Intelligent Agentic Retrieval Enhanced Generation: visión general de la tecnología Agentic RAG

resúmenes
Los grandes modelos lingüísticos (LLM), como el GPT-4 de OpenAI, el PaLM de Google y el LLaMA de Meta, han cambiado radicalmente la Inteligencia Artificial (IA) al permitir la generación de textos y la comprensión del lenguaje natural similares a los humanos. Sin embargo, su dependencia de datos de entrenamiento estáticos limita su capacidad para responder a consultas dinámicas en tiempo real, lo que da lugar a resultados obsoletos o imprecisos. La Generación de Recuperación Aumentada (RAG) ha surgido como una solución para aumentar los LLM integrando la recuperación de datos en tiempo real para proporcionar respuestas contextualmente relevantes y oportunas. A pesar de lo prometedor de la RAG, los sistemas RAG tradicionales están limitados en términos de flujos de trabajo estáticos y carecen de la flexibilidad necesaria para acomodar el razonamiento en varios pasos y la gestión de tareas complejas.
La Generación Aumentada de Recuperación Agenética (RAG Agentic) supera estas limitaciones integrando agentes autónomos de IA en el proceso de RAG. Estos agentes utilizan patrones de diseño agéntico -reflexión, planificación, uso de herramientas y colaboración multiagente- para gestionar dinámicamente las estrategias de recuperación, refinar iterativamente la comprensión contextual y adaptar los flujos de trabajo a los requisitos de tareas complejas. Esta integración permite al sistema Agentic RAG ofrecer una flexibilidad, escalabilidad y conocimiento del contexto inigualables en una amplia gama de aplicaciones.
Esta revisión explora exhaustivamente la GAR Agenética, empezando por sus principios subyacentes y la evolución del paradigma de la GAR. Detalla la categorización de las arquitecturas de GAR Agenética, destaca sus aplicaciones clave en sectores como la sanidad, las finanzas y la educación, y explora estrategias prácticas de implementación. Además, aborda los retos que plantean la ampliación de estos sistemas, la garantía de una toma de decisiones ética y la optimización del rendimiento de las aplicaciones en el mundo real, al tiempo que ofrece información detallada sobre los marcos y herramientas para la implantación de la GAR Agenética.
Palabras clave. Grandes modelos lingüísticos (LLM) - Inteligencia artificial (IA) - Comprensión del lenguaje natural - Generación aumentada de recuperación (RAG) - RAG agenética - Agentes autónomos de IA - Reflexión - Planificación - Uso de herramientas - Colaboración multiagente - Patrones agenéticos - Comprensión contextual - Adaptación dinámica - Escalabilidad - Recuperación de datos en tiempo real - Clasificación RAG agenética - Aplicaciones sanitarias - Aplicaciones financieras - Aplicaciones educativas - Toma de decisiones éticas con IA - Optimización del rendimiento - Razonamiento multipaso
1 Introducción
Los grandes modelos lingüísticos (LLM) [1, 2] [3], como el GPT-4 de OpenAI, el PaLM de Google y el LLaMA de Meta, han cambiado radicalmente la Inteligencia Artificial (IA) al generar texto similar al humano y realizar complejas tareas de procesamiento del lenguaje natural. Estos modelos han impulsado la innovación en el campo del diálogo [4], incluidos los agentes conversacionales, la creación automática de contenidos y la traducción en tiempo real. Los últimos avances han ampliado sus capacidades a tareas multimodales como la generación de texto a imagen y de texto a vídeo [5], permitiendo la creación y edición de vídeos e imágenes a partir de indicaciones detalladas [6], lo que amplía el abanico de aplicaciones potenciales de la IA generativa.
A pesar de estos avances, los LLM siguen enfrentándose a importantes limitaciones debido a su dependencia de datos estáticos de preentrenamiento. Esta dependencia suele dar lugar a información obsoleta, respuestas fantasma [7] e incapacidad para adaptarse a escenarios dinámicos del mundo real. Estos retos ponen de relieve la necesidad de sistemas que puedan integrar datos en tiempo real y perfeccionar dinámicamente las respuestas para mantener la pertinencia contextual y la precisión.
La Generación Aumentada de Recuperación (RAG) [8, 9] surgió como una solución prometedora a estos retos. La RAG mejora la relevancia y la puntualidad de las respuestas combinando las capacidades generativas de los LLM con mecanismos de recuperación externos [10]. Estos sistemas recuperan información en tiempo real de fuentes como bases de conocimiento [11], APIs o la web, salvando eficazmente la distancia entre los datos estáticos de entrenamiento y los requisitos dinámicos de las aplicaciones. Sin embargo, los flujos de trabajo tradicionales de los GAR siguen estando constreñidos por su diseño lineal y estático, que limita su capacidad para realizar razonamientos complejos de varios pasos, integrar una comprensión contextual profunda y refinar iterativamente las respuestas.
La evolución de los agentes [12] ha mejorado aún más las capacidades de los sistemas de IA. Los agentes modernos, incluidos los basados en LLM y los móviles [13], son entidades inteligentes capaces de percibir, razonar y realizar tareas de forma autónoma. Estos agentes utilizan patrones de flujo de trabajo basados en agentes, como la reflexión [14], la planificación [15], el uso de herramientas y la colaboración multiagente [16], lo que les permite gestionar flujos de trabajo dinámicos y resolver problemas complejos.
La convergencia de la GAR y la inteligencia agéntica ha dado lugar a la Generación Aumentada de Recuperación Agenética (GAR Agentic) [17], un paradigma que integra agentes en el proceso de GAR. La GAR Agentic implementa estrategias de recuperación dinámicas, comprensión contextual y refinamiento iterativo [18], lo que permite un procesamiento de la información adaptable y eficiente. A diferencia de la GAR tradicional, la GAR Agentic emplea agentes autónomos para orquestar la recuperación, filtrar la información relevante y refinar las respuestas, y destaca en escenarios en los que se requiere precisión y adaptabilidad.
Esta revisión explora los principios subyacentes, la clasificación y las aplicaciones de la GAR Agenética. Ofrece una visión completa de los paradigmas de la GAR, como la GAR simple, la GAR modular y la GAR gráfica [19], y su evolución hacia los sistemas de GAR agéntica. Entre sus principales aportaciones se incluyen una clasificación detallada de los marcos de la GAR Agenética, aplicaciones en ámbitos como la sanidad [20, 21], las finanzas y la educación [22], y reflexiones sobre estrategias de implementación, evaluación comparativa y consideraciones éticas.
El documento está estructurado de la siguiente manera: la sección 2 presenta la GAR y su evolución, haciendo hincapié en las limitaciones de los enfoques tradicionales. La sección 3 detalla los principios de la inteligencia agéntica y los modelos agénticos. La sección 4 ofrece una clasificación de los sistemas de GAR agéntica, incluidos los marcos basados en un único agente, en varios agentes y en grafos. La sección 5 examina las aplicaciones de la GAR agéntica, mientras que la sección 6 analiza las herramientas y marcos de implementación. La Sección 7 se centra en los puntos de referencia y los conjuntos de datos, y la Sección 8 concluye con las orientaciones futuras para los sistemas de GAR Agenética.
2 Bases para la generación de mejoras de recuperación
2.1 Visión general de la Generación Aumentada de Recuperación (RAG)
La generación aumentada por recuperación (RAG) representa un gran avance en el campo de la inteligencia artificial, ya que combina la potencia generativa de los grandes modelos lingüísticos (LLM) con la recuperación de datos en tiempo real. Aunque los LLM han demostrado unas capacidades excepcionales en el procesamiento del lenguaje natural, su dependencia de datos estáticos de preentrenamiento suele dar lugar a respuestas obsoletas o incompletas. RAG aborda esta limitación recuperando dinámicamente información relevante de fuentes externas e incorporándola al proceso generativo, lo que permite generar resultados contextualmente precisos y con capacidad de respuesta en el momento oportuno.
2.2 Componentes básicos del GAR
La arquitectura del sistema GAR integra tres componentes principales (véase la Figura 1):
- recuperar (datos)Recuperador de datos: responsable de la consulta de fuentes de datos externas, como bases de conocimientos, API o bases de datos vectoriales. Los recuperadores avanzados utilizan la búsqueda vectorial densa y modelos basados en transformadores para mejorar la precisión de la recuperación y la relevancia semántica.
- refuerceProcesar los datos recuperados para extraer y resumir la información más relevante para el contexto de la consulta.
- generandoCombinar la información recuperada con el conocimiento preentrenado del LLM para generar respuestas coherentes y adecuadas al contexto.

Figura 1: Componentes básicos de RAG
2.3 Evolución del paradigma GAR
El campo de la Generación Aumentada de Recuperación (RAG) ha experimentado avances significativos para hacer frente a la creciente complejidad de las aplicaciones del mundo real, en las que la precisión contextual, la escalabilidad y el razonamiento en varios pasos son fundamentales. Partiendo de la simple recuperación basada en palabras clave, se ha transformado en sistemas complejos, modulares y adaptativos capaces de integrar diversas fuentes de datos y procesos autónomos de toma de decisiones. Esta evolución pone de manifiesto la creciente necesidad de que los sistemas GAR gestionen consultas complejas con eficiencia y eficacia.
Esta sección examina la evolución del paradigma GAR, describiendo las etapas clave de su desarrollo - GAR Simple, GAR Avanzado, GAR Modular, GAR Gráfico y GAR Basado en Agentes - así como sus características definitorias, puntos fuertes y limitaciones. Al comprender la evolución de estos paradigmas, el lector puede apreciar los avances realizados en la recuperación y las capacidades generativas, así como sus aplicaciones en diversos ámbitos.
2.3.1 GAR simple
La RAG simple [23] representa la implementación base de la generación mejorada por recuperación. La figura 2 ilustra las RAG simples para flujos de trabajo de recuperación-lectura sencillos, centrados en la recuperación basada en palabras clave y conjuntos de datos estáticos. Estos sistemas se basan en técnicas sencillas de recuperación basadas en palabras clave, como TF-IDF y BM25, para recuperar documentos de conjuntos de datos estáticos. A continuación, los documentos recuperados se utilizan para mejorar la generación de modelos lingüísticos.

Figura 2: Visión general del GAR ingenuo.
La RAG simple se caracteriza por su sencillez y facilidad de aplicación, y es adecuada para tareas que impliquen consultas basadas en hechos con una complejidad contextual mínima. Sin embargo, tiene varias limitaciones:
- Falta de conocimiento del contextoLos documentos recuperados no suelen captar los matices semánticos de una consulta porque se basan en la concordancia léxica y no en la comprensión semántica.
- Fragmentación de la salidaLa falta de preprocesamiento avanzado o de integración contextual suele dar lugar a respuestas incoherentes o demasiado genéricas.
- problema de escalabilidadLas técnicas de recuperación basadas en palabras clave no suelen funcionar bien con grandes conjuntos de datos y no suelen identificar la información más relevante.
A pesar de estas limitaciones, el sencillo sistema RAG constituye una prueba de concepto fundamental para combinar la recuperación con la generación, sentando las bases de paradigmas más complejos.
2.3.2 GAR avanzado
Los sistemas de GAR avanzada [23] se basan en las limitaciones de la GAR simple e integran la comprensión semántica y técnicas de recuperación mejoradas. La figura 3 muestra la mejora semántica y el proceso iterativo y contextualizado de la GAR avanzada en la recuperación. Estos sistemas utilizan modelos de recuperación densos, como la Recuperación de Párrafos Densos (DPR), y algoritmos neuronales de clasificación para mejorar la precisión de la recuperación.

Figura 3: Visión general del GAR avanzado
Entre las principales características del GAR Avanzado se incluyen:
- Búsqueda de vectores densosLas consultas y los documentos se representan en un espacio vectorial de alto nivel, lo que permite una mejor alineación semántica entre las consultas de los usuarios y los documentos recuperados.
- reordenación del contextoEl modelo neuronal reordena los documentos recuperados para dar prioridad a la información contextualmente más relevante.
- Búsqueda iterativaRAG avanzado: introduce un mecanismo de recuperación multisalto que permite razonar sobre consultas complejas a través de múltiples documentos.
Estos avances hacen que la GAR avanzada sea adecuada para aplicaciones que requieren una gran precisión y una comprensión matizada, como la síntesis de investigaciones y las recomendaciones personalizadas. Sin embargo, sigue habiendo problemas de sobrecarga computacional y escalabilidad limitada, especialmente cuando se trata de grandes conjuntos de datos o consultas de varios pasos.
2.3.3 GAR modular
Los GAR modulares [23] representan el último avance en el paradigma de los GAR, con énfasis en la flexibilidad y la personalización. Estos sistemas descomponen los procesos de recuperación y generación en componentes separados y reutilizables para permitir la optimización específica del dominio y la adaptabilidad de la tarea. La Figura 4 ilustra la arquitectura modular, mostrando estrategias de recuperación híbridas, procesos componibles e integración de herramientas externas.
Entre las innovaciones clave del GAR modular se incluyen:
- estrategia de búsqueda híbridaLa combinación de métodos de recuperación dispersos (p. ej., Sparse Encoder - BM25) y técnicas de recuperación densas (p. ej., DPR - Dense Paragraph Retrieval) para maximizar la precisión en distintos tipos de consulta.
- integración de herramientasIntegración de API externas, bases de datos o herramientas de cálculo para gestionar tareas específicas, como el análisis de datos en tiempo real o cálculos específicos de un dominio.
- Procesos componibles: El GAR modular permite sustituir, aumentar o reconfigurar recuperadores, generadores y otros componentes, permitiendo de forma independiente un alto grado de adaptación a casos de uso específicos.
Por ejemplo, un sistema RAG modular diseñado para el análisis financiero podría recuperar los precios de las acciones en tiempo real a través de una API, analizar las tendencias históricas mediante una búsqueda intensiva y generar perspectivas de inversión procesables a través de un modelo de lenguaje personalizado. Esta modularidad y personalización hace que la GAR modular sea muy adecuada para tareas complejas y multidominio, proporcionando tanto escalabilidad como precisión.

Figura 4: Visión general del GAR modular
2.3.4 Figura GAR
Graph RAG [19] amplía los sistemas tradicionales de generación de mejoras de recuperación integrando estructuras de datos basadas en grafos, como se muestra en la Figura 5. Estos sistemas utilizan las relaciones y jerarquías de los datos de grafos para mejorar el razonamiento y la mejora contextual. Estos sistemas utilizan las relaciones y jerarquías de los datos gráficos para mejorar el razonamiento multisalto y la mejora contextual. Al integrar la recuperación basada en grafos, los RAG de grafos son capaces de generar resultados más ricos y precisos, especialmente en tareas que requieren una comprensión relacional.
La figura RAG se caracteriza por su capacidad para:
- conectividad de nodos: Captura y razonamiento sobre relaciones entre entidades.
- Gestión jerárquica del conocimiento: Tratamiento de datos estructurados y no estructurados mediante jerarquías de grafos.
- sensible al contexto: Añade comprensión relacional mediante el uso de rutas de grafos.
Sin embargo, el gráfico RAG tiene algunas limitaciones:
- Escalabilidad limitadaLa dependencia de la estructura del grafo puede limitar la escalabilidad, especialmente para una amplia gama de fuentes de datos.
- Dependencia de los datosLa alta calidad de los datos gráficos es esencial para obtener resultados significativos, lo que limita su aplicación a conjuntos de datos no estructurados o mal anotados.
- Complejidad de la integraciónEl objetivo de este artículo es explicar cómo la integración de datos de grafos con sistemas de recuperación no estructurados aumenta la complejidad del diseño y la aplicación.
Graph RAG es muy adecuado para aplicaciones en áreas como el diagnóstico médico y la investigación jurídica, donde el razonamiento sobre relaciones estructuradas es fundamental.

Figura 5: Visión general del gráfico RAG
2.3.5 Proxy RAG
La GAR basada en agentes representa un cambio de paradigma al introducir agentes autónomos capaces de tomar decisiones dinámicas y optimizar el flujo de trabajo. A diferencia de los sistemas estáticos, los GAR basados en agentes emplean estrategias de refinamiento iterativo y recuperación adaptativa para hacer frente a consultas complejas, en tiempo real y multidominio. Este paradigma aprovecha la modularidad del proceso de recuperación y generación, al tiempo que introduce la autonomía basada en agentes.
Entre las principales características del GAR basado en agentes se incluyen:
- autodeterminaciónLos agentes evalúan y gestionan de forma independiente las estrategias de recuperación en función de la complejidad de la consulta.
- Perfeccionamiento iterativo: Integrar circuitos de retroalimentación para mejorar la precisión de la recuperación y la pertinencia de las respuestas.
- Optimización del flujo de trabajo: Programación dinámica de tareas para hacer más eficientes las aplicaciones en tiempo real.
A pesar de estos avances, los GAR basados en agentes se enfrentan a una serie de retos:
- Complejidad de la coordinación: La gestión de las interacciones entre agentes requiere complejos mecanismos de coordinación.
- carga computacionalEl uso de múltiples agentes aumenta los requisitos de recursos para flujos de trabajo complejos.
- limitaciones de escalabilidad: Aunque escalable, la naturaleza dinámica del sistema puede ejercer presión sobre volúmenes de consulta elevados.
Los GAR basados en agentes han destacado en aplicaciones en ámbitos como la atención al cliente, el análisis financiero y las plataformas de aprendizaje adaptativo, donde la adaptabilidad dinámica y la precisión contextual son fundamentales.
2.4 Retos y limitaciones de los sistemas tradicionales de GAR
Los sistemas tradicionales de Generación Aumentada de Recuperación (RAG) han ampliado enormemente las capacidades de los grandes modelos lingüísticos (LLM) al integrar la recuperación de datos en tiempo real. Sin embargo, estos sistemas siguen enfrentándose a una serie de retos clave que dificultan su eficacia en aplicaciones complejas del mundo real. Las limitaciones más notables se centran en la integración del contexto, el razonamiento en varios pasos y los problemas de escalabilidad y latencia.
2.4.1 Integración contextual
Incluso cuando los sistemas GAR recuperan con éxito la información pertinente, a menudo tienen dificultades para integrarla perfectamente en la respuesta generada. La naturaleza estática del proceso de recuperación y el conocimiento limitado del contexto conducen a resultados fragmentados, incoherentes o demasiado genéricos.
EJEMPLO: Una consulta del tipo "Avances recientes en la investigación de la enfermedad de Alzheimer y sus implicaciones para el tratamiento precoz" puede generar artículos científicos y directrices médicas relevantes. Sin embargo, los sistemas tradicionales de GAR no suelen ser capaces de sintetizar estos hallazgos en explicaciones coherentes que vinculen los nuevos tratamientos a situaciones concretas de los pacientes. Del mismo modo, para una consulta del tipo "¿Cuáles son las mejores prácticas sostenibles para la agricultura a pequeña escala en regiones áridas?", un sistema convencional puede recuperar artículos sobre métodos agrícolas generales pero omitir prácticas sostenibles de importancia crítica para entornos áridos.
Cuadro 1. Análisis comparativo de los paradigmas GAR
| Paradigma | Características principales | Puntos fuertes |
|---|---|---|
| RAG ingenuo | - Por palabra clave recuperación (por ejemplo, TF-IDF. BM25) | - Sencillo y fácil de aplicar - Adecuado para consultas basadas en hechos |
| RAG avanzado | - Modelos de recuperación densa (por ejemplo, DPR) - Clasificación y reclasificación neuronal - Recuperación multisalto | - Recuperación de alta precisión - Contexto mejorado pertinencia |
| RAG modular | - Recuperación híbrida (dispersa y densa). - Integración de herramientas y API. | - Alta flexibilidad y personalización - Adecuado para diversas aplicaciones - Escalable |
| Gráfico RAG | - Integración de estructuras basadas en grafos - Razonamiento multisalto - Enriquecimiento contextual mediante nodos | - Capacidad de razonamiento relacional - Mitiga las alucinaciones - Ideal para tareas de datos estructurados |
| RAG Agentico | - Agentes autónomos - Toma de decisiones dinámica - Perfeccionamiento iterativo y flujo de trabajo optimización | - Adaptable a los cambios en tiempo real - Escalable para tareas multidominio - Alta precisión |
2.4.2 Razonamiento en varios pasos
Muchas consultas del mundo real requieren un razonamiento iterativo o de varios saltos, es decir, recuperar y sintetizar información a partir de múltiples pasos. Los sistemas tradicionales de GAR no suelen estar preparados para refinar la recuperación basándose en información intermedia o en los comentarios de los usuarios, lo que da lugar a respuestas incompletas o inconexas.
Ejemplo: una consulta compleja como "¿Qué lecciones de las políticas europeas de energías renovables pueden aplicarse a los países en desarrollo y cuáles son sus posibles repercusiones económicas?". Es necesario conciliar múltiples elementos de información, incluidos datos políticos, contextualización a regiones en desarrollo y análisis económico. Los sistemas tradicionales de GAR son a menudo incapaces de conectar estos elementos dispares en una respuesta coherente.
2.4.3 Problemas de escalabilidad y latencia
A medida que aumenta el número de fuentes de datos externas, la consulta y clasificación de grandes conjuntos de datos resulta cada vez más intensiva desde el punto de vista computacional. Esto provoca una latencia considerable, que merma la capacidad del sistema para ofrecer respuestas oportunas en aplicaciones en tiempo real.
Ejemplo: en entornos en los que el tiempo es un factor determinante, como el análisis financiero o la atención al cliente en tiempo real, los retrasos debidos a la consulta de múltiples bases de datos o al trabajo con grandes conjuntos de documentos pueden disminuir la utilidad global del sistema. Por ejemplo, los retrasos en la recuperación de tendencias de mercado en el comercio de alta frecuencia pueden hacer que se pierdan oportunidades.
2.5 El GAR basado en agentes: un cambio de paradigma
Los sistemas tradicionales de GAR, con sus flujos de trabajo estáticos y su limitada capacidad de adaptación, suelen tener dificultades para gestionar el razonamiento dinámico en varios pasos y las tareas complejas del mundo real. Al integrar agentes autónomos capaces de tomar decisiones de forma dinámica, razonar de forma iterativa y aplicar estrategias de recuperación adaptativas, los GAR basados en agentes superan sus limitaciones inherentes al tiempo que mantienen la modularidad de los paradigmas anteriores. Esta evolución permite resolver tareas más complejas y multidominio con mayor precisión y comprensión contextual, lo que sitúa a los GAR basados en agentes como la base de la próxima generación de aplicaciones de IA. En concreto, los sistemas de GAR basados en agentes reducen la latencia mediante flujos de trabajo optimizados y perfeccionan los resultados de forma incremental, abordando retos que han obstaculizado durante mucho tiempo la escalabilidad y eficacia de los GAR tradicionales.
3 Principios básicos y contexto de la Inteligencia de Agentes
La inteligencia de los agentes constituye la base de los sistemas de Generación Aumentada de Recuperación (GAR) basados en agentes, permitiéndoles ir más allá de la naturaleza estática y reactiva de los GAR tradicionales. Al integrar agentes autónomos capaces de tomar decisiones dinámicas, razonar de forma iterativa y colaborar en los flujos de trabajo, los sistemas GAR basados en agentes presentan una mayor adaptabilidad y precisión. Esta sección explora los principios básicos que sustentan la inteligencia de los agentes.
Componentes de un agente de IA. Básicamente, un agente de IA se compone de (véase la Figura 6):
- LLM (con funciones y tareas definidas)Motor de razonamiento: Sirve como motor de razonamiento primario e interfaz de diálogo para el agente. Interpreta las consultas de los usuarios, genera respuestas y mantiene la coherencia.
- Memoria (a corto y largo plazo)Capturar el contexto y los datos relevantes durante una interacción. La memoria a corto plazo [25] registra el estado inmediato del diálogo, mientras que la memoria a largo plazo [25] almacena el conocimiento acumulado y la experiencia del agente.
- Planificación (reflexión y autocrítica)Guiar el proceso de razonamiento iterativo del agente a través de la reflexión, el enrutamiento de consultas o la autocrítica [26] garantiza que las tareas complejas se descompongan de forma eficaz [15].
- Herramientas (búsqueda vectorial, búsqueda web, API, etc.): Amplía la capacidad de los agentes para ir más allá de la generación de textos y acceder a recursos externos, datos en tiempo real o informática especializada.

Figura 6: Visión general de los agentes de IA
3.1 Modelo de delegación
Los patrones de agentes [27, 28] proporcionan formas estructuradas de guiar el comportamiento de los agentes en los sistemas de Generación Aumentada de Recuperación (RAG) basados en agentes. Estos patrones permiten a los agentes adaptarse, planificar y colaborar de forma dinámica, garantizando que el sistema pueda gestionar con precisión y escalabilidad tareas complejas del mundo real. Cuatro patrones clave constituyen la base del flujo de trabajo de los agentes:
3.1.1 Reflexión
La reflexión es un patrón de diseño fundamental en el flujo de trabajo del agente que le permite evaluar y perfeccionar sus resultados de forma iterativa. Al integrar un mecanismo de autorretroalimentación, el agente puede identificar y resolver errores, incoherencias y áreas de mejora, mejorando así el rendimiento de tareas como la generación de código, la generación de texto y las preguntas y respuestas (como se muestra en la Figura 7). En la práctica, la reflexión consiste en pedir al agente que critique sus resultados en términos de corrección, estilo y eficacia, y luego incorporar esta información a las iteraciones posteriores. Las herramientas externas, como las pruebas unitarias o las búsquedas en la web, pueden mejorar aún más este proceso validando los resultados y poniendo de relieve las lagunas.

Figura 7: Visión general de la autogestión agenética Reflexión
En los sistemas multiagente, la reflexión puede implicar distintos roles, por ejemplo, un agente genera el resultado mientras otro lo critica, facilitando así la mejora colaborativa. Por ejemplo, en la investigación jurídica, los agentes pueden refinar iterativamente las respuestas para garantizar su precisión y exhaustividad reevaluando la jurisprudencia recuperada. La reflexión ha mostrado importantes mejoras de rendimiento en estudios como Self-Refine [29], Reflexion [30] y CRITIC [26].
3.1.2 Planificación
La planificación [15] es un patrón de diseño clave en los flujos de trabajo de los agentes que les permite descomponer de forma autónoma tareas complejas en subtareas más pequeñas y manejables. Esta capacidad es fundamental para el razonamiento multisalto y la resolución iterativa de problemas en escenarios dinámicos e inciertos (como se muestra en la Figura 8).

Figura 8: Visión general de la planificación agenética
Mediante la planificación, los agentes pueden determinar dinámicamente la secuencia de pasos necesarios para alcanzar objetivos más amplios. Esta adaptabilidad permite a los agentes abordar tareas que no pueden predefinirse, garantizando la flexibilidad en la toma de decisiones. Aunque potente, la planificación puede producir resultados menos predecibles que los flujos de trabajo deterministas, como la reflexión. La planificación es especialmente adecuada para tareas que requieren una adaptación dinámica, en las que los flujos de trabajo predefinidos no son suficientes. A medida que la tecnología madure, su potencial para impulsar aplicaciones innovadoras en distintos ámbitos seguirá creciendo.
3.1.3 Utilización de herramientas
El uso de herramientas permite a los agentes ampliar sus capacidades interactuando con herramientas externas, API o recursos computacionales, como se muestra en la figura 9. Este modelo permite al agente recopilar información, realizar cálculos y manipular datos más allá de sus conocimientos preformados. Al integrar dinámicamente las herramientas en el flujo de trabajo, los agentes pueden adaptarse a tareas complejas y proporcionar resultados más precisos y contextualmente relevantes.

Figura 9: Visión general del uso de las herramientas
Los flujos de trabajo de los agentes modernos integran el uso de herramientas en diversas aplicaciones, como la recuperación de información, el razonamiento computacional y la interconexión con sistemas externos. La aplicación de este modelo ha evolucionado significativamente con el desarrollo de las capacidades de invocación de funciones de GPT-4 y de sistemas capaces de gestionar el acceso a numerosas herramientas. Estos avances han facilitado flujos de trabajo de agentes complejos en los que los agentes pueden seleccionar y ejecutar de forma autónoma las herramientas más relevantes para una tarea determinada.
Aunque el uso de herramientas ha mejorado enormemente los flujos de trabajo de los agentes, sigue siendo difícil optimizar la selección de herramientas, especialmente cuando hay un gran número de opciones disponibles. Para resolver este problema se han propuesto técnicas inspiradas en la generación mejorada por recuperación (RAG), como la selección basada en heurística.
3.1.4 Multiagente
La colaboración multiagente [16] es un patrón de diseño clave en los flujos de trabajo de agentes que permite la especialización de tareas y el procesamiento en paralelo. Los agentes se comunican entre sí y comparten resultados intermedios, garantizando que el flujo de trabajo global siga siendo eficiente y coherente. Al asignar subtareas a agentes especializados, este patrón mejora la escalabilidad y adaptabilidad de flujos de trabajo complejos. Los sistemas multiagente permiten a los desarrolladores dividir tareas complejas en subtareas más pequeñas y manejables que se asignan a distintos agentes. Este enfoque no sólo mejora el rendimiento de las tareas, sino que también proporciona un potente marco para gestionar interacciones complejas. Cada agente tiene su propia memoria y flujo de trabajo, que puede incluir el uso de herramientas, la reflexión o la planificación, lo que permite una resolución de problemas dinámica y colaborativa (véase la Figura 10).

Figura 10: Visión general de MultiAgent
Aunque la colaboración multiagente ofrece un gran potencial, es un paradigma de diseño mucho menos predecible que otros flujos de trabajo más maduros, como la reflexión y el uso de herramientas. Dicho esto, marcos emergentes como AutoGen, Crew AI y LangGraph están proporcionando nuevas formas de implementar soluciones multiagente eficaces.
Estos patrones son la piedra angular del éxito de los sistemas GAR basados en agentes, ya que les permiten adaptar dinámicamente los flujos de trabajo de recuperación y generación para satisfacer las demandas de entornos diversos y dinámicos. Al utilizar estos patrones, los agentes pueden gestionar tareas iterativas y contextualizadas que superan las capacidades de los sistemas GAR tradicionales.
4 Clasificación de los sistemas GAR basados en agentes
Los sistemas de Generación Aumentada de Recuperación (RAG) basados en agentes pueden clasificarse en distintos marcos arquitectónicos en función de su complejidad y sus principios de diseño. Entre ellos figuran las arquitecturas de agente único, los sistemas multiagente y las arquitecturas de agente jerárquico. El objetivo de cada marco es abordar retos específicos y optimizar el rendimiento en diferentes aplicaciones. Esta sección ofrece una clasificación detallada de estas arquitecturas, destacando sus características, ventajas y limitaciones.
4.1 Agente único Proxy RAG: Router
Los GAR basados en un agente único [31] actúan como un sistema centralizado de toma de decisiones en el que un agente gestiona la recuperación, el encaminamiento y la integración de la información (como se muestra en la Figura 11). Esta arquitectura simplifica el sistema al combinar estas tareas en un único agente unificado, lo que la hace especialmente adecuada para entornos con un número limitado de herramientas o fuentes de datos.
flujo de trabajo
- Presentación y evaluación de consultasEl proceso comienza cuando el usuario envía una consulta. Un agente coordinador (o agente maestro de recuperación) recibe la consulta y la analiza para determinar la fuente de información más adecuada.
- Selección de fuentes de conocimientoEn función del tipo de consulta, el agente coordinador elige entre varias opciones de búsqueda:
- Base de datos estructuradaPara las consultas que requieren acceso a datos tabulares, el sistema puede utilizar un motor Text-to-SQL que interactúa con bases de datos como PostgreSQL o MySQL.
- búsqueda semánticaLa recuperación de información no estructurada se basa en vectores para recuperar los documentos pertinentes (por ejemplo, PDF, libros o registros de organizaciones).
- Búsqueda en InternetPara obtener información contextual amplia o en tiempo real, el sistema utiliza herramientas de búsqueda en Internet para acceder a los datos más recientes.
- sistema de recomendaciónPara las consultas personalizadas o contextuales, el sistema utiliza un motor de recomendación que ofrece sugerencias a medida.
- Integración de datos y síntesis LLMModelo de Lenguaje Amplio (LLM): una vez que se han recuperado los datos relevantes de una fuente seleccionada, se pasan al Modelo de Lenguaje Amplio (LLM), que reúne la información recopilada, integrando las percepciones de múltiples fuentes en una respuesta coherente y contextualmente relevante.
- ProducciónRespuesta: por último, el sistema genera una respuesta completa y orientada al usuario a la consulta original. La respuesta se presenta en un formato procesable y conciso y, opcionalmente, incluye referencias o citas a las fuentes utilizadas.
Principales características y ventajas
- Simplicidad centralizadaUn único agente se encarga de todas las tareas de recuperación y encaminamiento, lo que facilita el diseño, la implantación y el mantenimiento de la arquitectura.
- Eficiencia y optimización de recursosCon menos agentes y una coordinación más sencilla, el sistema requiere menos recursos informáticos y puede procesar las consultas más rápidamente.
- enrutamiento dinámicoEl agente evalúa cada consulta en tiempo real y selecciona la fuente de conocimiento más adecuada (por ejemplo, bases de datos estructuradas, búsqueda semántica, búsqueda en la web).
- Versatilidad entre herramientasCompatibilidad con múltiples fuentes de datos y API externas, lo que permite admitir flujos de trabajo estructurados y no estructurados.
- Adecuado para sistemas sencillosPara aplicaciones con tareas bien definidas o requisitos de integración limitados (por ejemplo, recuperación de archivos, flujos de trabajo basados en SQL).

Figura 11: Visión general de los GAR de un solo agente
Casos prácticos: Atención al cliente
llamar la atención sobre algo: ¿Pueden informarme del estado de entrega de mi pedido?
Procesos del sistema (flujo de trabajo de agente único)::
- Presentación y evaluación de consultas::
- El usuario envía una consulta, que es recibida por el agente coordinador.
- Coordinarse con los agentes para analizar las consultas e identificar las fuentes de información más adecuadas.
- Selección de fuentes de conocimiento::
- Recuperar los datos de seguimiento de la base de datos de gestión de pedidos.
- Obtenga actualizaciones en tiempo real de la API del servicio de mensajería.
- Opcionalmente, se puede realizar una búsqueda en Internet para identificar las condiciones locales que afectan a la entrega, como las condiciones meteorológicas o los retrasos logísticos.
- Integración de datos y síntesis LLM::
- Pasa los datos pertinentes al LLM, que consolida la información en una respuesta coherente.
- Producción::
- El sistema genera una respuesta procesable y concisa que proporciona un seguimiento en tiempo real de las actualizaciones y las posibles alternativas.
receptivo::
Respuesta integradaEl seguimiento en tiempo real de UPS indica que el paquete se encuentra en un centro de distribución regional.
4.2 Sistema RAG multiagente
RAG multiagente [31] representa una evolución modular y escalable de la arquitectura de agente único, con el objetivo de gestionar procesos complejos y diversos tipos de consulta mediante el aprovechamiento de múltiples agentes especializados (como se muestra en la Figura 12). En lugar de confiar en un único agente para gestionar todas las tareas (razonamiento, recuperación y generación de respuestas), el sistema asigna responsabilidades a varios agentes, cada uno optimizado para una función o fuente de datos específica.
flujo de trabajo
- Presentación de consultasEl proceso comienza con una consulta del usuario, que es recibida por un agente coordinador o un agente de recuperación maestro. Este agente actúa como coordinador central y delega la consulta en un agente de recuperación especializado en función de los requisitos de la consulta.

Figura 12: Visión general de los sistemas multiagente RAG
- Agentes de búsqueda especializadosLas consultas se asignan a varios agentes de recuperación, cada uno de los cuales se centra en un tipo específico de fuente de datos o tarea. Ejemplo:
- Agente 1Manejar consultas estructuradas, por ejemplo interactuando con bases de datos basadas en SQL como PostgreSQL o MySQL.
- Agente 2: Gestione búsquedas semánticas para recuperar datos no estructurados de fuentes como PDF, libros o registros internos.
- Agente 3: Centrado en la recuperación de información pública en tiempo real a partir de búsquedas en la web o API.
- Agente 4: Se especializa en sistemas de recomendación que proporcionan sugerencias contextualmente relevantes basadas en el comportamiento o los perfiles de los usuarios.
- Acceso a herramientas y recuperación de datosCada agente dirige la consulta a la herramienta o fuente de datos adecuada dentro de su dominio, por ejemplo:
- búsqueda vectorialpara la relevancia semántica.
- Texto a SQLPara datos estructurados.
- Búsqueda en Internet: Para información pública en tiempo real.
- API: Para acceder a servicios externos o sistemas propietarios.
El proceso de recuperación se ejecuta en paralelo, lo que permite procesar eficazmente distintos tipos de consulta.
- Integración de datos y síntesis LLMUna vez finalizada la recuperación, todos los datos del agente se transmiten al Modelo de Lenguaje Amplio (LLM), que consolida la información recuperada en una respuesta coherente y contextualmente relevante que integra a la perfección la información procedente de múltiples fuentes.
- ProducciónEl sistema genera una respuesta exhaustiva que se devuelve al usuario en un formato procesable y conciso.
Principales características y ventajas
- modularizaciónCada agente funciona de forma independiente, lo que permite añadir o eliminar agentes en función de las necesidades del sistema.
- escalabilidadEl procesamiento paralelo de varios agentes permite al sistema gestionar eficazmente grandes volúmenes de consultas.
- Especialización de tareasCada agente está optimizado para un tipo específico de consulta o fuente de datos, lo que mejora la precisión y la relevancia de la recuperación.
- eficaciaEl sistema, al asignar tareas a agentes especializados, minimiza los cuellos de botella y mejora el rendimiento de los flujos de trabajo complejos.
- versatilidad: Para aplicaciones en múltiples ámbitos, como la investigación, el análisis, la toma de decisiones y la atención al cliente.
desafío
- Complejidad de la coordinaciónLa gestión de la comunicación entre agentes y la delegación de tareas requiere complejos mecanismos de coordinación.
- carga computacional: El procesamiento paralelo de varios agentes puede aumentar el uso de recursos.
- integración de datosLa integración de los resultados de distintas fuentes en una respuesta coherente no es fácil y requiere capacidades avanzadas de LLM.
Caso práctico: asistente de investigación multidisciplinar
llamar la atención sobre algo: ¿Cuáles son las repercusiones económicas y medioambientales de la adopción de energías renovables en Europa?
Procesos del sistema (flujo de trabajo multiagente)::
- Agente 1Utilizar consultas SQL para recuperar datos estadísticos de bases de datos económicas.
- Agente 2Búsqueda de artículos académicos relevantes mediante herramientas de búsqueda semántica.
- Agente 3Búsqueda en Internet de las últimas noticias y actualizaciones políticas sobre energías renovables.
- Agente 4: Consulte el sistema de recomendación para que le sugiera contenidos pertinentes, como informes o comentarios de expertos.
receptivo::
Respuesta integrada:: "La adopción de energías renovables en Europa ha permitido reducir las emisiones de gases de efecto invernadero en 20% durante la última década, según el informe sobre la política de la UE. En el plano económico, las inversiones en energías renovables han creado alrededor de 1,2 millones de puestos de trabajo, con un crecimiento significativo en los sectores solar y eólico. Recientes investigaciones académicas también han puesto de relieve posibles compensaciones en términos de estabilidad de la red y costes de almacenamiento de energía."
4.3 Sistema GAR jerárquico basado en agentes
El sistema RAG basado en agentes jerárquicos [17] utiliza un enfoque estructurado y multinivel para la recuperación y el procesamiento de la información, lo que mejora la eficacia y la toma de decisiones estratégicas (como se muestra en la Figura 13). Los agentes se organizan en una estructura jerárquica, en la que los agentes superiores supervisan y guían a los inferiores. Esta estructura permite la toma de decisiones a varios niveles y garantiza que las consultas sean gestionadas por los recursos más adecuados.

Figura 13: Ilustración del GAR jerárquico agéntico
flujo de trabajo
- Recibo de consultaEl usuario envía una consulta, que es recibida por el agente de nivel superior, que se encarga de la evaluación inicial y la puesta en servicio.
- toma de decisiones estratégicasEl agente de nivel superior evalúa la complejidad de la consulta y decide a qué agentes subordinados o fuentes de datos dar prioridad. En función del dominio de la consulta, determinadas bases de datos, API o herramientas de búsqueda pueden considerarse más fiables o pertinentes.
- Delegación en un subordinadoAgentes de nivel superior: los agentes de nivel superior asignan tareas a agentes de nivel inferior especializados en determinados métodos de recuperación (por ejemplo, bases de datos SQL, búsquedas en Internet o sistemas propietarios). Estos agentes realizan las tareas asignadas de forma independiente.
- Polimerización y síntesisLos agentes de alto nivel recopilan e integran los resultados de los agentes subordinados, consolidando la información en respuestas coherentes.
- Entrega de la respuestaLa respuesta final, sintetizada, se devuelve al usuario, garantizando que la respuesta es a la vez exhaustiva y contextualmente pertinente.
Principales características y ventajas
- Priorización estratégicaAgentes de alto nivel: los agentes de alto nivel pueden priorizar las fuentes de datos o las tareas en función de la complejidad de la consulta, la fiabilidad o el contexto.
- escalabilidadLa asignación de tareas a varios niveles de agentes permite gestionar consultas muy complejas o polifacéticas.
- Mayor capacidad de decisiónSupervisión estratégica: los agentes de alto nivel aplican una supervisión estratégica para mejorar la precisión general y la coherencia de la respuesta.
desafío
- Complejidad de la coordinaciónEl mantenimiento de una comunicación sólida entre agentes a varios niveles puede aumentar la sobrecarga de coordinación.
- Asignación de recursosEl problema: no es fácil distribuir eficazmente las tareas entre los niveles evitando los cuellos de botella.
Caso práctico: sistema de análisis financiero
llamar la atención sobre algoEl Presidente: ¿Cuáles son las opciones de inversión en energías renovables según las tendencias actuales del mercado?
Procesos del sistema (flujo de trabajo jerárquico de agentes)::
- agente en la cima de la jerarquía: Evaluar la complejidad de las consultas y dar prioridad a las bases de datos financieros y los indicadores económicos fiables frente a las fuentes de datos menos validadas.
- Agentes de nivel medioRecuperación de datos de mercado en tiempo real (por ejemplo, cotizaciones bursátiles, rendimiento del sector) a partir de API propias y bases de datos SQL estructuradas.
- Agentes de bajo nivel: Realice búsquedas en Internet de anuncios y políticas recientes, y consulte los sistemas de referencia para conocer las opiniones de los expertos y los análisis de las noticias.
- Polimerización y síntesisResultados indirectos de alto nivel que integran datos cuantitativos con perspectivas políticas.
receptivo::
Respuesta integrada: "Según los datos actuales del mercado, las acciones de las energías renovables han crecido 15% en el último trimestre, impulsadas sobre todo por las políticas gubernamentales de apoyo y el gran interés de los inversores. Los analistas creen que es probable que los sectores eólico y solar sigan ganando impulso, mientras que tecnologías emergentes como el hidrógeno verde tienen un riesgo moderado pero pueden ofrecer altos rendimientos."
4.4 RAG de corrección por delegación
La GAR correctiva [32] [33] introduce la capacidad de autocorregir los resultados de la recuperación, mejorando la utilización de los documentos y la calidad de la generación de respuestas (como se muestra en la Figura 14). Al integrar agentes inteligentes en el flujo de trabajo, la GAR correctiva [32] [33] garantiza el perfeccionamiento iterativo de los documentos contextuales y las respuestas para minimizar los errores y maximizar la relevancia.

Figura 14: Visión general de los GAR correctivos agénticos
Corregir la idea central del GAREl principio básico de la GAR correctiva reside en su capacidad para evaluar dinámicamente los documentos recuperados, realizar acciones correctivas y refinar la consulta para mejorar la calidad de la respuesta generada. La GAR correctiva ajusta su metodología del siguiente modo:
- Evaluación de la pertinencia de los documentosEvaluación de la pertinencia: los documentos recuperados son evaluados por un agente de evaluación de la pertinencia. Los documentos por debajo del umbral de relevancia activan una etapa de corrección.
- Perfeccionamiento y mejora de la investigaciónLas consultas se refinan mediante un agente de refinamiento de consultas que utiliza la comprensión semántica para optimizar la recuperación y obtener mejores resultados.
- Recuperación dinámica de fuentes externasCuando el contexto es insuficiente, el agente externo de recuperación de conocimientos realiza una búsqueda en la web o accede a fuentes de datos alternativas para completar los documentos recuperados.
- síntesis de respuestasToda la información validada y refinada se transmite al agente de síntesis de respuesta para la generación de la respuesta final.
flujo de trabajoEl sistema correctivo RAG se basa en cinco agentes clave:
- agente de búsqueda contextualResponsable de recuperar el documento de contexto inicial de la base de datos vectorial.
- Agente de evaluación de la pertinenciaEvaluación de la pertinencia de los documentos recuperados y señalamiento de los documentos irrelevantes o ambiguos para la adopción de medidas correctoras.
- Agente refinador de consultas: Reescritura de consultas para mejorar la eficacia de la recuperación y uso de la comprensión semántica para optimizar los resultados.
- Agente externo de recuperación de conocimientos: Realiza búsquedas en Internet o accede a fuentes de datos alternativas cuando la documentación contextual sea insuficiente.
- Agente de síntesis de respuestaIntegrar toda la información validada en una respuesta coherente y precisa.
Principales características y ventajas:
- Corrección iterativa: Garantice una alta precisión de las respuestas identificando y corrigiendo dinámicamente los resultados de búsqueda irrelevantes o ambiguos.
- Adaptación dinámicaIntegración de la búsqueda web en tiempo real y el refinamiento de consultas para mejorar la precisión de la recuperación.
- Proxy ModularCada agente realiza tareas especializadas para garantizar la eficacia y la escalabilidad de las operaciones.
- Garantías de hecho: La corrección del GAR minimiza el riesgo de alucinaciones o informaciones erróneas al validar todos los contenidos recuperados y generados.
Caso práctico: asistente de investigación académica
llamar la atención sobre algo: ¿Cuáles son los últimos descubrimientos de la investigación sobre IA generativa?
Procesos del sistema (corrección de los flujos de trabajo RAG)::
- Presentación de consultasLos usuarios envían consultas al sistema.
- búsqueda contextual::
- agente de búsqueda contextualRecuperar documentos iniciales de la base de datos de artículos publicados sobre IA generativa.
- Los documentos recuperados pasan al siguiente paso para su evaluación.
- Evaluación de la pertinencia:
- Agente de evaluación de la pertinenciaEvaluar la correspondencia entre el documento y la consulta.
- Clasifica los documentos como relevantes, ambiguos o irrelevantes. Los documentos irrelevantes se marcan para su corrección.
- Medidas correctoras (en caso necesario):
- Agente refinador de consultasReescritura de consultas para mejorar la especificidad.
- Agente externo de recuperación de conocimientosRealizar búsquedas en Internet para obtener documentos e informes adicionales de fuentes externas.
- Síntesis de respuesta.
- Agente de síntesis de respuestaIntegre los documentos validados en resúmenes completos y detallados.
Respuesta.
Respuesta integrada: "Los resultados recientes de la investigación en IA generativa incluyen modelos de difusión, aprendizaje por refuerzo en tareas de texto a vídeo y avances en técnicas de optimización para el entrenamiento de modelos a gran escala. Consulte las investigaciones presentadas en NeurIPS 2024 y AAAI 2025 para obtener más detalles."
4.5 GAR adaptativa basada en agentes
La Generación Aumentada de Recuperación Adaptativa (RAG Adaptativa) [34] mejora la flexibilidad y eficiencia de los Modelos de Lenguaje Amplio (LLM) adaptando dinámicamente la estrategia de procesamiento de consultas en función de la complejidad de la consulta entrante. A diferencia de los flujos de trabajo de recuperación estáticos, la RAG adaptativa [35] emplea clasificadores para analizar la complejidad de la consulta y determinar el enfoque más adecuado, que puede ir desde la recuperación en un solo paso hasta el razonamiento en varios pasos, o incluso omitir por completo la recuperación en el caso de consultas sencillas, como se muestra en la Figura 15.

Figura 15: Visión general de la GAR adaptativa antigénica
La idea central del GAR adaptativo El principio básico de la GAR adaptativa reside en su capacidad para ajustar dinámicamente la estrategia de recuperación en función de la complejidad de la consulta. La GAR adaptativa ajusta su método del siguiente modo:
- consulta simplePara las preguntas factuales que requieren una recuperación adicional (por ejemplo, "¿Cuál es el punto de ebullición del agua?"), el sistema genera respuestas directamente utilizando el conocimiento preexistente. Para las preguntas sobre hechos que requieren una búsqueda adicional (por ejemplo, "¿Cuál es el punto de ebullición del agua?"), el sistema genera las respuestas directamente utilizando los conocimientos preexistentes.
- consulta simplePara tareas moderadamente complejas que requieren un contexto mínimo (por ejemplo, "¿Cuál es el estado de mi última factura de la luz?) el sistema realiza una búsqueda en un solo paso para obtener los detalles pertinentes.
- consulta complejaPara las consultas de varios niveles que requieren un razonamiento iterativo (por ejemplo, "¿Cómo ha cambiado la población de la ciudad X en la última década y cuáles han sido los factores que han contribuido a ello?) el sistema utiliza la búsqueda en varios pasos, refinando progresivamente los resultados intermedios para proporcionar respuestas completas.
flujo de trabajoEl sistema Adaptive RAG se basa en tres componentes principales:
- Función de clasificador.
- Un modelo lingüístico más pequeño analiza las consultas para predecir su complejidad.
- El clasificador se entrena utilizando conjuntos de datos etiquetados automáticamente a partir de resultados de modelos anteriores y patrones de consulta.
- Selección dinámica de estrategias.
- Para consultas sencillas, el sistema evita búsquedas innecesarias y genera respuestas directamente utilizando LLM.
- Para consultas sencillas, utiliza un proceso de búsqueda de un solo paso para obtener el contexto pertinente.
- Para consultas complejas, activa la recuperación en varios pasos para garantizar un refinamiento iterativo y un razonamiento mejorado.
- Integración LLM.
- El LLM integra la información recuperada en una respuesta coherente.
- La interacción iterativa entre LLM y el clasificador permite refinar consultas complejas.
Principales características y ventajas.
- Adaptación dinámica:: Adaptación de las estrategias de recuperación a la complejidad de la consulta para optimizar la eficiencia computacional y la precisión de la respuesta.
- Eficacia de los recursosEl objetivo: minimizar la sobrecarga innecesaria en las consultas sencillas, garantizando al mismo tiempo un tratamiento exhaustivo de las consultas complejas.
- Mayor precisión:: El refinamiento iterativo garantiza que las consultas complejas se resuelvan con gran precisión.
- destreza: Puede ampliarse para integrar rutas adicionales, como herramientas específicas del dominio o API externas.
Casos prácticos. Asistente de atención al cliente
Consejo. ¿Por qué se retrasa mi paquete y qué opciones tengo?
Procesos del sistema (flujo de trabajo RAG adaptable).
- Categoría de consulta.
- El clasificador analiza la consulta y determina que se trata de una consulta compleja que requiere un razonamiento de varios pasos.
- Selección dinámica de estrategias.
- El sistema activa un proceso de recuperación en varios pasos basado en la clasificación de la complejidad.
- Búsqueda en varios pasos.
- Recuperar los datos de seguimiento de la base de datos de pedidos.
- Obtenga actualizaciones de estado en tiempo real de la API de Courier.
- Realice una búsqueda en Internet para conocer los factores externos, como las condiciones meteorológicas o las perturbaciones locales.
- Síntesis de respuesta.
- LLM integra toda la información recuperada en una respuesta completa y procesable.
Respuesta.
Respuesta integradaSu paquete se ha retrasado debido a las condiciones meteorológicas adversas en su zona. Actualmente se encuentra en el centro de distribución local y se espera que llegue en un plazo de 2 días. Como alternativa, puede optar por recogerlo en las instalaciones".
4.6 GAR basados en agentes gráficos
4.6.1 Agente-G: un marco basado en agentes para los GAR de grafos
Agent-G [8] presenta una innovadora arquitectura basada en agentes que combina bases de conocimiento de grafos con la recuperación de documentos no estructurados. Al combinar fuentes de datos estructuradas y no estructuradas, este marco mejora el razonamiento y la precisión de recuperación de los sistemas de Generación Aumentada de Recuperación (RAG). Emplea bibliotecas modulares de recuperadores, interacciones dinámicas entre agentes y bucles de retroalimentación para garantizar unos resultados de alta calidad, como se muestra en la Figura 16.

Figura 16: Visión general de Agent-G: marco agenético para Graph RAG
La idea central del Agente-G El principio básico de Agent-G reside en su capacidad para asignar dinámicamente tareas de recuperación a agentes especializados que utilizan bases de conocimiento de grafos y archivos de texto:
- base gráfica de conocimientosUtilizar datos estructurados para extraer relaciones, jerarquías y conexiones (por ejemplo, mapeo de enfermedad a síntoma en el ámbito médico).
- documento no estructurado:: Los sistemas tradicionales de recuperación de texto proporcionan información contextual para complementar los datos gráficos.
- Módulo de críticaEvaluación: evalúa la pertinencia y la calidad de la información recuperada para garantizar su concordancia con la consulta.
- bucle de retroalimentación:: Perfeccionamiento de la recuperación y la síntesis mediante validación iterativa y nuevas consultas.
flujo de trabajoEl sistema : Agent-G se basa en cuatro componentes principales:
- Biblioteca Retriever.
- Un conjunto de agentes modulares especializados en la recuperación de datos basados en grafos o no estructurados.
- El agente selecciona dinámicamente las fuentes pertinentes en función de los requisitos de la consulta.
- Módulo de crítica.
- Validar la pertinencia y calidad de los datos recuperados.
- Marcar los resultados de baja confianza para volver a recuperarlos o perfeccionarlos.
- Interacción dinámica entre agentes.
- Los agentes de tareas específicas colaboran para integrar distintos tipos de datos.
- Garantizar la recuperación y síntesis coordinadas entre fuentes de figuras y textos.
- Integración LLM.
- Sintetizar los datos validados en una respuesta coherente.
- Los comentarios iterativos del módulo de crítica garantizan la concordancia con la intención de la consulta.
Principales características y ventajas.
- razonamiento mejorado: Combinación de relaciones estructuradas en grafos e información contextual de documentos no estructurados.
- Adaptación dinámica:: Adaptación dinámica de las estrategias de búsqueda a los requisitos de la consulta.
- Mayor precisiónEl módulo Crítica reduce el riesgo de que aparezcan datos irrelevantes o de baja calidad en la respuesta.
- Modularidad escalable:: Soporte para añadir nuevos agentes que realicen tareas especializadas para una mayor escalabilidad.
Casos prácticos: Diagnóstico médico
Consejo. ¿Cuáles son los síntomas habituales de la diabetes de tipo 2 y qué relación guardan con las cardiopatías?
Procesos del sistema (flujo de trabajo del Agente-G).
- Recepción y distribución de consultasEl sistema recibe consultas e identifica la necesidad de utilizar tanto datos estructurados en grafos como datos no estructurados para responder plenamente a la pregunta.
- Buscador de cartas.
- Extracción de la relación entre la diabetes de tipo 2 y las cardiopatías a partir del grafo de conocimiento médico.
- Identificar factores de riesgo comunes, como la obesidad y la hipertensión, explorando jerarquías y relaciones gráficas.
- Recuperador de documentos.
- Recuperar descripciones de síntomas de diabetes tipo 2 (por ejemplo, aumento de la sed, micción frecuente, fatiga) de la literatura médica.
- Añada información contextual para complementar la información basada en gráficos.
- Módulo de crítica.
- Evaluar la pertinencia y la calidad de los datos gráficos y documentales recuperados.
- Marcar los resultados poco fiables para afinarlos o volver a consultarlos.
- síntesis de respuestasLLM: LLM integra los datos de validación del recuperador de gráficos y del recuperador de documentos en una respuesta coherente que garantiza la alineación con la intención de la consulta.
Respuesta.
Respuesta integrada: "Los síntomas de la diabetes de tipo 2 incluyen aumento de la sed, micción frecuente y fatiga. Los estudios han demostrado una correlación 50% entre la diabetes y las cardiopatías, principalmente a través de factores de riesgo compartidos como la obesidad y la hipertensión arterial."
4.6.2 GeAR: Agente de Aumento de Grafos para la Generación de Aumentos de Recuperación
GeAR [36] introduce un marco basado en agentes que mejora los sistemas tradicionales de generación aumentada de recuperación (RAG) mediante la integración de mecanismos de recuperación basados en grafos. Al utilizar técnicas de extensión de grafos y una arquitectura basada en agentes, GeAR aborda los retos que plantean los escenarios de recuperación multisalto y mejora la capacidad del sistema para gestionar consultas complejas, como se muestra en la Figura 17.

Figura 17: Visión general de GeAR: Graph-Enhanced Agent for Retrieval-Augmented Generation[36]
- extensión gráficaMejora los recuperadores básicos tradicionales (por ejemplo, BM25) ampliando el proceso de recuperación para incluir datos estructurados en grafos, lo que permite al sistema capturar relaciones y dependencias complejas entre entidades.
- marco de representaciónEl sistema de recuperación de datos: integra una arquitectura basada en agentes que utiliza extensiones de grafos para gestionar las tareas de recuperación con mayor eficacia, lo que permite una toma de decisiones dinámica y autónoma durante el proceso de recuperación.
flujo de trabajoEl sistema GeAR funciona a través de los siguientes componentes:
- Figura Módulo de ampliación.
- La integración de datos basados en gráficos en el proceso de recuperación permite al sistema tener en cuenta las relaciones entre entidades durante el proceso de recuperación.
- Mejorar la capacidad del buscador básico para gestionar consultas multisalto ampliando el espacio de búsqueda para incluir entidades conectadas.
- Recuperación basada en agentes.
- Se utiliza un marco de agentes para gestionar el proceso de recuperación, lo que permite a los agentes seleccionar y combinar dinámicamente estrategias de recuperación basadas en la complejidad de la consulta.
- Los agentes pueden decidir de forma autónoma una ruta de búsqueda utilizando extensiones de grafos para mejorar la relevancia y precisión de la información recuperada.
- Integración LLM.
- Combinar la información recuperada con las ventajas de las extensiones de grafos con las capacidades de Large Language Modelling (LLM) para generar respuestas coherentes y contextualmente relevantes.
- Esta integración garantiza que el proceso de generación se inspire tanto en documentos no estructurados como en datos gráficos estructurados.
Principales características y ventajas.
- Búsqueda multisalto mejoradaExtensiones de grafos: las extensiones de grafos de GeAR permiten al sistema gestionar consultas complejas que requieren razonar sobre múltiples piezas de información interrelacionadas.
- Toma de decisiones por delegaciónEl marco proxy permite una selección dinámica y autónoma de las estrategias de recuperación, lo que mejora la eficacia y la pertinencia.
- Mayor precisión:: Al integrar datos gráficos estructurados, GeAR mejora la precisión de la información recuperada para generar respuestas más precisas y adecuadas al contexto.
- escalabilidadLa naturaleza modular del marco de agentes permite integrar estrategias de búsqueda y fuentes de datos adicionales en función de las necesidades.
Caso práctico: concurso multisalto
Consejo. ¿Quién influyó en el mentor de J.K. Rowling?
Procesos del sistema (flujo de trabajo GeAR).
- agente en la cima de la jerarquía: Evalúa la naturaleza multisalto de la consulta y determina la necesidad de combinar la expansión de grafos y la recuperación de documentos para responder a la pregunta.
- Figura Módulo de ampliación.
- Identifica al mentor de J.K. Rowling como la entidad clave de la consulta.
- Rastrear las influencias literarias de los mentores explorando los datos de la estructura del Mapa de relaciones literarias.
- Recuperación basada en agentes.
- Un agente selecciona de forma autónoma una ruta de búsqueda ampliada del grafo para recopilar información relevante sobre el impacto del mentor.
- Integrar contexto adicional para detalles no estructurados de los mentores y sus influencias mediante la consulta de fuentes de datos textuales.
- síntesis de respuestasUtilizar LLM para combinar la información del proceso de recuperación de gráficos y documentos con el fin de generar una respuesta que refleje con precisión las complejas relaciones de la consulta.
Respuesta.
Respuesta integradaEl mentor de J.K. Rowling, [nombre del mentor], recibió una gran influencia de [nombre del autor], conocido por su [obra famosa o género]. Esta conexión pone de relieve las relaciones en cascada de la historia literaria, en la que las ideas influyentes suelen transmitirse a través de múltiples generaciones de escritores."
4.7 Flujos de documentos en los GAR basados en agentes
Flujos de trabajo de documentos agénticos (ADW)[37] amplía el paradigma tradicional de la Generación Aumentada de Recuperación (RAG) automatizando el trabajo del conocimiento de extremo a extremo. Estos flujos de trabajo orquestan procesos complejos centrados en documentos que integran el análisis sintáctico, la recuperación, el razonamiento y la producción estructurada de documentos con agentes inteligentes (véase la Figura 18).
flujo de trabajo
- Análisis sintáctico de documentos y estructuración de la información::
- Utilice herramientas de nivel empresarial (por ejemplo, LlamaParse) para analizar documentos y extraer campos de datos relevantes como números de factura, fechas, información sobre proveedores, entradas y condiciones de pago.
- Organizar los datos estructurados para su posterior tratamiento.
- Mantenimiento del estado entre procesos::
- El sistema mantiene el estado del contexto del documento en cuestión, garantizando la coherencia y pertinencia en flujos de trabajo de varios pasos.
- Siga el progreso de los documentos a través de las distintas fases de tramitación.
- recuperación de conocimientos::
- Recuperar referencias relevantes de bases de conocimiento externas (por ejemplo, LlamaCloud) o índices vectoriales.
- Obtenga orientación en tiempo real y específica de cada ámbito para mejorar la toma de decisiones.
- Programación basada en agentes::
- Los agentes inteligentes aplican reglas de negocio, realizan razonamientos multisalto y generan recomendaciones procesables.
- Orqueste componentes como analizadores sintácticos, recuperadores y API externas para una integración perfecta.
- Generación de resultados procesables::
- El resultado se presenta en un formato estructurado, adaptado a casos de uso específicos.
- Sintetizar las recomendaciones y las ideas extraídas en informes concisos y prácticos.

Figura 18: Visión general de los flujos de trabajo de documentos agénticos (ADW) [37]
Caso práctico: Flujo de trabajo de pago de facturas
llamar la atención sobre algoGenerar un informe de aviso de pago basado en las facturas presentadas y las condiciones del contrato de proveedor correspondiente.
Procesos del sistema (flujo de trabajo ADW)::
- Análisis sintáctico de facturas para extraer detalles clave como el número de factura, la fecha, la información del proveedor, las entradas y las condiciones de pago.
- Recuperar los contratos de proveedores adecuados para validar las condiciones de pago e identificar los descuentos aplicables o los requisitos de cumplimiento.
- Genere un informe de recomendación de pago que incluya el importe original adeudado, posibles descuentos por pronto pago, análisis del impacto presupuestario y acciones estratégicas de pago.
receptivoRespuesta consolidada: "La factura INV-2025-045 por importe de $15.000,00 ha sido procesada. Si el pago se realiza antes del 2025-04-10, se dispone de un descuento por pronto pago de 2%, lo que reduce el importe adeudado a $14.700,00.Dado que el subtotal excede de $10.000,00, se ha aplicado un descuento por pronto pago de 5%. Se recomienda aprobar el pago anticipado para ahorrar 2% y garantizar la asignación oportuna de fondos para las próximas fases del proyecto."
Principales características y ventajas
- MantenimientoSeguimiento del contexto del documento y de las fases del flujo de trabajo para garantizar la coherencia entre los procesos.
- programación multipasoGestión de flujos de trabajo complejos en los que intervienen múltiples componentes y herramientas externas.
- Inteligencia en dominios específicos: Aplicar normas y directrices empresariales adaptadas para un asesoramiento preciso.
- escalabilidad: Admite el procesamiento de documentos a gran escala con integración de agentes modular y dinámica.
- Aumentar la productividad: Automatice las tareas repetitivas al tiempo que mejora la experiencia humana en la toma de decisiones.
4.8 Análisis comparativo de los marcos GAR basados en agentes
La Tabla 2 ofrece un análisis comparativo exhaustivo de tres marcos arquitectónicos: GAR tradicional, GAR basado en agentes y flujo de trabajo documental basado en agentes (ADW). El análisis pone de relieve sus respectivos puntos fuertes y débiles, así como los escenarios más adecuados, proporcionando valiosas perspectivas para su aplicación en diferentes casos de uso.
Tabla 2: Análisis comparativo: GAR tradicional frente a GAR basado en agentes frente a flujo de trabajo documental basado en agentes (ADW)
| caracterización | GAR tradicional | Proxy RAG | Flujo de documentos basado en agentes (ADW) |
|---|---|---|---|
| recuento (por ejemplo, resultados de las elecciones) | Tareas aisladas de recuperación y generación | Colaboración y razonamiento multiagente | Flujos de trabajo integrales centrados en los documentos |
| Mantenimiento del contexto | limitaciones | Realización mediante módulos de memoria | Mantener el estado en un flujo de trabajo de varios pasos |
| Adaptación dinámica | mínimo | su (honorífico) | Adaptado al flujo de trabajo documental |
| Organización del flujo de trabajo | hiato | Orquestar tareas multiagente | Procesamiento integrado de documentos en varios pasos |
| Utilización de herramientas/API externas | Integración básica (por ejemplo, herramientas de búsqueda) | Ampliación mediante herramientas (por ejemplo, API y bases de conocimientos) | Profunda integración con reglas de negocio y herramientas específicas del sector |
| escalabilidad | Limitado a pequeños conjuntos de datos o consultas | Sistema multiagente escalable | Flujos de trabajo empresariales multidisciplinares escalables |
| inferencia compleja | Básico (por ejemplo, un simple cuestionario) | Razonamiento multipaso mediante agentes | Razonamiento estructurado entre documentos |
| aplicación principal | Sistema de preguntas y respuestas, recuperación de conocimientos | Conocimiento y razonamiento multidisciplinares | Revisión de contratos, tramitación de facturas, análisis de reclamaciones |
| vanguardia | Configuración rápida y sencilla | Alta precisión, razonamiento colaborativo | Automatización de extremo a extremo, inteligencia específica de dominio |
| desafío | Escasa comprensión del contexto | Complejidad de la coordinación | Sobrecarga de recursos, normalización de campos |
El análisis comparativo pone de relieve la trayectoria evolutiva de la GAR tradicional a la GAR basada en agentes y al flujo de trabajo documental basado en agentes (ADW). Mientras que la RAG tradicional ofrece las ventajas de la simplicidad y la facilidad de despliegue para tareas básicas, la RAG basada en agentes introduce capacidades de razonamiento mejoradas y escalabilidad a través de la colaboración multiagente.ADW se basa en estos avances proporcionando flujos de trabajo robustos y centrados en documentos que facilitan la automatización de extremo a extremo y la integración con procesos específicos del dominio. Comprender los puntos fuertes y las limitaciones de cada marco es fundamental para seleccionar la arquitectura que mejor se adapte a las necesidades específicas de la aplicación y a los requisitos operativos.
5 Aplicación del RAG Proxy
Los sistemas de Generación Aumentada de Recuperación (RAG) basados en agentes demuestran un potencial transformador en diversos ámbitos. Al combinar la recuperación de datos en tiempo real, las capacidades generativas y la toma de decisiones autónoma, estos sistemas abordan retos complejos, dinámicos y multimodales. Esta sección explora las principales aplicaciones de la GAR basada en agentes y detalla cómo estos sistemas están dando forma a ámbitos como la atención al cliente, la sanidad, las finanzas, la educación, los flujos de trabajo jurídicos y las industrias creativas.
5.1 Atención al cliente y asistentes virtuales
Los sistemas RAG basados en agentes están revolucionando la atención al cliente al permitir la resolución de consultas en tiempo real y en función del contexto. Los chatbots y asistentes virtuales tradicionales suelen basarse en bases de conocimiento estáticas, lo que da lugar a respuestas genéricas u obsoletas. En cambio, los sistemas RAG basados en agentes recuperan dinámicamente la información más relevante, se adaptan al contexto del usuario y generan respuestas personalizadas.
Caso práctico: Mejora de las ventas de anuncios en Twitch [38]
Por ejemplo, Twitch utiliza un flujo de trabajo tipo agencia con RAG en Amazon Bedrock para agilizar la venta de anuncios. El sistema recupera dinámicamente los datos de los anunciantes, el rendimiento histórico de las campañas y las estadísticas de audiencia para generar propuestas publicitarias detalladas, lo que mejora notablemente la eficiencia operativa.
Beneficios clave:
- Mejorar la calidad de la respuestaLas respuestas personalizadas y contextualizadas mejoran el compromiso del usuario.
- Eficacia operativa: Reduce la carga de trabajo de los agentes de asistencia manual automatizando las consultas complejas.
- Adaptabilidad en tiempo real: Integre dinámicamente datos en evolución, como cortes de servicio en tiempo real o actualizaciones de precios.
5.2 Tratamiento médico y medicina personalizada
En la atención sanitaria, combinar datos específicos del paciente con las últimas investigaciones médicas es fundamental para tomar decisiones con conocimiento de causa. Los sistemas RAG basados en agentes lo hacen posible recuperando en tiempo real directrices clínicas, bibliografía médica e historiales de pacientes para ayudar a los médicos en el diagnóstico y la planificación del tratamiento.
Casos prácticos: resumen de casos de pacientes [39]
Los sistemas RAG basados en agentes se han aplicado para generar resúmenes de casos de pacientes. Por ejemplo, al integrar las historias clínicas electrónicas (HCE) y la bibliografía médica actualizada, el sistema genera resúmenes exhaustivos para los médicos, de modo que puedan tomar decisiones más rápidas y fundamentadas.
Beneficios clave:
- Atención personalizadaAdaptar las recomendaciones a las necesidades de cada paciente.
- eficacia del tiempoAgilice la recuperación de estudios relevantes y ahorre un tiempo valioso a los profesionales sanitarios.
- precisiónRecomendación: garantizar que las recomendaciones se basan en las pruebas más recientes y en parámetros específicos de cada paciente.
5.3 Análisis jurídico y contractual
Los sistemas RAG basados en agentes están redefiniendo la forma en que se ejecutan los flujos de trabajo jurídicos, proporcionando herramientas para el análisis rápido de documentos y la toma de decisiones.
Casos prácticos: revisión de contratos [40]
Un sistema RAG de tipo agente jurídico analiza los contratos, extrae las cláusulas clave e identifica los riesgos potenciales. Al combinar capacidades de búsqueda semántica y mapeo de conocimientos jurídicos, automatiza el engorroso proceso de revisión de contratos, garantizando el cumplimiento y mitigando los riesgos.
Beneficios clave:
- identificación de riesgos: Marca automáticamente las cláusulas que se desvían de las cláusulas estándar.
- eficacia: Reducir el tiempo dedicado al proceso de revisión de contratos.
- escalabilidad: Gestión de un gran número de contratos al mismo tiempo.
5.4 Análisis financiero y de riesgos
Los sistemas RAG basados en agentes están transformando el sector financiero al proporcionar información en tiempo real para la toma de decisiones de inversión, el análisis de mercados y la gestión de riesgos. Estos sistemas integran flujos de datos en tiempo real, tendencias históricas y modelos predictivos para producir resultados procesables.
Casos prácticos: tramitación de siniestros de automóviles [41]
En los seguros de automóviles, el sistema RAG basado en agentes automatiza la tramitación de siniestros. Por ejemplo, al recuperar los datos de la póliza y combinarlos con los de los accidentes, genera asesoramiento sobre siniestros al tiempo que garantiza el cumplimiento de los requisitos normativos.
Beneficios clave:
- análisis en tiempo real: Proporciona información basada en datos de mercado en tiempo real.
- Reducción de riesgos: Identifique los riesgos potenciales mediante análisis predictivos y razonamiento en varios pasos.
- Mayor capacidad de decisión: Combine datos históricos y en tiempo real para desarrollar una estrategia global.
5,5 Educación
La educación es otro campo en el que los sistemas GAR basados en agentes han avanzado mucho. Estos sistemas permiten el aprendizaje adaptativo generando explicaciones, materiales didácticos y comentarios que se adaptan al progreso y las preferencias del alumno.
Casos prácticos: generación de artículos de investigación [42]
En la enseñanza superior, el GAR basado en agentes se ha utilizado para ayudar a los investigadores sintetizando los hallazgos clave de múltiples fuentes. Por ejemplo, los investigadores que pregunten "¿Cuáles son los últimos avances en computación cuántica?" recibirán un resumen conciso con referencias, lo que mejorará la calidad y eficacia de su trabajo.
Beneficios clave:
- Itinerarios de aprendizaje personalizadosAdaptar los contenidos a las necesidades y niveles de rendimiento de cada alumno.
- Interacciones atractivas: Ofrezca explicaciones interactivas y comentarios personalizados.
- escalabilidad: Admite la implantación a gran escala en diversos entornos educativos.
5.6 Aplicaciones de la mejora gráfica en flujos de trabajo multimodales
Graph Enhanced Agent-based RAG (GEAR) combina estructuras gráficas y mecanismos de recuperación y resulta especialmente eficaz en flujos de trabajo multimodales en los que las fuentes de datos interconectadas son fundamentales.
Caso práctico: generación de estudios de mercado
GEAR es capaz de sintetizar texto, imágenes y vídeo para utilizarlos en campañas de marketing. Por ejemplo, la consulta "¿Cuáles son las tendencias emergentes en productos ecológicos?" genera un informe detallado con las preferencias de los clientes, análisis de la competencia y contenido multimedia.
Beneficios clave:
- capacidad multimodal: Integre datos de texto, imagen y vídeo para obtener un resultado completo.
- Aumento de la creatividad: Generar ideas y soluciones innovadoras para el marketing y el entretenimiento.
- Adaptación dinámica: Adaptarse a las tendencias cambiantes del mercado y a las necesidades de los clientes.
Los sistemas GAR basados en agentes se utilizan en una amplia gama de aplicaciones, lo que demuestra su versatilidad y potencial transformador. Desde la atención al cliente personalizada hasta la educación adaptativa y los flujos de trabajo multimodales mejorados con grafos, estos sistemas abordan retos complejos, dinámicos y que requieren muchos conocimientos. Al integrar recuperación, inteligencia generativa e inteligencia de agentes, los sistemas GAR basados en agentes están allanando el camino para la próxima generación de aplicaciones de IA.
6 Herramientas y marcos para la GAR basada en agentes
Los sistemas de generación mejorada por recuperación (RAG) basados en agentes representan una evolución significativa en la combinación de recuperación, generación e inteligencia de agentes. Estos sistemas amplían las capacidades de la RAG tradicional integrando la toma de decisiones, la reconstrucción de consultas y los flujos de trabajo adaptativos. Las siguientes herramientas y marcos proporcionan un potente soporte para el desarrollo de sistemas RAG basados en agentes que responden a los complejos requisitos de las aplicaciones del mundo real.
Herramientas y marcos clave:
- LangChain y LangGraphLangChain [43] proporciona componentes modulares para construir pipelines RAG, integrando a la perfección recuperadores, generadores y herramientas externas.LangGraph complementa esto introduciendo procesos basados en grafos que soportan bucles, persistencia de estados e interacciones humano-ordenador, permitiendo sofisticados mecanismos de orquestación y autocorrección en sistemas de agentes.
- LlamaIndexEl flujo de trabajo documental basado en agentes (ADW) de LlamaIndex [44] permite la automatización integral del procesamiento, la recuperación y el razonamiento estructurado de documentos. Introduce una arquitectura de metaagentes en la que los subagentes gestionan conjuntos más pequeños de documentos y tareas como el análisis de conformidad y la comprensión contextual se coordinan a través de agentes de nivel superior.
- Transformers de Cara Abrazada y QdrantHugging Face [45] proporciona modelos preentrenados para tareas de incrustación y generativas, mientras que Qdrant [46] mejora el flujo de trabajo de recuperación con capacidades de búsqueda vectorial adaptativa, lo que permite a los agentes optimizar el rendimiento cambiando dinámicamente entre métodos de vectores dispersos y densos.
- CrewAI y AutoGencrewAI [47] admite procesos jerárquicos y secuenciales, potentes sistemas de memoria e integración de herramientas. ag2 [48] (antes conocido como AutoGen [49, 50]) destaca en la colaboración multiagente con generación avanzada de código, ejecución de herramientas y apoyo a la toma de decisiones.
- Enjambre OpenAI: un marco educativo diseñado para permitir una orquestación multiagente ergonómica y ligera [51] con énfasis en la autonomía de los agentes y la colaboración estructurada.
- GAR basada en agentes con IA de vérticesVertex AI [52], desarrollado por Google, se integra a la perfección con la Retrieval Augmentation Generation (RAG) basada en agentes para proporcionar una plataforma que permita construir, desplegar y escalar modelos de aprendizaje automático al tiempo que se aprovechan las capacidades avanzadas de la IA para obtener flujos de trabajo de recuperación y toma de decisiones potentes y conscientes del contexto.
- Amazon Bedrock para GAR basados en agentesAmazon Bedrock [38] proporciona una potente plataforma para implementar flujos de trabajo de generación mejorada de recuperación (RAG) basados en agentes.
- IBM Watson y los GAR basados en agenteswatsonx.ai [53] de IBM permite construir sistemas RAG basados en agentes, por ejemplo, utilizando el modelo Granite-3-8B-Instruct para responder a consultas complejas y mejorar la precisión de las respuestas integrando información externa.
- Neo4j y bases de datos vectorialesNeo4j: Neo4j, una conocida base de datos gráfica de código abierto, destaca en el manejo de consultas relacionales y semánticas complejas. Además de Neo4j, bases de datos vectoriales como Weaviate, Pinecone, Milvus y Qdrant proporcionan capacidades eficientes de búsqueda y recuperación de similitudes y forman la columna vertebral de un flujo de trabajo de generación de aumento de recuperación (RAG) basado en agentes de alto rendimiento.
7 Puntos de referencia y conjuntos de datos
Los puntos de referencia y conjuntos de datos actuales ofrecen información valiosa para evaluar los sistemas de generación aumentada de recuperación (RAG), incluidos los basados en agentes y los de aumento de grafos. Aunque algunos están diseñados específicamente para RAG, otros se han adaptado para probar las capacidades de recuperación, inferencia y generación en diversos escenarios. Los conjuntos de datos son fundamentales para probar los componentes de recuperación, inferencia y generación del sistema GAR. En la Tabla 3 se presentan algunos conjuntos de datos clave para la evaluación de la GAR basada en tareas posteriores.
Los puntos de referencia desempeñan un papel clave en la normalización de la evaluación de los sistemas GAR al proporcionar tareas e indicadores estructurados. Los siguientes puntos de referencia son especialmente pertinentes:
- BEIR (Evaluación comparativa de la recuperación de información)un punto de referencia versátil diseñado para evaluar el rendimiento de los modelos integrados en una variedad de tareas de recuperación de información, que abarca 17 conjuntos de datos que abarcan los ámbitos de la bioinformática, las finanzas y las preguntas y respuestas [54].
- MS MARCO (Microsoft Machine Reading Comprehension)Este punto de referencia, que se centra en la clasificación de párrafos y las preguntas y respuestas, se utiliza ampliamente para tareas intensivas de recuperación en sistemas RAG [55].
- TREC (Text Retrieval Conference, Deep Learning Track)Proporcionar conjuntos de datos para la recuperación de párrafos y documentos, haciendo hincapié en la calidad de los modelos de clasificación en el proceso de recuperación [56].
- MuSiQue (interrogatorio secuencial multisalto): un punto de referencia para el razonamiento multisalto a través de múltiples documentos, destacando la importancia de recuperar y sintetizar información de contextos discretos [57].
- 2WikiMultihopQA: un conjunto de datos diseñado para una tarea de GC multisalto a través de dos artículos de Wikipedia, centrándose en la capacidad de conectar conocimientos de múltiples fuentes [58].
- AgentG (GAR basada en agentes para la fusión de conocimientos)Benchmarks específicamente diseñados para tareas GAR basadas en agentes que evalúan la síntesis dinámica de información a través de múltiples bases de conocimiento [8].
- HotpotQA: un benchmark de GC multisalto que requiere recuperación y razonamiento en contextos interrelacionados, adecuado para evaluar flujos de trabajo RAG complejos [59].
- RAGBenchUna referencia interpretable a gran escala que contiene 100.000 ejemplos de sectores industriales con el marco de evaluación TRACe para métricas RAG procesables [60].
- BERGEN (Evaluación comparativa de la generación de mejoras de recuperación)Biblioteca para la evaluación comparativa sistemática de sistemas RAG con experimentos normalizados [61].
- Kit de herramientas FlashRAGimplementa 12 métodos RAG e incluye 32 conjuntos de datos de referencia para apoyar una evaluación RAG eficiente y estandarizada [62].
- GNN-RAGEste benchmark evalúa el rendimiento de los sistemas RAG basados en grafos en tareas de predicción a nivel de nodo y a nivel de borde, centrándose en la calidad de la recuperación y el rendimiento de la inferencia en Knowledge Graph Quizzing (KGQA) [63].
Cuadro 3: Tareas descendentes y conjuntos de datos evaluados por el GAR (adaptado de [23])
| formulario | Tipo de misión | Conjuntos de datos y referencias |
|---|---|---|
| Preguntas y respuestas (QA) | Control de calidad de un solo salto | Natural Questions (NQ) [64], TriviaQA [65], SQuAD [66], Web Questions (WebQ) [67], PopQA [68], MS MARCO [55] |
| Control de calidad multisalto | HotpotQA[59], 2WikiMultiHopQA[58], MuSiQue[57] | |
| respuesta larga | ELI5 [69], NarrativeQA (NQA) [70], ASQA [71], QMSum [72] | |
| Control de calidad específico del ámbito | Qasper [73], COVID-QA [74], CMB/MMCU Medical [75] | |
| Preguntas de respuesta múltiple | QUALITY [76], ARC (sin referencia), CommonSenseQA [77] | |
| Figura QA | GraphQA [78] | |
| Preguntas y respuestas basadas en gráficos | Metaextracción de la teoría de sucesos | WikiEvento[79], RAMS[80] |
| Diálogo abierto | Hechiceros de Wikipedia (WoW)[81] | |
| diálogos | Diálogo personalizado | KBP [82], DuleMon [83] |
| Diálogo orientado a las tareas | CamRest[84] | |
| Contenidos personalizados | Amazon Dataset (Juguetes, Deportes, Belleza) [85] | |
| Razonamiento recomendado | HellaSwag [86], CommonSenseQA [77]. | |
| razonamiento de sentido común | Razonamiento de CdT | Razonamiento CoT [87], CSQA [88] |
| el resto | inferencia compleja | MMLU (sin referencia), WikiText-103[64] |
| comprensión lingüística | ||
| Comprobación de hechos/validación | FEVER [89], PubHealth [90] | |
| resúmenes | Resumen de la estrategia QA Texto | EstrategiaQA [91] |
| resumen del texto | WikiASP [92], XSum [93] | |
| Generación de texto | resumen largo | NarrativeQA (NQA) [70], QMSum [72] |
| categorización de textos | historia | Conjunto de datos biográficos (sin referencia), SST-2 [94] |
| Clasificación general del análisis de sentimiento | ||
| Búsqueda de códigos | Búsqueda de programación | VioLens [95], TREC [56], CodeSearchNet [96] |
| robustez | robustez de la recuperación | NoMIRACL [97] |
| Robustez de los modelos lingüísticos | WikiTexto-103 [98] | |
| matemáticas | razonamiento matemático | GSM8K [99] |
| traducción automática | tarea de traducción | CCI-Adquisición [100] |
8 Conclusiones
La Generación Aumentada de Recuperación (RAG) basada en agentes representa un avance transformador en inteligencia artificial que supera las limitaciones de los sistemas RAG tradicionales mediante la integración de agentes autónomos. Al aprovechar la inteligencia de los agentes, estos sistemas introducen la capacidad de toma de decisiones dinámica, razonamiento iterativo y flujos de trabajo colaborativos, lo que les permite resolver tareas complejas del mundo real con mayor precisión y adaptabilidad.
Esta revisión explora la evolución de los sistemas GAR desde las implementaciones iniciales hasta paradigmas avanzados como el GAR modular, destacando las aportaciones y limitaciones de cada paradigma. La integración de agentes en los procesos de GAR se ha convertido en un avance clave, que ha propiciado la aparición de sistemas de GAR basados en agentes que superan los flujos de trabajo estáticos y la limitada adaptabilidad contextual. Aplicaciones en los ámbitos de la sanidad, las finanzas, la educación y las industrias creativas ponen de manifiesto el potencial transformador de estos sistemas, demostrando su capacidad para ofrecer soluciones personalizadas, en tiempo real y conscientes del contexto.
A pesar de sus promesas, los sistemas GAR basados en agentes se enfrentan a retos que requieren más investigación e innovación. La complejidad de la coordinación, la escalabilidad y los problemas de latencia en las arquitecturas multiagente, así como las consideraciones éticas, deben abordarse para garantizar un despliegue sólido y responsable. Además, la falta de puntos de referencia y conjuntos de datos dedicados a evaluar las capacidades de los agentes supone un obstáculo importante. El desarrollo de métodos de evaluación para captar aspectos únicos de la GAR basada en agentes, como la colaboración multiagente y la adaptabilidad dinámica, es fundamental para avanzar en este campo.
De cara al futuro, la convergencia de la generación mejorada por recuperación y la inteligencia de agentes tiene el potencial de redefinir el papel de la IA en entornos dinámicos y complejos. Al abordar estos retos y explorar futuras direcciones, los investigadores y profesionales pueden liberar todo el potencial de los sistemas de GAR basados en agentes, allanando el camino para aplicaciones transformadoras en todos los sectores y dominios. Mientras los sistemas de IA siguen evolucionando, la GAR basada en agentes sirve de piedra angular para crear soluciones adaptables, conscientes del contexto e impactantes que satisfagan las necesidades de un mundo en rápida evolución.
bibliografía
[1] Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, andJianfeng Gao. Grandes modelos lingüísticos: un estudio, 2024.
[2] Aditi Singh. Exploring language models: a comprehensive survey and analysis. en 2023 International Conference on Research Methodologies in Gestión del Conocimiento, Inteligencia Artificial y Telecomunicaciones.
Ingeniería (RMKMATE), páginas 1-4, 2023.
[3] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang.
Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren.
Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, y Ji-Rong Wen. Estudio de grandes lenguajes
modelos, 2024.
[4] Sumit Kumar Dam, Choong Seon Hong, Yu Qiao y Chaoning Zhang. A complete survey on llm-based ai
chatbots, 2024.
[5] Aditi Singh: A survey of ai text-to-image and ai text-to-video generators, en 2023 4th International Conference.
sobre Inteligencia Artificial, Robótica y Control (AIRC), páginas 32-36, 2023.
[6] Aditi Singh, Abul Ehtesham, Gaurav Kumar Gupta, Nikhil Kumar Chatta, Saket Kumar y Tala Talaei Khoei.
Exploring prompt engineering: a systematic review with swot analysis, 2024.
[7] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua
Peng, Xiaocheng Feng, Bing Qin y Ting Liu. A survey on hallucination in large language models: Principles,
taxonomía, retos y cuestiones abiertas. ACM Transactions on Information Systems, noviembre de 2024.
[8] Meng-Chieh Lee, Qi Zhu, Costas Mavromatis, Zhen Han, Soji Adeshina, Vassilis N. Ioannidis, Huzefa Rangwala.
y Christos Faloutsos. agent-g: An agentic framework for graph retrieval augmented generation, 2024.
[9] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao
Zhang, Jie Jiang y Bin Cui, Retrieval-augmented generation for ai-generated content: a survey, 2024.
[10] Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan.
y Graham Neubig. recuperación activa generación aumentada, 2023.
[11] Yikun Han, Chunjiang Liu y Pengfei Wang, A comprehensive survey on vector database: Storage and retrieval.
técnica, reto, 2023.
[12] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang.
Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei y Jirong Wen. Estudio sobre modelos lingüísticos basados en grandes
Fronteras de la Ordenador Science, 18(6), marzo de 2024.
[13] Aditi Singh, Saket Kumar, Abul Ehtesham, Tala Talaei Khoei y Deepshikha Bhati. large language modeldriven immersive agent. in 2024 IEEE World AI IoT Congress (AIIoT), páginas 0619-0624, 2024.
[14] Matthew Renze y Erhan Guven. Self-reflection in llm agents: effects on problem-solving performance, 2024.
[15] Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang.
Comprender la planificación de los agentes de llm: una encuesta, 2024.
[16] Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and
Xiangliang Zhang. Multiagentes basados en grandes modelos lingüísticos: estudio de avances y retos, 2024.
[17] Chidaksh Ravuru, Sagar Srinivas Sakhinana y Venkataramana Runkana. agentic retrieval-augmented
para el análisis de series temporales, 2024.
[18] Jie Huang y Kevin Chen-Chuan Chang. Towards reasoning in large language models: a survey, 2023.
[19] Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang y Siliang Tang.
Graph retrieval-augmented generation: a survey, 2024.
[20] Aditi Singh, Abul Ehtesham, Saifuddin Mahmud y Jong-Hoon Kim. Revolucionar la atención a la salud mental
a través de langchain: Un viaje con un gran modelo lingüístico. En 2024 IEEE 14th Annual Computing and
Communication Workshop and Conference (CCWC), páginas 0073-0078, 2024.
[21] Gaurav Kumar Gupta, Aditi Singh, Sijo Valayakkad Manikandan y Abul Ehtesham. digital diagnostics: the
potencial de los grandes modelos lingüísticos en el reconocimiento de síntomas de enfermedades comunes, 2024.
[22] Aditi Singh, Abul Ehtesham, Saket Kumar, Gaurav Kumar Gupta, y Tala Talaei Khoei. Fomentar la responsabilidad
Uso del ai generativo en la educación: Un enfoque de aprendizaje basado en recompensas. En Tim Schlippe, Eric C. K. Cheng, y
Tianchong Wang, editores, Artificial Intelligence in Education Technologies: New Development and Innovative
Practices, páginas 404-413, Singapur, 2025. Springer Nature Singapore.
[23] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and
Haofen Wang. Retrieval-augmented generation for large language models: a survey, 2024.
[24] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen y Wen ˘
tau Yih. Dense passage retrieval for open-domain question answering, 2020.
[25] Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong y Ji-Rong
Wen. A survey on the memory mechanism of large language model based agents, 2024.
[26] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan y Weizhu Chen. Crítica: Gran
Los modelos lingüísticos pueden autocorregirse con una herramienta de crítica interactiva, 2024.
[27] Aditi Singh, Abul Ehtesham, Saket Kumar y Tala Talaei Khoei: Enhancing ai systems with agentic workflows.
patterns in large language model. En 2024 IEEE World AI IoT Congress (AIIoT), páginas 527-532, 2024.
[28] DeepLearning.AI. How agents can improve llm performance. https://www.deeplearning.ai/the-batch/
how-agents-can-improve-llm-performance/?ref=dl-staging-website.ghost.io, 2024. consultado: 2025-01-13.
[29] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha
Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann.
Sean Welleck, Amir Yazdanbakhsh y Peter Clark. self-refine: Iterative refinement with self-feedback, 2023.
[30] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan y Shunyu Yao.
Reflexión: agentes lingüísticos con aprendizaje por refuerzo verbal, 2023.
[31] Blog Weaviate. ¿Qué es el trapo agéntico? https://weaviate.io/blog/what-is-agentic-rag#:~:text=is%
20Agentic%20RAG%3F-,%E2%80%8B,of%20the%20non%2Dagentic%20pipeline. Accessed: 2025-01-14.
[32] Shi-Qi Yan, Jia-Chen Gu, Yun Zhu y Zhen-Hua Ling. Corrective retrieval augmented generation, 2024.
[33] LangGraph CRAG Tutorial. langgraph crag: Contextualised retrieval-augmented generation tutorial. https.
//langchain-ai.github.io/langgraph/tutorials/rag/langgraph_crag/. Acceso: 2025-01-14.
[34] Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang y Jong C. Park. Adaptive-rag: learning to adapt
modelos lingüísticos amplios mejorados mediante la complejidad de las preguntas, 2024.
[35] LangGraph Adaptive RAG Tutorial. langgraph adaptive rag: Adaptive retrieval-augmented generation tutorial. https://langchain-ai.github.io /langgraph/tutorials/rag/langgraph_adaptive_rag/.
Acceso: 2025-01-14.
[36] Zhili Shen, Chenxin Diao, Pavlos Vougiouklis, Pascual Merita, Shriram Piramanayagam, Damien Graux, Dandan
Tu, Zeren Jiang, Ruofei Lai, Yang Ren y Jeff Z. Pan. Gear: Graph-enhanced agent for retrieval-augmented
generación, 2024.
[37] LlamaIndex. Introducing agentic document workflows. https://www.llamaindex.ai/blog/
introducing-agentic-document-workflows, 2025. acceso: 2025-01-13.
[38] AWS Machine Learning Blog. how twitch used agentic workflow with rag on amazon
bedrock to supercharge ad sales. https://aws.amazon.com/blogs/machine-learning/
how-twitch-used-agentic-workflow-with-rags-on-amazon-bedrock-to-supercharge-ad-sales/,
Acceso: 2025-01-13.
[39] LlamaCloud Demo Repository. patient case summary workflow using llamacloud. https.
//github.com/run-llama/llamacloud-demo/blob/main/examples/document_workflows/
patient_case_summary/patient_case_summary.ipynb, 2025. consultado: 2025-01-13.
[40] LlamaCloud Demo Repository. contract review workflow using llamacloud. https://github.com/
run-llama/llamacloud-demo/blob/main/examples/document_workflows/contract_review/
contract_review.ipynb, 2025. consultado: 2025-01-13.
[41] LlamaCloud Demo Repository. auto insurance claims workflow using llamacloud. https.
//github.com/run-llama/llamacloud-demo/blob/main/examples/document_workflows/auto_
insurance_claims/auto_insurance_claims.ipynb, 2025. consultado: 2025-01-13.
[42] LlamaCloud Demo Repository. flujo de trabajo de generación de informes de trabajos de investigación utilizando llamacloud.
https://github.com/run-llama/llamacloud-demo/blob/main/examples/report_generation/
research_paper_report_generation.ipynb, 2025. consultado: 2025-01-13.
[43] LangGraph Agentic RAG Tutorial. langgraph agentic rag: Nodes and edges tutorial. https://langchain-ai.
github.io/langgraph/tutorials/rag/langgraph_agentic_rag/#nodes-and-edges. accedido.
2025-01-14.
[44] Blog LlamaIndex. trapo agéntico con llamaindex. https://www.llamaindex.ai/blog/
agentic-rag-with-llamaindex-2721b8a49ff6. Accessed: 2025-01-14.
[45] Hugging Face Cookbook. agentic rag: Turbocharge your retrieval-augmented generation with query reformulation and self-query. https:// Huggingface.co/learn/cookbook/en/agent_rag. fecha de consulta: 2025-01-14.
[46] Qdrant Blog. agentic rag: combining rag with agents for enhanced information retrieval. https://qdrant.
tech/articles/agentic-rag/. Acceso: 2025-01-14.
[47] crewAI Inc. crewai: A github repository for ai projects. https://github.com/crewAIInc/crewAI, 2025.
Acceso: 2025-01-15.
[48] AG2AI Contributors. Ag2: A github repository for advanced generative ai research. https://github.com/
ag2ai/ag2, 2025. acceso: 2025-01-15.
[49] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun
Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger y Chi Wang. AutogenHabilitación
aplicaciones llm de nueva generación mediante un marco de conversación multiagente. 2023.
[50] Shaokun Zhang, Jieyu Zhang, Jiale Liu, Linxin Song, Chi Wang, Ranjay Krishna y Qingyun Wu. Formación
agentes de modelos lingüísticos sin modificar los modelos lingüísticos. ICML'24, 2024.
[51] OpenAI. Enjambre: Lightweight multi-agent orchestration framework. https://github.com/openai/swarm.
Acceso: 2025-01-14.
[52] Documentación LlamaIndex. trapo agéntico usando vértice ai. https://docs.llamaindex.ai/en/stable/
examples/agent/agentic_rag_using_vertex_ai/. Acceso: 2025-01-14.
[53] IBM Granite Community. Agentic rag: Ai agents with ibm granite models. https://github.com/
ibm-granite-community/granite-snack-cookbook/blob/main/recipes/AI-Agents/Agentic_
RAG.ipynb. Acceso: 2025-01-14.
[54] Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava e Iryna Gurevych. Beir: A heterogenous
punto de referencia para la evaluación sin disparos de modelos de recuperación de información, 2021.
[55] Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew
McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary y Tong
Wang. ms marco: a human generated machine reading comprehension dataset, 2018.
[56] Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, Jimmy Lin, Ellen M. Voorhees e Ian Soboroff.
Overview of the trec 2022 deep learning track. en Text REtrieval Conference (TREC). NIST, TREC, marzo de 2023.
[57] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot y Ashish Sabharwal. musique: multihop questions
mediante la composición de preguntas de un solo salto, 2022.
[58] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara y Akiko Aizawa. Construcción de un conjunto de datos qa multisalto.
para una evaluación exhaustiva de los pasos del razonamiento, 2020.
[59] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov y Christopher D. Manning. hotpotqa: A dataset for diverse, explainable multi-hop question answering, 2018.
[60] Robert Friel, Masha Belyi y Atindriyo Sanyal. Ragbench: punto de referencia explicable para la recuperación aumentada.
Sistemas de generación, 2024.
[61] David Rau, Hervé Déjean, Nadezhda Chirkova, Thibault Formal, Shuai Wang, Vassilina Nikoulina y Stéphane
Clinchant. Bergen: A benchmarking library for retrieval-augmented generation, 2024.
[62] Jiajie Jin, Yutao Zhu, Xinyu Yang, Chenghao Zhang y Zhicheng Dou. Flashrag: A modular toolkit for efficient
investigación sobre recuperación y generación aumentada, 2024.
[63] Costas Mavromatis y George Karypis. Gnn-rag: Graph neural retrieval for large language model reasoning.
2024.
[64] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle
Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei
Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le y Slav Petrov: Natural questions: a benchmark for question
Transactions of the Association for Computational Linguistics, 7:452-466, 2019.
[65] Mandar Joshi, Eunsol Choi, Daniel S. Weld y Luke Zettlemoyer. triviaqa: a large scale distantly supervised
conjunto de datos de desafíos para la comprensión lectora, 2017.
[66] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev y Percy Liang. Squad: más de 100.000 preguntas para la máquina
comprensión de textos, 2016.
[67] Jonathan Berant, Andrew K. Chou, Roy Frostig, and Percy Liang. Semantic parsing on freebase from questionanswer pairs. in Conference on Empirical Methods in Natural Language Processing, 2013.
[68] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi y Hannaneh Hajishirzi. when not to
Modelos lingüísticos de confianza: investigación de la eficacia de memorias paramétricas y no paramétricas. en Anna Rogers,
Jordan Boyd-Graber y Naoaki Okazaki, editores, Proceedings of the 61st Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers), páginas 9802-9822, Toronto, Canadá, julio de 2023.
para la Lingüística Computacional.
[69] Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston y Michael Auli. Eli5: Forma larga
Contestación de preguntas, 2019.
[70] Tomáš Kociský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis y Edward ˇ
Grefenstette. el reto de comprensión lectora narrativeqa. 2017.
[71] Ivan Stelmakh, Yi Luan, Bhuwan Dhingra y Ming-Wei Chang. Asqa: Factoid questions meet long-form
respuestas, 2023.
[72] Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli
Celikyilmaz, Yang Liu, Xipeng Qiu y Dragomir Radev: QMSum: A new benchmark for query-based
Multi-domain meeting summarization. páginas 5905-5921, junio de 2021.
[73] Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith y Matt Gardner. a dataset of informationseeking questions and answers anchored in research papers. en Kristina Toutanova, Anna Rumshisky, Luke
Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty y Yichao
Zhou, editores, Proceedings of the 2021 Conference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies, páginas 4599-4610, en línea, junio de 2021.
para la Lingüística Computacional.
[74] Timo Möller, Anthony Reina, Raghavan Jayakumar y Malte Pietsch: COVID-QA: A question answering
dataset for COVID-19. in ACL 2020 Workshop on Natural Language Processing for COVID-19 (NLP-COVID),.
2020.
[75] Xidong Wang, Guiming Hardy Chen, Dingjie Song, Zhiyi Zhang, Zhihong Chen, Qingying Xiao, Feng Jiang.
Jianquan Li, Xiang Wan, Benyou Wang y Haizhou Li. Cmb: A comprehensive medical benchmark en chino.
2024.
[76] Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh
Padmakumar, Johnny Ma, Jana Thompson, He He y Samuel R. Bowman. calidad: respuesta a preguntas con
textos de entrada largos, ¡sí!, 2022.
[77] Alon Talmor, Jonathan Herzig, Nicholas Lourie y Jonathan Berant. commonsenseQA: A question answering
challenge targeting commonsense knowledge. en Jill Burstein, Christy Doran y Thamar Solorio, editores.
Actas de la Conferencia 2019 del Capítulo Norteamericano de la Asociación para la Computación
Linguistics: Human Language Technologies, Volumen 1 (Long and Short Papers), páginas 4149-4158, Minneapolis, Estados Unidos.
Minnesota, junio de 2019. association for Computational Linguistics.
[78] Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, y Bryan
Hooi. g-retriever: retrieval-augmented generation for textual graph understanding and question answering.
2024.
[79] Sha Li, Heng Ji y Jiawei Han: Document-level event argument extraction by conditional generation, 2021.
[80] Seth Ebner, Patrick Xia, Ryan Culkin, Kyle Rawlins y Benjamin Van Durme. Argumento multisentencia
vinculación, 2020.
[81] Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli y Jason Weston. wizard of wikipedia.
Agentes conversacionales potenciados por el conocimiento, 2019.
[82] Hongru Wang, Minda Hu, Yang Deng, Rui Wang, Fei Mi, Weichao Wang, Yasheng Wang, Wai-Chung Kwan.
Irwin King, y Kam-Fai Wong. Grandes modelos lingüísticos como planificador de fuentes para el conocimiento personalizado basado en
diálogo, 2023.
[83] Xinchao Xu, Zhibin Gou, Wenquan Wu, Zheng-Yu Niu, Hua Wu, Haifeng Wang y Shihang Wang. Tiempo largo
conversación de dominio abierto con memoria de persona a largo plazo, 2022.
[84] Tsung-Hsien Wen, Milica Gašic, Nikola Mrkšišc, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, David '
Vandyke, y Steve Young. Conditional generation and snapshot learning in neural dialogue systems. en
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, páginas 2153-2162, , en Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.
Austin, Texas, noviembre de 2016. association for Computational Linguistics.
[85] Ruining He y Julian McAuley, Ups and downs: modelling the visual evolution of fashion trends with one-class
En Proceedings of the 25th International Conference on World Wide Web, WWW '16, página
507-517, República y Cantón de Ginebra, CHE, 2016. International World Wide Web Conferences Steering
Comité.
[86] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi y Yejin Choi. HellaSwag: ¿Puede una máquina realmente
En Anna Korhonen, David Traum y Lluís Màrquez, editores, Proceedings of the 57th session of the Commission on Human Rights.
Reunión anual de la Asociación de Lingüística Computacional, páginas 4791-4800, Florencia, Italia, julio de 2019.
Asociación de Lingüística Computacional.
[87] Seungone Kim, Se June Joo, Doyoung Kim, Joel Jang, Seonghyeon Ye, Jamin Shin y Minjoon Seo. La
cot collection: mejora del aprendizaje de modelos lingüísticos con cero y pocos disparos mediante el ajuste fino de la cadena de pensamiento,
2023.
[88] Amrita Saha, Vardaan Pahuja, Mitesh M. Khapra, Karthik Sankaranarayanan y Sarath Chandar, Complex.
respuesta secuencial a preguntas: hacia el aprendizaje de la conversación sobre pares pregunta-respuesta enlazados con un conocimiento
gráfico. 2018.
[89] James Thorne, Andreas Vlachos, Christos Christodoulopoulos y Arpit Mittal, FEVER: a large-scale dataset for
fact extraction and VERification. in Marilyn Walker, Heng Ji, and Amanda Stent, editors, Proceedings of the 2018
Conferencia de la Sección Norteamericana de la Asociación de Lingüística Computacional: Lenguaje Humano
Technologies, Volume 1 (Long Papers), pages 809-819, New Orleans, Louisiana, June 2018. association for
Lingüística computacional.
[90] Neema Kotonya y Francesca Toni, Explainable automated fact-checking for public health claims, 2020.
[91] Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth y Jonathan Berant. ¿usaba aristóteles un ordenador portátil?
una prueba de respuesta a preguntas con estrategias de razonamiento implícitas, 2021.
[92] Hiroaki Hayashi, Prashant Budania, Peng Wang, Chris Ackerson, Raj Neervannan y Graham Neubig. Wikiasp.
Un conjunto de datos para el resumen multidominio basado en aspectos, 2020.
[93] Shashi Narayan, Shay B. Cohen y Mirella Lapata. No me des los detalles, ¡sólo el resumen! topic-aware
redes neuronales convolucionales para el resumen extremo, 2018.
[94] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng y Christopher
Potts. Recursive deep models for semantic compositionality over a sentiment treebank. en David Yarowsky,
Timothy Baldwin, Anna Korhonen, Karen Livescu y Steven Bethard, editores, Proceedings of the 2013
Conference on Empirical Methods in Natural Language Processing, páginas 1631-1642, Seattle, Washington.
EE.UU., octubre de 2013. Asociación de Lingüística Computacional.
[95] Sourav Saha, Jahedul Alam Junaed, Maryam Saleki, Arnab Sen Sharma, Mohammad Rashidujjaman Rifat.
Mohamed Rahouti, Syed Ishtiaque Ahmed, Nabeel Mohammed y Mohammad Ruhul Amin. Vio-lens: a novel
dataset of annotated social network posts leading to different forms of communal violence and its evaluation. en
Firoj Alam, Sudipta Kar, Shammur Absar Chowdhury, Farig Sadeque y Ruhul Amin, editores, Proceedings
del First Workshop on Bangla Language Processing (BLP-2023), páginas 72-84, Singapur, diciembre de 2023.
Asociación de Lingüística Computacional.
[96] Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis y Marc Brockschmidt. Codesearchnet
Desafío: Evaluación del estado de la búsqueda semántica de códigos, 2020.
[97] Nandan Thakur, Luiz Bonifacio, Xinyu Zhang, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo.
Xiaoguang Li, Qun Liu, Boxing Chen, Mehdi Rezagholizadeh y Jimmy Lin. "Saber cuando no se sabe".
A multilingual relevance assessment dataset for robust retrieval-augmented generation, 2024.
[98] Stephen Merity, Caiming Xiong, James Bradbury y Richard Socher. modelos de mezcla centinela puntero, 2016.
[99] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert.
Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse y John Schulman. formación de verificadores para
resolver problemas matemáticos, 2021.
[100] Ralf Steinberger, Bruno Pouliquen, Anna Widiger, Camelia Ignat, Tomaž Erjavec, Dan Tufi¸s y Dániel Varga.
The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages. En Nicoletta Calzolari, Khalid
Choukri, Aldo Gangemi, Bente Maegaard, Joseph Mariani, Jan Odijk y Daniel Tapias, editores, Proceedings of
Quinta Conferencia Internacional sobre Recursos Lingüísticos y Evaluación (LREC'06), Génova, Italia, mayo de 2006.
Asociación Europea de Recursos Lingüísticos (ELRA).
© declaración de copyright
El artículo está protegido por derechos de autor y no debe reproducirse sin autorización.

Artículos relacionados
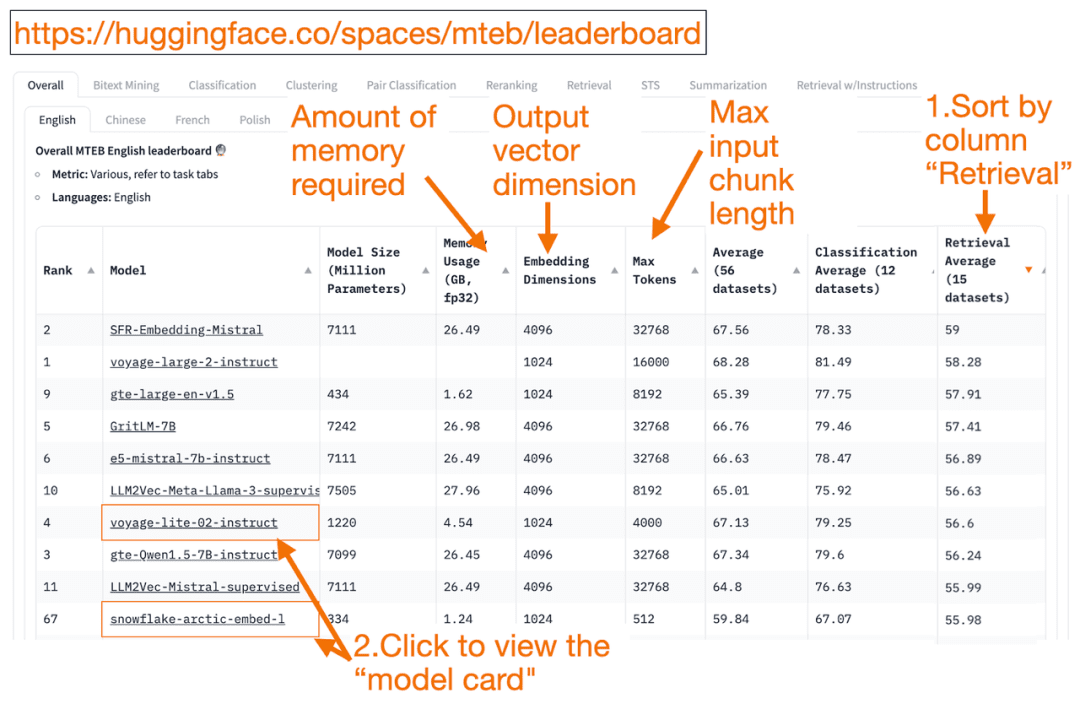



Sin comentarios...