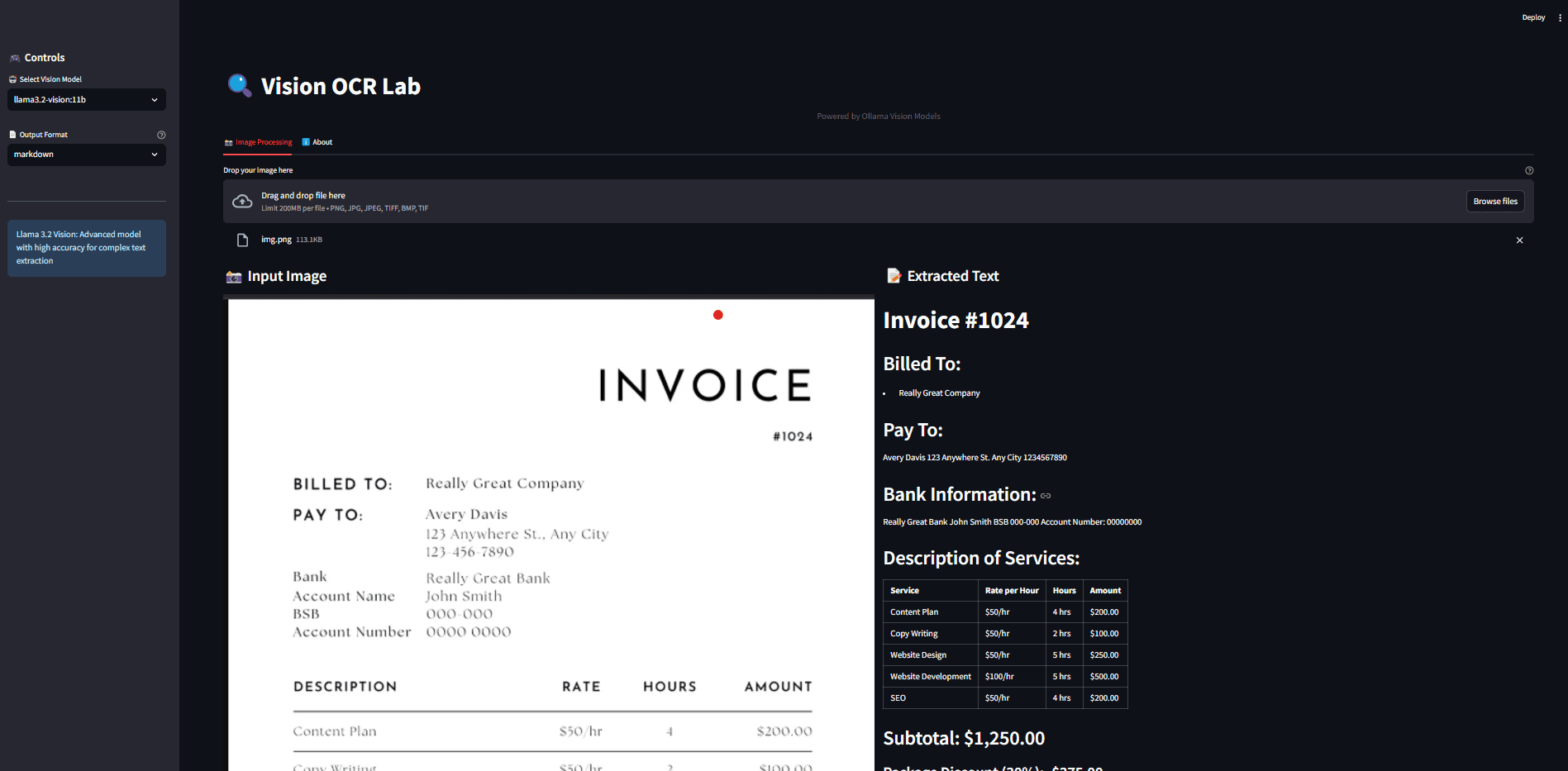
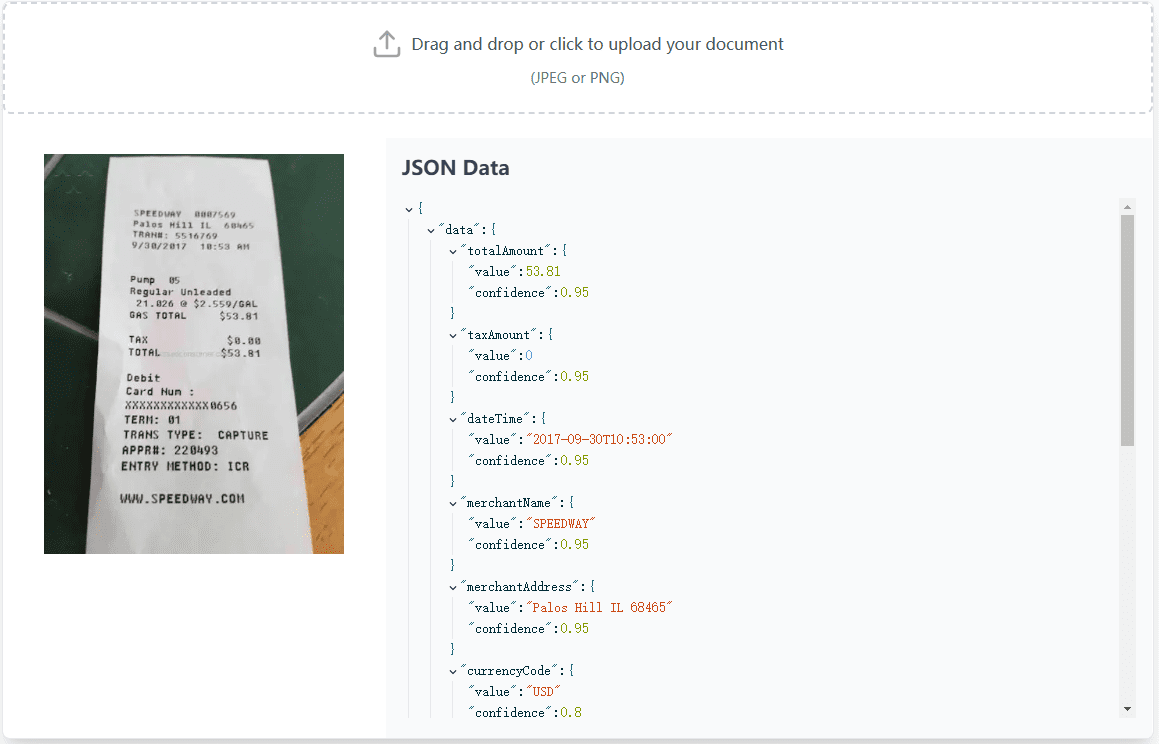
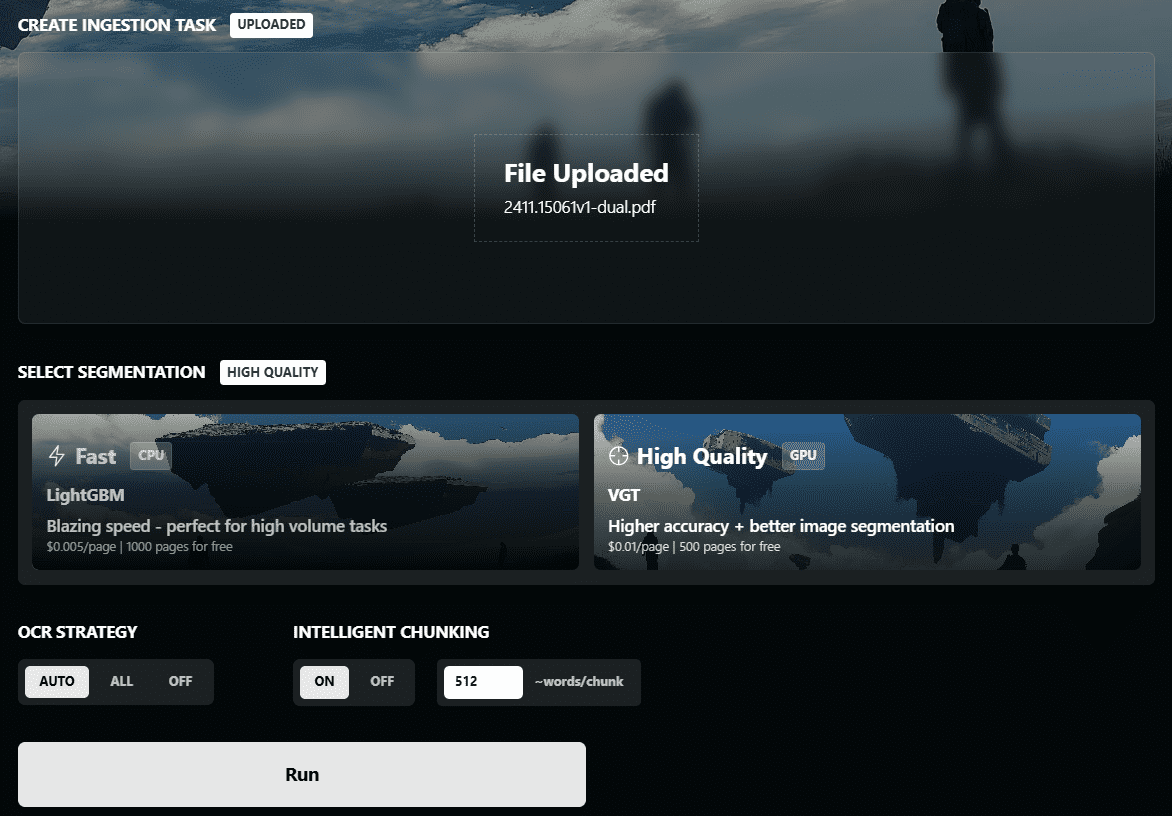
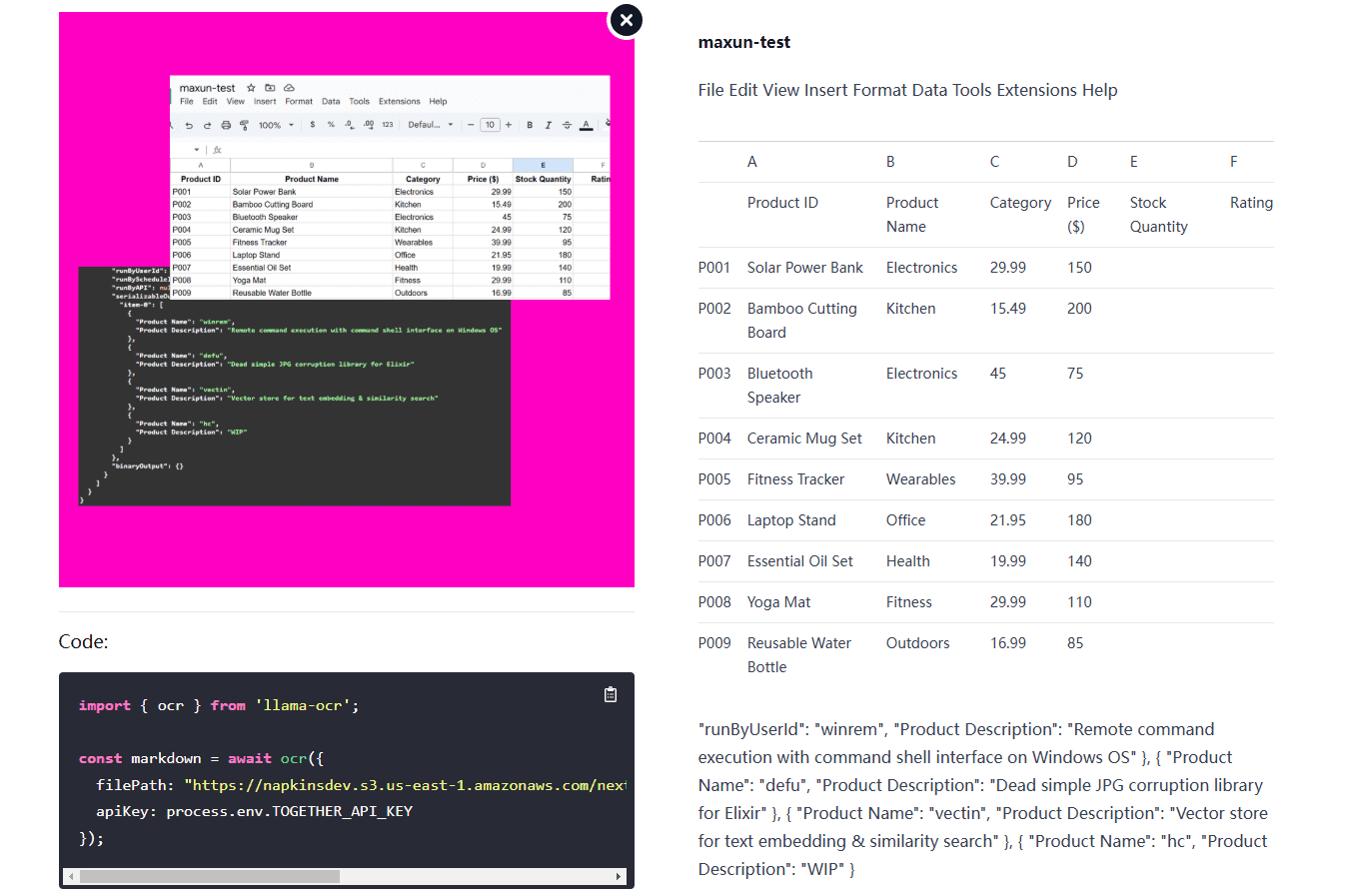
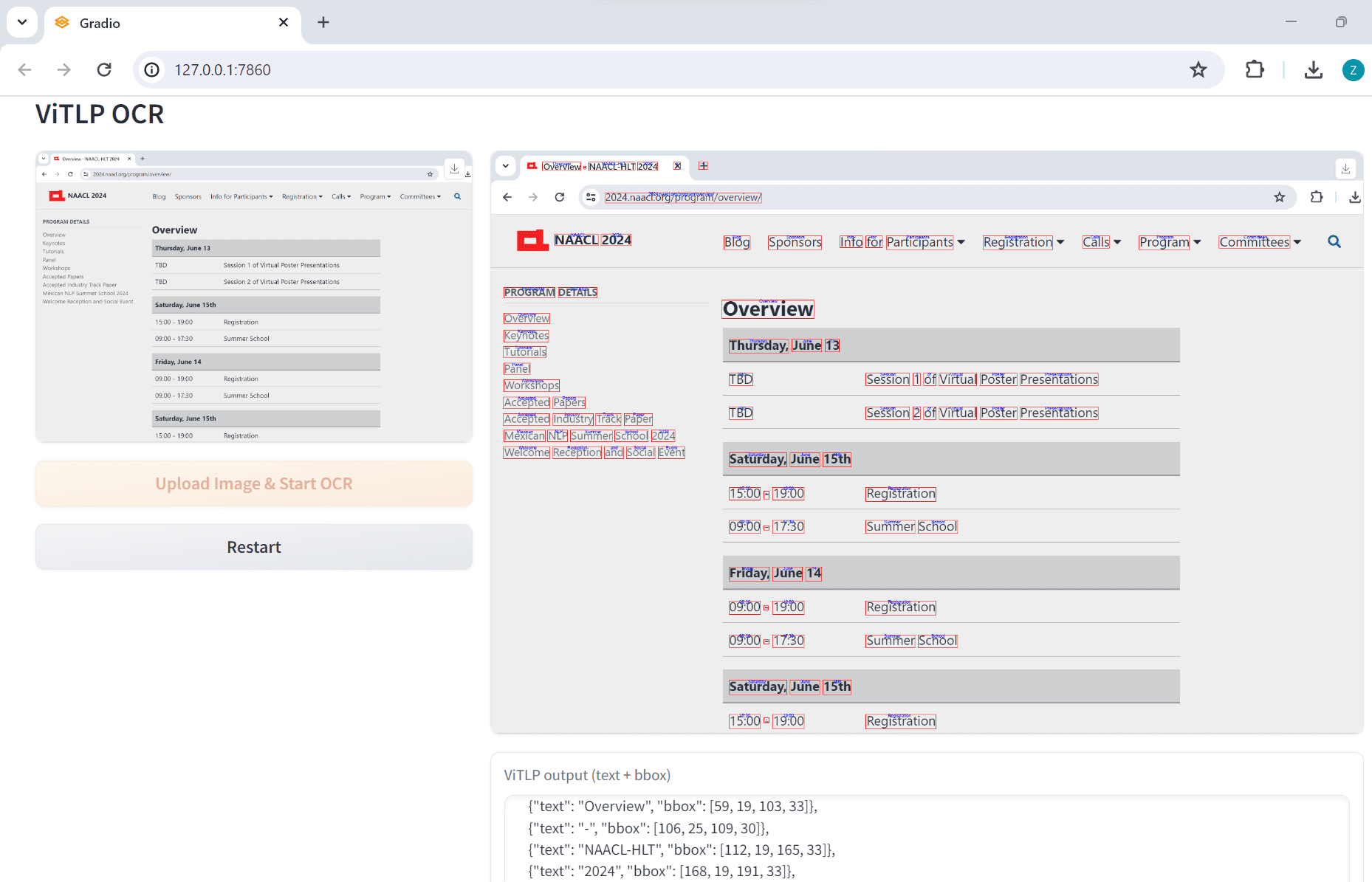
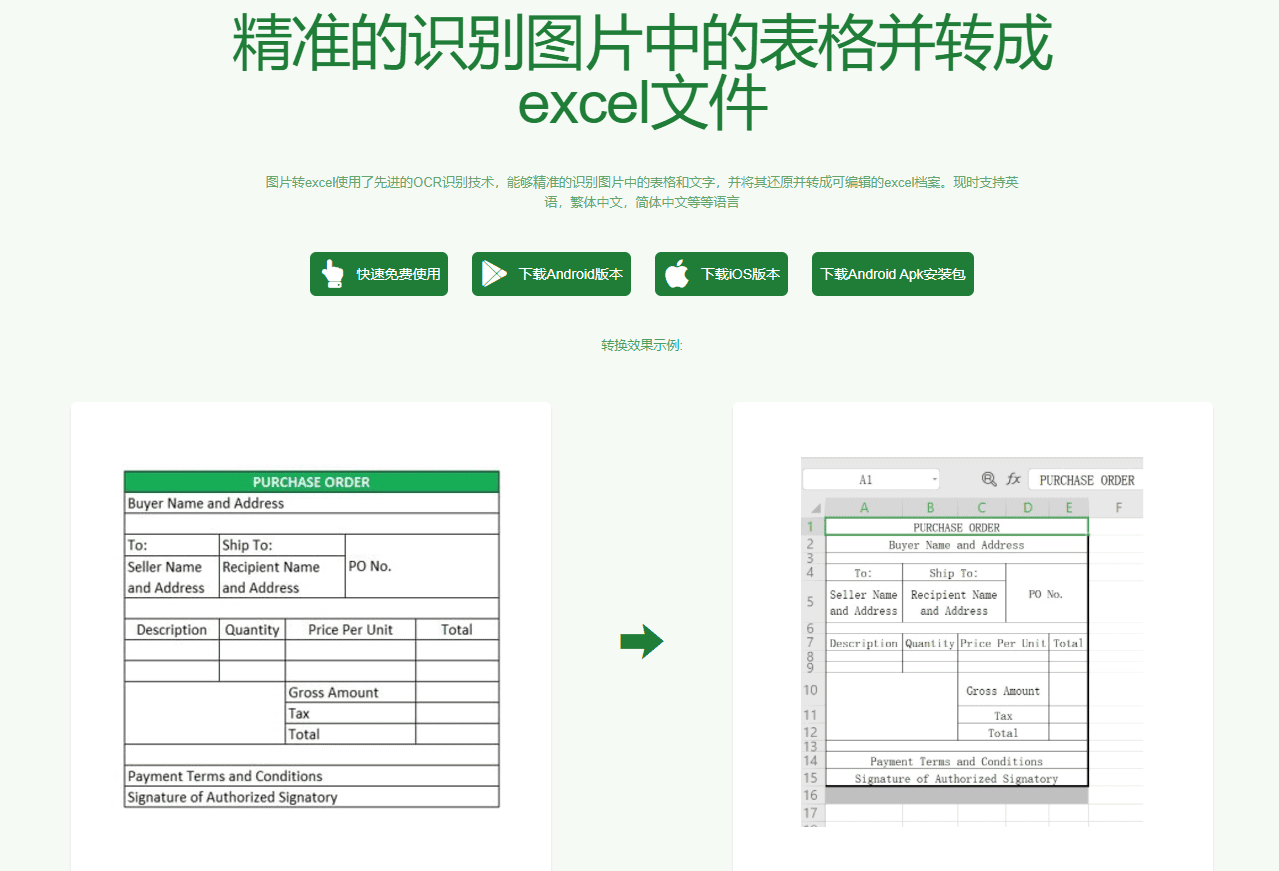
VOP: herramienta de OCR para extraer diagramas complejos y fórmulas matemáticas
Introducción completa Versatile OCR Program es una herramienta de reconocimiento óptico de caracteres (OCR) de código abierto diseñada para trabajar con documentos académicos y educativos complejos. Puede extraer texto, tablas, fórmulas matemáticas, diagramas y esquemas de PDF, imágenes y otros documentos y generar...