
揭秘大模型“幻觉”:HHEM 排行榜透视 LLM 事实一致性现状

大型语言模型(LLM)的能力日新月异,但其输出内容中出现事实性错误或与原文无关信息的“幻觉”现象,始终是阻碍其更广泛应用和深度信任的一大难题。为了量化评估这一问题,Hughes Hallucination Evaluation Model (HHEM) 排行榜应运而生,专注于衡量主流 LLM 在生成文档摘要时的幻觉频率。
所谓“幻觉”,指的是模型在摘要中引入了原始文档并未包含、甚至相悖的“事实”。这对于依赖 LLM 进行信息处理,尤其是基于检索增强生成(RAG)的应用场景来说,是一个关键的质量瓶颈。毕竟,如果模型不能忠实于给定信息,那么其输出的可信度就大打折扣。
HHEM 如何工作?
该排行榜采用 Vectara 公司开发的 HHEM-2.1 幻觉评估模型。其工作原理是,针对一份源文档和由特定 LLM 生成的摘要,HHEM 模型会输出一个介于 0 到 1 之间的幻觉分数。分数越接近 1,表示摘要与源文档的事实一致性越高;越接近 0,则表示幻觉越严重,甚至完全是编造的内容。Vectara 也提供了一个开源版本 HHEM-2.1-Open,可供研究人员和开发者在本地进行评估,其模型卡发布在 Hugging Face 平台。
评估基准
评估使用了一个包含 1006 份文档的数据集,这些文档主要来源于公开数据集,如经典的 CNN/Daily Mail Corpus。项目团队使用参与评估的各个 LLM 为每份文档生成摘要,然后计算每对(源文档,生成摘要)的 HHEM 分数。为了保证评估的标准化,所有模型调用均设置 temperature 参数为 0,旨在获取模型最具确定性的输出。
评估指标主要包括:
- 幻觉率 (Hallucination Rate): HHEM 分数低于 0.5 的摘要所占的百分比。这个值越低越好。
- 事实一致性率 (Factual Consistency Rate): 100% 减去幻觉率,反映了摘要内容忠实于原文的比例。
- 回答率 (Answer Rate): 模型成功生成非空摘要的百分比。部分模型可能因内容安全策略或其他原因拒绝回答或出错。
- 平均摘要长度 (Average Summary Length): 生成摘要的平均词数,可侧面反映模型的输出风格。
LLM 幻觉排行榜解读
以下是基于 HHEM-2.1 模型评估得出的 LLM 幻觉排行榜(数据截至 2025 年 3 月 25 日,请以实际更新为准):
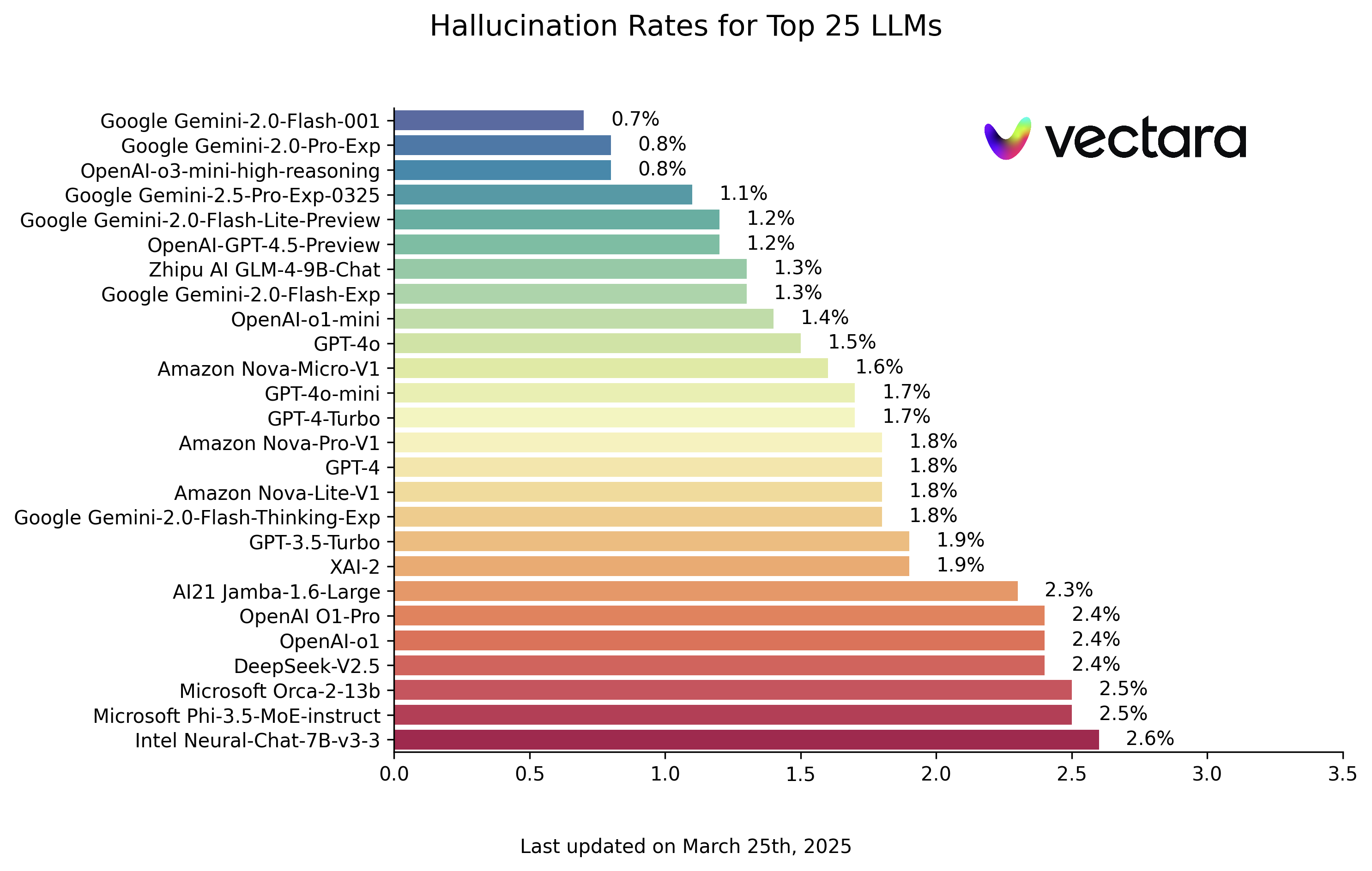
| Modèle | Hallucination Rate | Factual Consistency Rate | Answer Rate | Average Summary Length (Words) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-high-reasoning | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Google Gemini-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-Preview | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazon Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Thinking-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazon Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 Jamba-1.6-Large | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Instruct | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-Vision | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| Snowflake-Arctic-Instruct | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Mistral Small3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4-mini-instruct | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| InternLM3-8B-Instruct | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5-mini-instruct | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Large2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instruct | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Claude-3.7-Sonnet | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Claude-3.7-Sonnet-Think | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohère Command-A | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 Jamba-1.6-Mini | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Anthropique Claude-3-5-sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Anthropic Claude-3-5-haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Instruct | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Mistral-Small-3.1-24B-Instruct | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Mistral-Pixtral | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instruct | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Mistral-Ministral-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instruct | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| Mistral-Ministral-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| databricks dbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| Mistral-Small2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granite-3.2-8B-Instruct | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instruct-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Anthropic Claude-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Mistral-Nemo-Instruct | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft WizardLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Expanse 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| Profondeur de l'eau-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instruct | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Anthropic Claude-3-sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instruct | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Anthropic Claude-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-large | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instruct-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instruct | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII falcon-7B-instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
注:模型排名根据幻觉率从低到高排序。完整列表和模型接入细节可在原始 HHEM Leaderboard GitHub 仓库查看。
观察排行榜,可以看到 Google 的 Gemini 系列模型和 OpenAI 的部分新模型(如 o3-mini-high-reasoning)表现抢眼,幻觉率控制在极低的水平。这显示了头部厂商在提升模型事实性方面的进展。同时,也能看到不同规模、不同架构的模型之间存在显著差异。一些较小的模型,如 Microsoft 的 Phi 系列或 Google 的 Gemma 系列,也取得了不错的成绩,暗示着模型参数量并非决定事实一致性的唯一因素。然而,一些早期或特定优化的模型,幻觉率则相对较高。
强推理模型与知识库的“错配”:以 DeepSeek-R1 为例
排行榜中 DeepSeek-R1 的幻觉率(14.3%)相对较高,这引出了一个值得探讨的问题:为什么一些在推理任务上表现出色的模型,在基于事实的摘要任务中反而容易产生幻觉?
DeepSeek-R1 这类模型通常被设计用于处理复杂的逻辑推理、遵循指令和多步思考。它们的核心优势在于“推导”和“演绎”,而非简单地“复述”或“转述”。然而,知识库(尤其是 RAG 场景下的知识库)的核心要求恰恰是后者:模型需要严格依据提供的文本信息进行回答或摘要,最大限度地避免引入外部知识或进行过度引申。
当一个强推理模型被限制在仅能使用给定文档的情况下进行摘要时,其“推理”本能可能成为一把双刃剑。它可能会:
- 过度解读: 对原文信息进行不必要的深层推断,得出原文并未明示的结论。
- 缝合信息: 尝试将原文碎片化的信息通过“合理”的逻辑链条串联起来,但这个链条可能并非原文所支持。
- 默认外部知识: 即便被要求只依据原文,其训练中习得的庞大世界知识仍可能无意识地渗入,导致与原文事实的偏离。
简单来说,这类模型可能“想得太多”,在需要精确、忠实复述信息的场景下,反而容易“聪明反被聪明误”,制造出看似合理但实际上是幻觉的内容。这说明,模型的推理能力和事实一致性(尤其是在受限信息源下的事实一致性)是两种不同的能力维度。针对知识库、RAG 等场景,选择幻觉率低、能忠实反映输入信息的模型,可能比单纯追求推理得分更重要。
方法论与背景
HHEM 排行榜的建立并非凭空而来,它借鉴了事实一致性研究领域的诸多先前工作,如 SUMMAC, TRUE, TrueTeacher 等论文中建立的方法论。其核心思路是训练一个专门用于检测幻觉的模型,该模型在判断摘要与原文一致性方面达到与人类评估者高度相关的水平。
评估过程选取了摘要任务作为 LLM 事实性的代表。这不仅因为摘要任务本身要求高度的事实一致性,也因为它与 RAG 系统的工作模式高度相似——在 RAG 中,LLM 正是扮演了对检索到的信息进行整合与摘要的角色。因此,这个排行榜的结果对于评估模型在 RAG 应用中的可靠性具有参考价值。
需要注意的是,评估团队排除了那些模型拒绝回答或给出极短无效答案的文档,最终使用了所有模型都能成功生成摘要的 831 份文档(源自最初的 1006 份)进行最终排名计算,以确保公平性。回答率和平均摘要长度指标也反映了模型在处理这些请求时的行为模式。
评估使用的 Prompt 模板如下:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
在实际调用时,<PASSAGE> 会被替换为具体的源文档内容。
展望未来
HHEM 排行榜项目方表示,未来计划扩展评估范围:
- 引用准确性: 增加对 LLM 在 RAG 场景下引用来源准确性的评估。
- 其他 RAG 任务: 覆盖更多 RAG 相关任务,例如多文档摘要。
- 多语言支持: 将评估扩展到英语之外的其他语言。
HHEM 排行榜为观察和比较不同 LLM 在控制幻觉、保持事实一致性方面的能力提供了一个有价值的窗口。虽然它并非衡量模型质量的唯一标准,也无法涵盖所有类型的幻觉,但它无疑推动了行业对 LLM 可靠性问题的关注,并为开发者选择和优化模型提供了重要的参考依据。随着模型和评估方法的持续迭代,我们有望看到 LLM 在提供准确、可信信息方面取得更大进步。
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes



Pas de commentaires...