
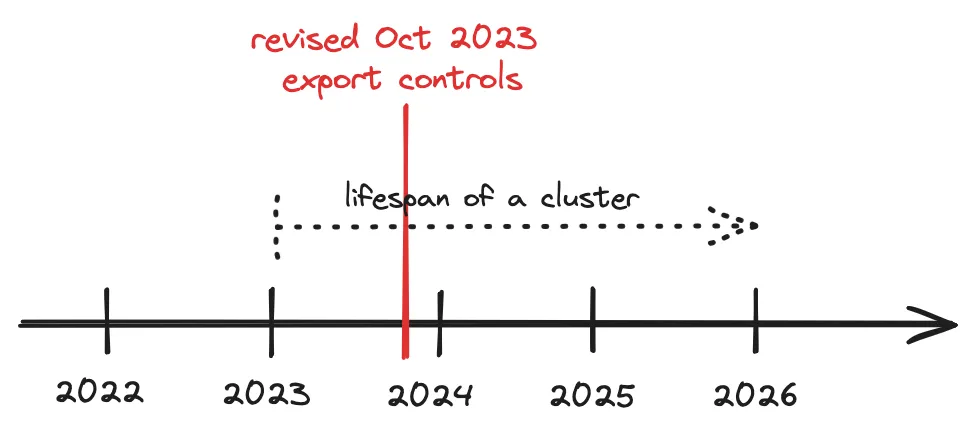
NVIDIA, Google y OpenAI recurren a fábricas de "datos sintéticos" para entrenar modelos de IA

NVIDIA, empresa de tarjetas gráficas (NVDA), Alphabet google (GOOGL) y la popular startup OpenAI están recurriendo a fábricas de "datos sintéticos" para satisfacer las ingentes necesidades de datos para el entrenamiento de algoritmos de inteligencia artificial de aprendizaje profundo. En el Consumer Electronics Show de esta semana, el CEO del fabricante de chips alabó la capacidad de sintetizar datos, lo que podría ser positivo para las acciones de NVIDIA.

El paso a los datos sintéticos se produce en medio de informes según los cuales las empresas de IA se están quedando sin los datos del mundo real necesarios para entrenar potentes modelos de IA.
"Los datos sintéticos ofrecen una solución crítica para abordar las necesidades de datos escasos o sensibles. Esta tendencia se está acelerando a medida que las principales empresas de IA agotan los datos disponibles en Internet que pueden utilizarse para el entrenamiento", afirma el científico de datos Ben Lorica en el informe Perspectivas 2025.
"Los equipos ya pueden generar datos sintéticos para casos de uso específicos utilizando modelos de base, mientras que las organizaciones más grandes pueden ser capaces de combinar datos sintéticos con sus conjuntos de datos propietarios", añadió Lorica, que edita el boletín Gradient Flow AI. "Busque herramientas mejoradas de generación de datos sintéticos que surjan de los principales laboratorios de IA para que esta tecnología sea más accesible para los profesionales".
En CES 2025, Jen-Hsun Huang, Consejero Delegado de NVIDIA, destacó el futuro papel de la IA en aplicaciones de automoción y robótica. Los datos sintéticos ayudarán, afirmó.
Acciones de NVIDIA: la "fábrica de datos"
"NVIDIA está recopilando y organizando datos tradicionales y utilizándolos para crear datos sintéticos", afirma el economista Ed Yardeni en un informe sobre los avances en CES. "Tanto los datos tradicionales como los sintéticos se utilizarán para entrenar agentes y bots de IA en las fábricas de datos de NVIDIA".
Yardeni añadió: "[El fabricante de chips] ha marcado una gran diferencia al permitir que Nvidia Cosmos Observando 20 millones de horas de vídeo sobre la naturaleza, los seres humanos y cualquier cosa relacionada con el mundo físico desarrolló Nvidia Cosmos. Basándose en estos escenarios del mundo real, también puede crear datos sintéticos para crear aún más escenarios. A continuación, puede utilizar sus datos reales y sintéticos para entrenar a robots que necesitan navegar por el mundo, ya sea trabajando en un almacén o conduciendo un coche autoconducido".
La rama de computación en nube de Google también está dando un gran impulso a los datos sintéticos para aplicaciones empresariales. Además, el último modelo base de OpenAI con capacidades de razonamiento mejoradas utiliza técnicas de generación de datos sintéticos.
Un gran debate de cara a 2025 es si los modelos de IA han empezado a estancarse debido a la dificultad de acceder a datos de entrenamiento de alta calidad producidos artificialmente. Además, empresas como Google y Metaplataformas (META) Los gigantes tecnológicos como META disponen de datos internos propios de YouTube, Maps, Instagram y Facebook que pueden utilizarse para construir modelos más amplios.
Mientras tanto, las acciones de NVIDIA suben 41 TP3T en 2025. Tras dispararse 2.391 TP3T en 2023, las acciones de NVIDIA suben 1.711 TP3T en 2024.
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Artículos relacionados


Sin comentarios...