WritingBench: una herramienta de evaluación comparativa para comprobar la capacidad de redacción de grandes modelos

Introducción general
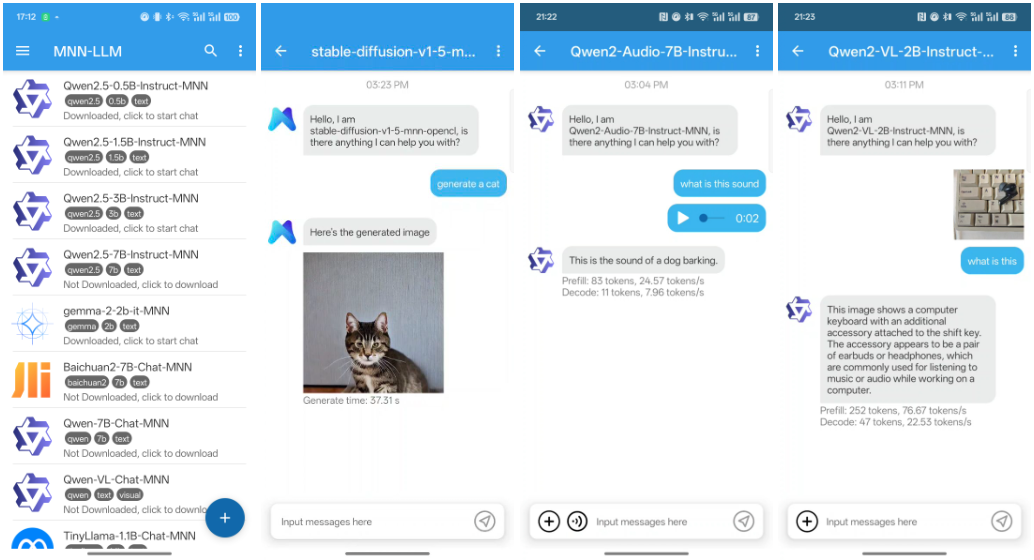
WritingBench 是 X-PLUG 团队开发的一个开源项目,托管在 GitHub 上。它是一个专门用来测试大模型写作能力的工具,提供了 1239 个真实世界的写作任务。这些任务覆盖 6 个主要领域和 100 个细分领域,结合风格、格式和长度要求,平均每个任务有 1546 个词。项目通过模型生成和人工优化结合的方式构建任务,确保多样性和实用性。每个任务配有 5 个具体评分标准,可通过大模型或专用评判模型评分。WritingBench 的代码和数据都免费开放,适合开发者优化大模型的写作能力。需要注意的是,项目没有提供 requirements.txt 文件,用户需自行配置环境。

Lista de funciones
- 提供 1239 个真实写作任务,覆盖学术、商业、法律、文学、教育和营销 6 大领域。
- 支持 100 个细分领域,任务贴近实际需求。
- 为每个任务生成 5 个动态评分标准,评估写作质量。
- 支持大模型自动评分和专用评判模型评分两种方式。
- 包含多样化的参考材料,如财务报表或法律模板。
- 提供开源代码、数据集和评估脚本,用户可自由下载和修改。
Utilizar la ayuda
WritingBench 是一个基于 GitHub 的开源项目,用户可以访问 https://github.com/X-PLUG/WritingBench 获取资源。它不需要在线服务,只需下载到本地运行。以下是详细的使用步骤和功能操作指南:
获取项目资源
- 打开浏览器,输入 https://github.com/X-PLUG/WritingBench。
- 点击右上角绿色 “Code” 按钮,选择 “Download ZIP” 下载,或用 Git 命令克隆:
git clone https://github.com/X-PLUG/WritingBench.git
- 解压文件到本地,文件夹包含代码、数据和文档。
准备运行环境
WritingBench 没有提供 requirements.txt 文件,因此需要手动安装 Python 环境和依赖库。步骤如下:
- 确保安装 Python 3.8 或更高版本,在终端输入
python --version检查。 - 进入项目文件夹:
cd WritingBench
- 安装基本依赖库。官方未明确列出所有依赖,但根据功能推测需要以下库:
pip install torch(用于评判模型,可能需要 GPU 支持)。pip install transformers(用于大模型操作)。pip install requests(可能用于数据处理)。- 其他可能需要的库可根据报错信息补充安装。
- 如果使用专用评判模型,需安装 PyTorch 和 CUDA,具体版本参考 https://pytorch.org/get-started/locally/。
项目结构说明
下载后的目录结构如下:
evaluate_benchmark.py:评估脚本。prompt.py:提示模板。evaluator/:评估接口目录。critic.py:专用评判模型接口。llm.py:大模型评估接口。benchmark_query/:任务数据目录。benchmark_all.jsonl:完整 1239 个任务数据集。requirement/:按风格、格式、长度分类的子集。
使用写作任务数据
- espectáculo (una entrada)
benchmark_query/benchmark_all.jsonl,查看 1239 个任务。 - 每个任务包括描述、领域和参考材料。例如:“为 2023 年 Q3 财务报告写 500 字总结”。
- 用你的大模型生成回答,示例代码:
from your_model import Model
task = "为2023年Q3财务报告写500字总结"
model = Model()
response = model.generate(task)
with open("response.txt", "w") as f:
f.write(response)
运行评估工具
WritingBench 支持两种评估方式:
大模型评分
- compilador
evaluator/llm.py,添加 API 配置:
self.api_key = "your_api_key_here"
self.url = "Your API endpoint"
self.model = "Your model name"
- 运行评估脚本:
python evaluate_benchmark.py --evaluator llm --query_criteria_file benchmark_query/benchmark_all.jsonl --input_file response.txt --output_file scores.jsonl
- 输出结果包括 5 个评分标准的得分和理由。
专用评判模型评分
- 从 https://huggingface.co/AQuarterMile/WritingBench-Critic-Model-Qwen-7B 下载评判模型。
- 将模型放入本地路径,编辑
evaluator/critic.py::
self.model = LLM(model="path/to/critic_model", tensor_parallel_size=1)
- Evaluación operativa:
python evaluate_benchmark.py --evaluator critic --query_criteria_file benchmark_query/benchmark_all.jsonl --input_file response.txt --output_file scores.jsonl
- 输出结果显示每项标准的分数(0-10 分)。
自定义任务和评分
- existe
benchmark_query/中添加新 JSON 文件,写入任务描述和材料。 - modificaciones
prompt.py或评估脚本,调整评分标准。 - 测试后可上传至 GitHub 分享。
数据生成过程
任务通过以下方式生成:
- 大模型从 6 大领域和 100 个子领域生成初始任务。
- 通过风格调整、格式要求等优化任务。
- 30 名标注员收集开源材料。
- 5 名专家筛选任务和材料,确保实用性。
这些步骤帮助用户快速上手 WritingBench,测试和优化大模型写作能力。
escenario de aplicación
- 模型开发
开发者用 WritingBench 测试模型在学术论文或广告文案中的表现,改进不足。 - 教育研究
研究人员分析大模型生成教学材料或批改作文的能力。 - 写作辅助
用户用任务数据激发创意,或用评分工具检查文章质量。
CONTROL DE CALIDAD
- 为什么没有 requirements.txt 文件?
官方未提供,可能是为了让用户根据自己的模型和环境灵活配置依赖。 - ¿Necesito trabajar en red?
不需要,下载后本地运行即可,但下载模型或依赖时需联网。 - 评判模型如何获取?
从 https://huggingface.co/AQuarterMile/WritingBench-Critic-Model-Qwen-7B 下载。
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Artículos relacionados

Sin comentarios...