escaneados en texto, extraiga fórmulas y tablas para editarlos y citarlos fácilmente. - Documentación de programación
Convierte las imágenes manuales que contienen código a Markdown, conservando el formato del código para los desarrolladores. - ofimática
Manejar copias escaneadas de contratos, informes, etc., reconociendo el diseño y el contenido para mejorar la eficacia. - Apoyo educativo
Convierta las imágenes de los libros de texto en documentos editables para ayudar a profesores y alumnos a organizar sus apuntes.
CONTROL DE CALIDAD
- ¿Cuál es la diferencia entre SmolDocling y SmolVLM?
SmolDocling se basa en una versión optimizada de SmolVLM-256M, centrada en el procesamiento de documentos y la salida del formato DocTags, mientras que SmolVLM es más general y admite tareas como la descripción de imágenes. - ¿Qué sistemas operativos son compatibles?
Es compatible con Windows, Mac y Linux y puede ejecutarse con Python y las bibliotecas dependientes instaladas. - ¿Es rápida la tramitación?
Procesar una imagen sólo lleva unos segundos en un ordenador normal, y aún más rápido para los usuarios de GPU, normalmente menos de un segundo. - ¿Puede manejar texto escrito a mano?
Sí, pero los resultados dependen de la claridad de la escritura y se recomienda utilizar imágenes de texto impreso para obtener los mejores resultados.
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Puestos relacionados


Sin comentarios...