
KAG : cadre de base de connaissances d'IA domestique à source ouverte analyse approfondie et tutoriels d'installation

Récemment, j'ai découvert un cadre de base de connaissances d'IA domestique à source ouverte très attrayant : KAG (Knowledge Augmented Generation).
KAG Lancé conjointement par Ant Group, l'université de Zhejiang et de nombreuses autres organisations, il se concentre sur la construction de bases de connaissances dans des domaines verticaux. Les données de l'étude montrent que le KAG dans le domaine de l'administration en ligne atteint le niveau le plus élevé de l'Union européenne. 91.6% : un taux de précision impressionnantIl excelle également dans des scénarios tels que les questions-réponses sur les soins de santé en ligne.
Cet article vous propose un examen approfondi des éléments suivants KAG principe, scénarios d'application, comparaison RAG L'article fournit également des tutoriels d'installation locale et des démonstrations pour vous donner une expérience immersive du framework KAG open-sourcé par Ant. Si vous envisagez d'utiliser l'IA pour construire votre propre base de connaissances, cet article est à ne pas manquer !
Qu'est-ce que KAG ? Concepts de base pour une nouvelle génération de bases de connaissances
KAG (Knowledge Augmented Generation) est un cadre déductif de questions et réponses basé sur le moteur OpenSPG et les grands modèles de langage (LLM). Ses concepts de base sont les suivantsCombinant le double avantage du graphe de connaissances et de la recherche vectorielle, il vise à fournir aux utilisateurs une aide à la décision plus rigoureuse et des services de recherche d'informations plus précis.
KAG réalise une fusion profonde et une amélioration du LLM et du graphe de connaissances grâce aux quatre technologies clés suivantes :
- Connaissance de la représentation adaptée aux LLMOptimiser la structure des graphes de connaissances pour les rendre plus faciles à comprendre et à exploiter par de grands modèles de langage.
- Indexation croisée entre les graphes de connaissances et les fragments de textes originauxLe projet de recherche d'un fragment de texte : établir des liens bidirectionnels entre les entités et les relations du graphe de connaissances et le fragment de texte original afin d'améliorer l'efficacité et la précision de la recherche d'informations.
- Moteur de raisonnement hybride guidé par la forme logiqueCombiner le pouvoir de raisonnement logique du Knowledge Graph avec le pouvoir de compréhension sémantique du LLM pour obtenir des quiz de raisonnement plus complexes.
- Alignement des connaissances avec le raisonnement sémantiqueLes connaissances du graphe de connaissances sont alignées sur l'espace sémantique du modèle linguistique afin d'améliorer l'efficacité de l'utilisation des connaissances.
En bref, KAG combine de manière innovante les avantages des graphes de connaissances et de la recherche vectorielle pour construire un cadre de base de connaissances puissant. Il peut non seulement utiliser la capacité de raisonnement logique du LLM, mais aussi la combiner avec le graphe de connaissances pour un raisonnement plus approfondi afin de mener à bien des tâches complexes de recherche d'informations. Plus important encore, lorsque les informations du graphe de connaissances sont insuffisantes, KAG peut également utiliser intelligemment la technologie de recherche vectorielle pour compléter les fragments de texte pertinents afin de garantir l'exhaustivité et la précision des réponses.
Vue d'ensemble de l'architecture globale de KAG
Le cadre KAG se compose de deux modules de base : la construction de connaissances (kg-builder) et la résolution de problèmes (kg-solver).
- kg-builder Le module se concentre sur la construction efficace de la connaissance, l'optimisation de la représentation de la connaissance pour LLM et la prise en charge de la modélisation flexible de la connaissance et de l'indexation bidirectionnelle.
- kg-solver Le module est alors responsable de la résolution efficace des problèmes, ce qui est réalisé par un moteur de raisonnement hybride qui intègre de multiples capacités telles que la recherche, le raisonnement graphique, le raisonnement linguistique et le calcul numérique pour résoudre des problèmes complexes.
- Le troisième module, kag-model, sera mis en libre accès afin d'améliorer encore le cadre KAG.
KAG vs. RAG traditionnel : différences et avantages expliqués
RAG (Retrieval-Augmented Generation) a été largement utilisé comme technologie commune de base de connaissances. Quels sont donc les différences et les avantages de KAG par rapport à RAG ? Nous les comparons et les analysons à travers les dimensions suivantes :
1) Représentation des connaissances :
- RAG. Il s'appuie principalement sur la similarité vectorielle pour la recherche et la représentation des connaissances est relativement simple, ce qui rend difficile le traitement de problèmes complexes nécessitant un raisonnement multi-sauts.
- KAG. Adopter une représentation des connaissances plus conviviale pour le LLM, compatible avec les connaissances sans schéma et à schéma contraint, supportant la structure inter-indexée des connaissances structurées en graphe et des connaissances textuelles, ainsi qu'une représentation des connaissances plus riche et plus structurée.
2. les capacités de raisonnement :
- RAG. Insensibilité aux relations logiques des connaissances et manque de capacités de raisonnement logique pour faire face à des problèmes dans des domaines spécialisés nécessitant un raisonnement complexe.
- KAG. Présente un moteur de raisonnement hybride guidé par des symboles logiques, doté de puissantes capacités de raisonnement logique et d'interrogation multi-sauts pour traiter des problèmes professionnels plus complexes.
3. la performance :
- RAG. Performances médiocres dans les tâches à sauts multiples et les tâches à passages croisés, générant des textes relativement faibles en termes de cohérence et de logique.
- KAG. Il donne de bons résultats dans les tâches à sauts multiples et à passages croisés, améliorant de manière significative la précision du raisonnement et la couverture des informations, et générant des réponses plus précises et plus complètes.
4. les scénarios applicables :
- RAG. Elle convient mieux aux tâches générales de génération et de recherche de textes, mais ses performances seront limitées dans des domaines spécialisés tels que le droit, la médecine et les sciences, où un raisonnement complexe est nécessaire.
- KAG. Particulièrement adapté aux applications nécessitant un raisonnement complexe et aux quiz factuels multi-sauts. Domaine d'expertiseL'entreprise est en mesure de fournir des services de connaissance plus professionnels et plus précis, par exemple dans les domaines de la finance, des soins de santé, du droit et de l'administration.
Dans l'ensemble, en fusionnant les graphes de connaissances et la recherche vectorielle, et en optimisant profondément la représentation des connaissances et les capacités de raisonnement, KAG montre qu'il est possible de surpasser la technologie RAG traditionnelle dans le traitement des problèmes complexes et l'interrogation des connaissances spécifiques à un domaine.
Déploiement local de tutoriels "au niveau du flux" : installation de KAG, utilisation, effet de la démo
Les analyses théoriques ont besoin de tests pratiques après tout ! Ensuite, je vous montrerai comment installer, déployer et utiliser KAG localement à la main, avec une démonstration simple des résultats.
Ressources connexes du KAG :
- Adresse Github.https://github.com/OpenSPG/KAG
- Site officiel.https://spg.openkg.cn/
Recommandations pour la configuration du matériel :
- CPU ≥ 8 cœurs
- Mémoire RAM ≥ 32 Go
- Disque dur ≥ 100 GB
La configuration officielle recommandée est élevée, mais d'après mes tests, il peut fonctionner sans problème sur un PC Windows avec 16 Go de RAM. Par conséquent, ce tutoriel démontrera l'installation et l'utilisation de KAG dans un environnement Windows.
Étape 1 : Installer Docker Desktop
L'installation et le déploiement de KAG reposent sur un environnement Docker, assurez-vous donc que Docker Desktop est installé sur votre ordinateur.
Étape 2 : Créer le fichier docker-compose.yml
- Créez un dossier nommé KAG dans le répertoire racine du lecteur D (ou d'un autre disque).
- Dans le dossier KAG, créez un nouveau fichier appelé docker-compose.yml.
- Copiez et collez le code YAML suivant dans le fichier docker-compose.yml et enregistrez-le.
version: "3.7"
services:
server:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latest
container_name: release-openspg-server
ports:
- "8887:8887"
depends_on:
- mysql
- neo4j
- minio
# volumes:
# - /etc/localtime:/etc/localtime:ro
environment:
TZ: Asia/Shanghai
LANG: C.UTF-8
command: [
"java",
"-Dfile.encoding=UTF-8",
"-Xms2048m",
"-Xmx8192m",
"-jar",
"arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",
'--server.repository.impl.jdbc.host=mysql',
'--server.repository.impl.jdbc.password=openspg',
'--builder.model.execute.num=5',
'--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j',
'--cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j'
]
mysql:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latest
container_name: release-openspg-mysql
volumes:
- mysql_data:/var/lib/mysql
environment:
TZ: Asia/Shanghai
LANG: C.UTF-8
MYSQL_ROOT_PASSWORD: openspg
MYSQL_DATABASE: openspg
ports:
- "3306:3306"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci'
]
neo4j:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latest
container_name: release-openspg-neo4j
ports:
- "7474:7474"
- "7687:7687"
environment:
- TZ=Asia/Shanghai
- NEO4J_AUTH=neo4j/neo4j@openspg
- NEO4J_PLUGINS=["apoc"]
- NEO4J_server_memory_heap_initial__size=1G
- NEO4J_server_memory_heap_max__size=4G
- NEO4J_server_memory_pagecache_size=1G
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=*
- NEO4J_dbms_security_procedures_allowlist=*
volumes:
- neo4j_logs:/logs
- neo4j_data:/data
minio:
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latest
container_name: release-openspg-minio
command: server --console-address ":9001" /data
restart: always
environment:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio@openspg
TZ: Asia/Shanghai
ports:
- 9000:9000
- 9001:9001
volumes:
- minio_data:/data
volumes:
mysql_data:
neo4j_logs:
neo4j_data:
minio_data:
Étape 3 : Démarrer le service KAG
- Ouvrez une invite de commande et passez au répertoire du dossier KAG (entrez cmd dans le champ d'adresse du dossier KAG).
- Tapez docker-compose up -d dans la ligne de commande et entrez pour commencer l'installation et le déploiement automatisés de KAG.
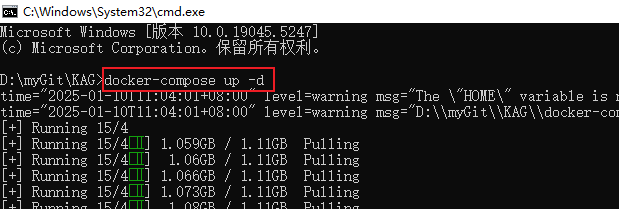
- Attendez un peu, lorsque vous verrez mysql, neo4j, openspg-server, minio quatre services affichent le statut Créé ou Démarré, cela signifie que le service KAG a été démarré avec succès.
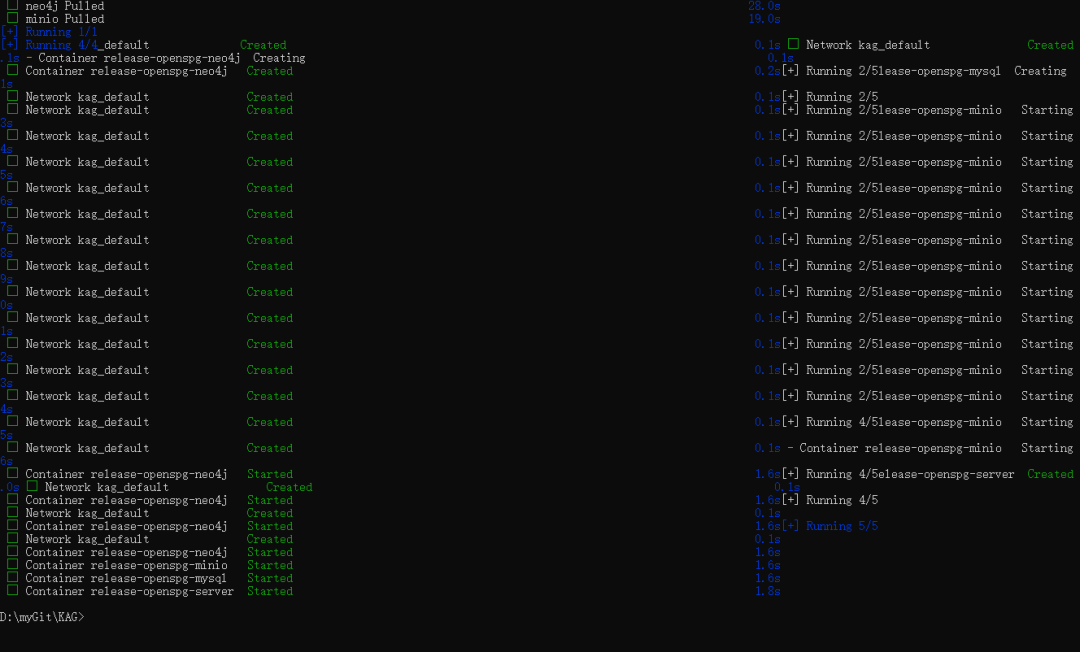
Étape 4 : Visiter la page d'administration du backend de KAG
- Ouvrez votre navigateur et entrez l'adresse 127.0.0.1:8887 pour accéder à la page des opérations de fond de KAG.
- Connectez-vous au système en utilisant le nom d'utilisateur par défaut openspg et le mot de passe par défaut openspg@kag.
Étape 5 : Configurer le système KAG
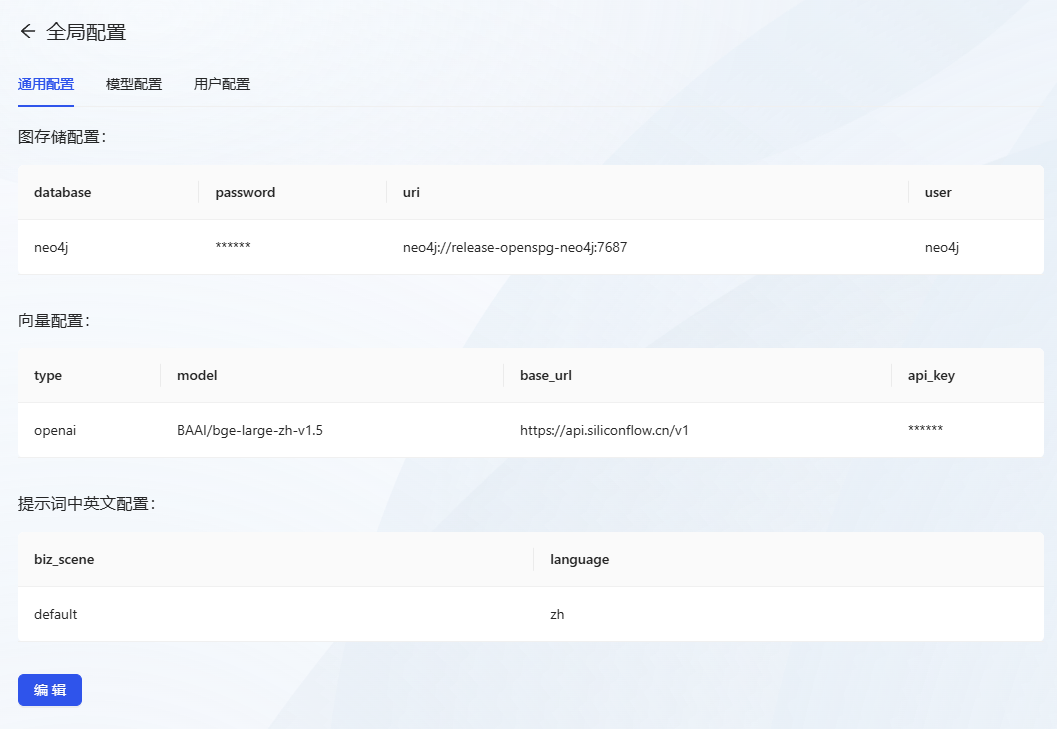
- Après avoir ouvert une session, cliquez d'abord sur le menu Configuration globale.
- Configuration communeConfiguration : Effectuez la configuration suivante
- Figure Configuration du stockage
- base de données:neo4j
- mot de passe : neo4j@openspg
- uri:neo4j://release-openspg-neo4j:7687
- utilisateur:neo4j
- Repères en anglais et en chinois
- biz_scene : default
- Langue : zh
- configuration vectorielle (informatique) (en utilisant l'API de modélisation vectorielle gratuite)
- type : openai
- modèle : BAAI/bge-large-zh-v1.5
- base_url :https://api.siliconflow.cn/v1
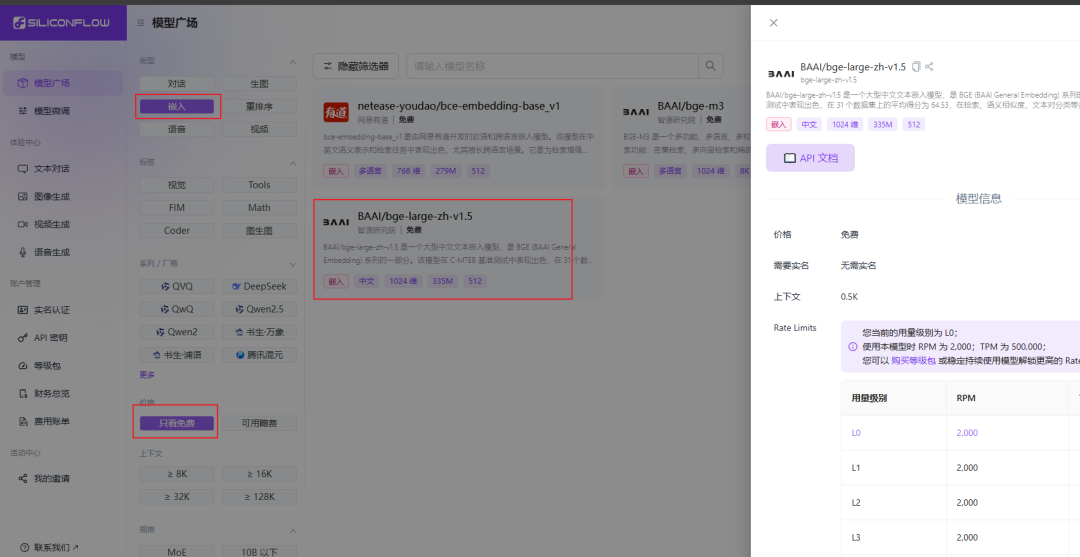
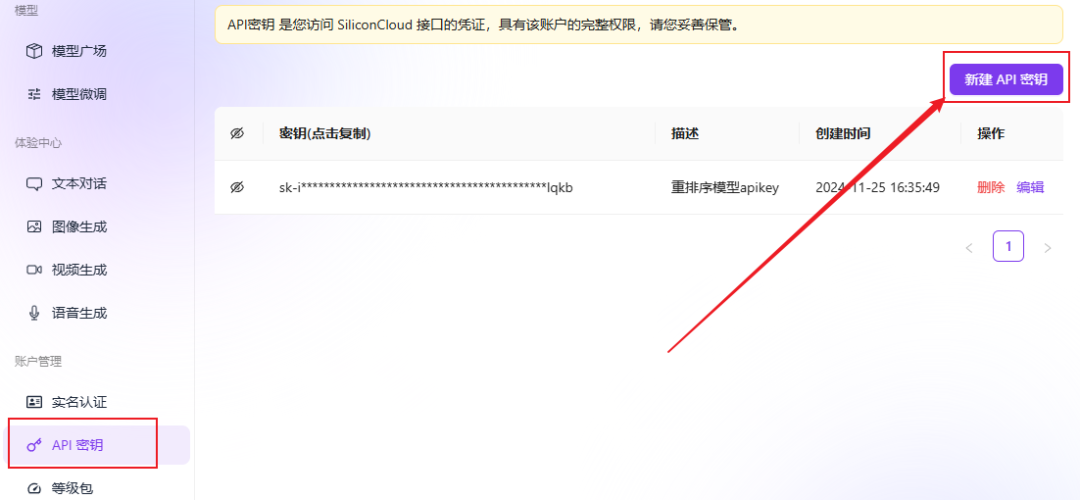
- api_key : aller à Flux à base de silicium pour obtenir une clé API gratuite.
- Flux à base de silicium Après vous être enregistré et connecté à la plateforme, vous pouvez trouver le modèle vectoriel gratuit et créer une clé API en suivant les instructions de l'image ci-dessous.
- Configuration du modèle: Cliquez Ajout du modèle maas (compatible avec l'interface openai)Configurez le modèle de grande langue que vous souhaitez utiliser.
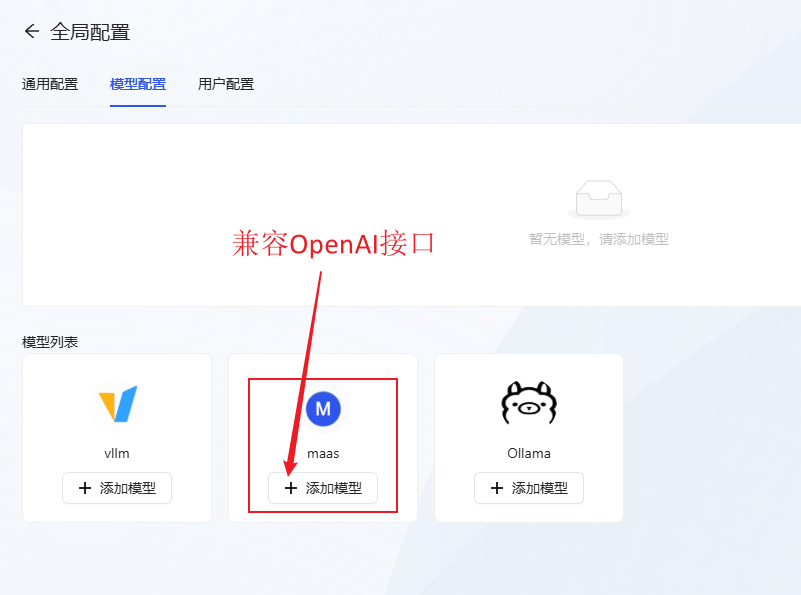
- Prenez l'exemple de gpt-4o, remplissez les informations sur le modèle et cliquez sur OK pour sauvegarder.
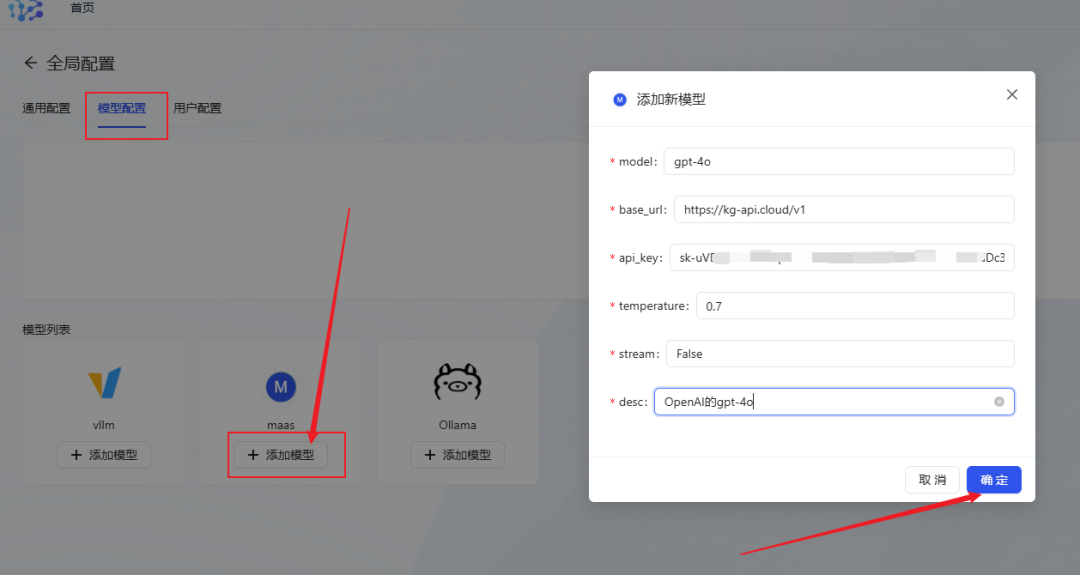
- Modèle de recommandation de station relais APISi vous avez des besoins variés en matière d'appels API pour les grands modèles, vous pouvez envisager d'utiliser le service de transit API, qui est compatible avec l'interface OpenAI, prend en charge la commutation en un clic entre les grands modèles nationaux et internationaux, et fournit des services MJ, SD, et Suno et d'autres interfaces de dessin et de création musicale. Le prix est également plus avantageux.
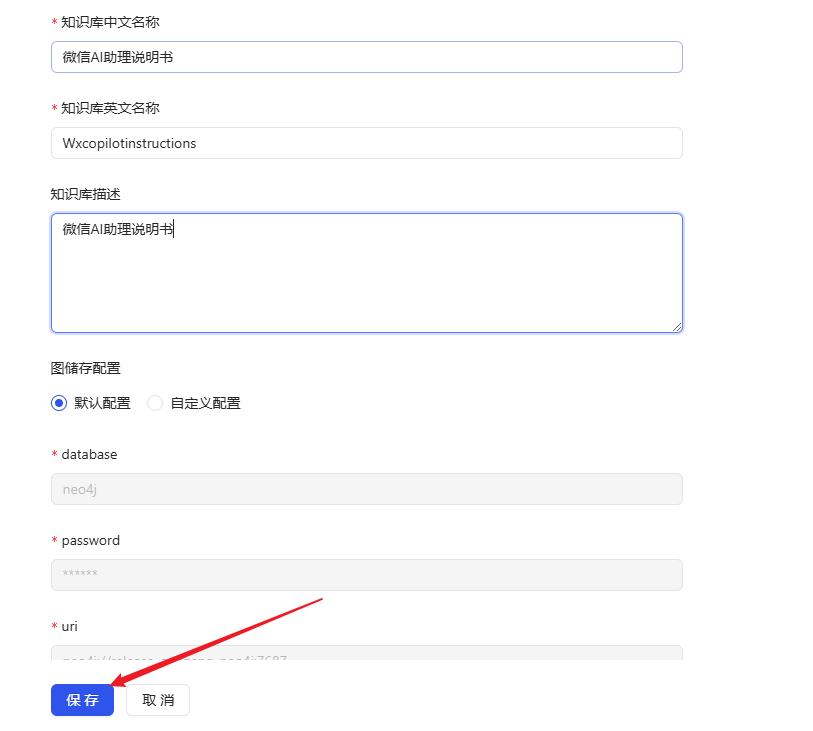
Étape 6 : Créer une base de connaissances et importer des documents
- Revenez à la page d'accueil et cliquez sur Créer une base de connaissances.

- Donnez un nom à la base de connaissances et cliquez sur Enregistrer.
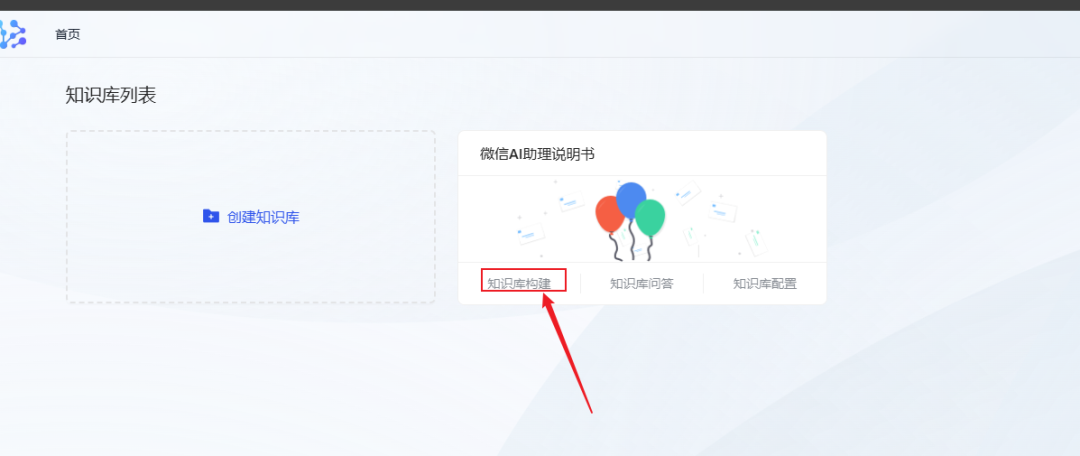
- Une fois la création réussie, trouvez la base de connaissances nouvellement créée sur la page d'accueil et cliquez sur Création de la base de connaissances.
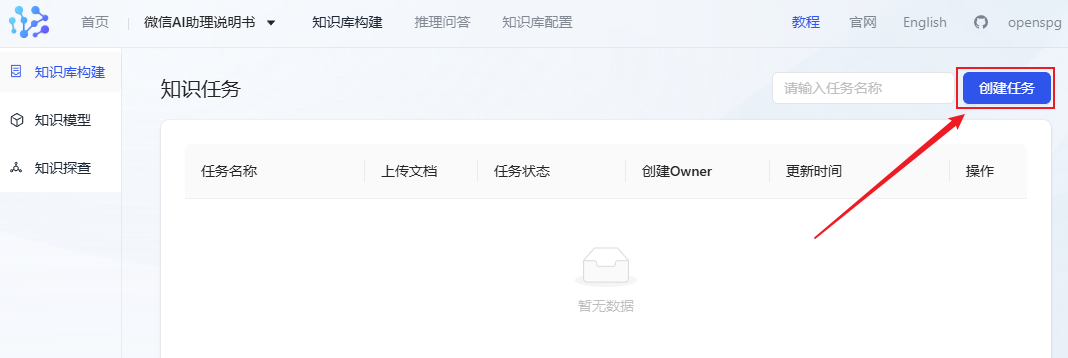
- Cliquez sur Créer une tâche pour commencer à importer des documents.
- Téléchargez les documents de votre base de connaissances (actuellement, KAG ne permet de télécharger qu'un seul document à la fois, si vous avez plusieurs documents, vous devez les télécharger par lots). Ici, j'ai téléchargé des documents relatifs à mon dernier produit, WeChat AI Assistant.
- Appel au partage d'outils de fusion de fichiersSi vous avez un bon outil gratuit de fusion de fichiers, n'hésitez pas à le partager dans la section des commentaires pour faciliter le traitement par lots des documents.
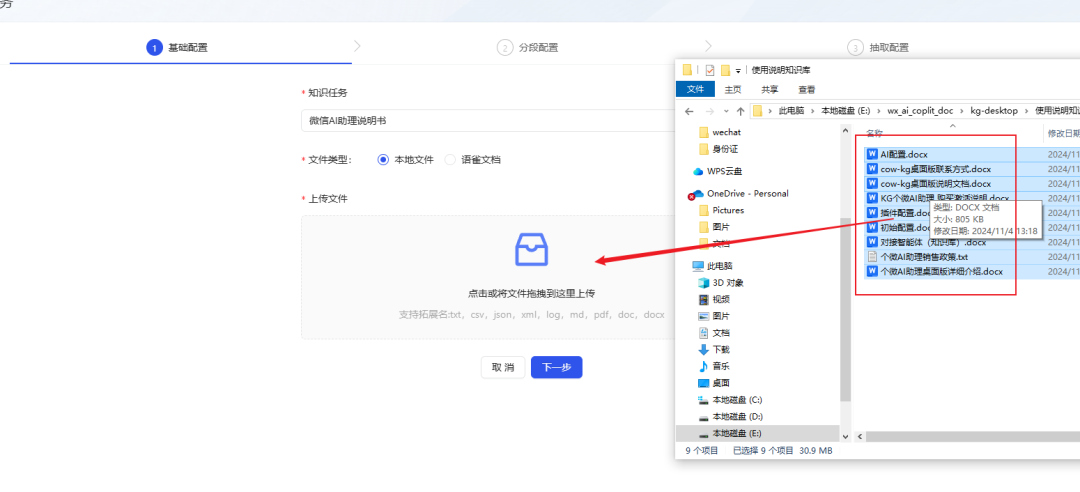
- Dans l'étape suivante de la configuration, il est recommandé de cocher la case permettant de couper les paragraphes en fonction de la sémantique du document afin de préserver la cohérence contextuelle des paragraphes.
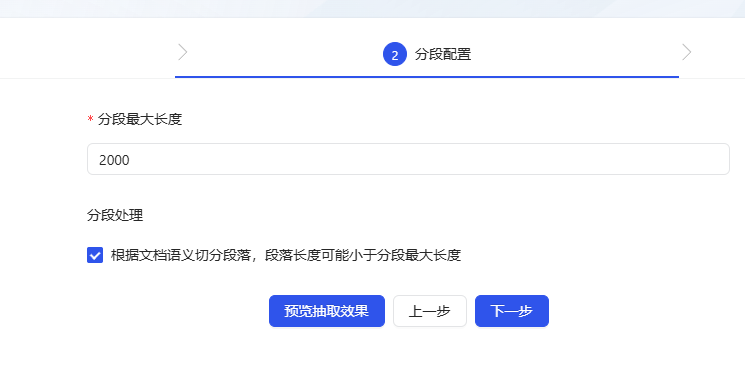
- modèle d'extraction option par défaut (la configuration par défaut est correcte). indice Il peut être personnalisé selon les besoins, ici je l'ai simplement réglé sur "Q&A Split" (la compréhension n'est pas toujours exacte, n'hésitez pas à me corriger).
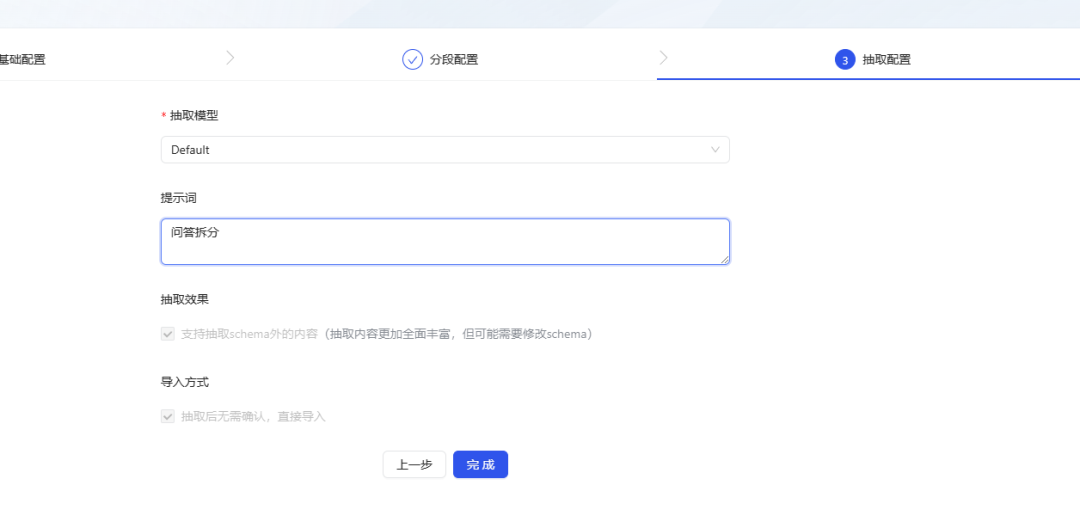
- Cliquez sur Terminer et le KAG commence à extraire et à analyser les documents, un processus qui peut prendre un certain temps.
- Le processus d'analyse de documents est divisé en 6 étapes, comme le montre la figure ci-dessous :
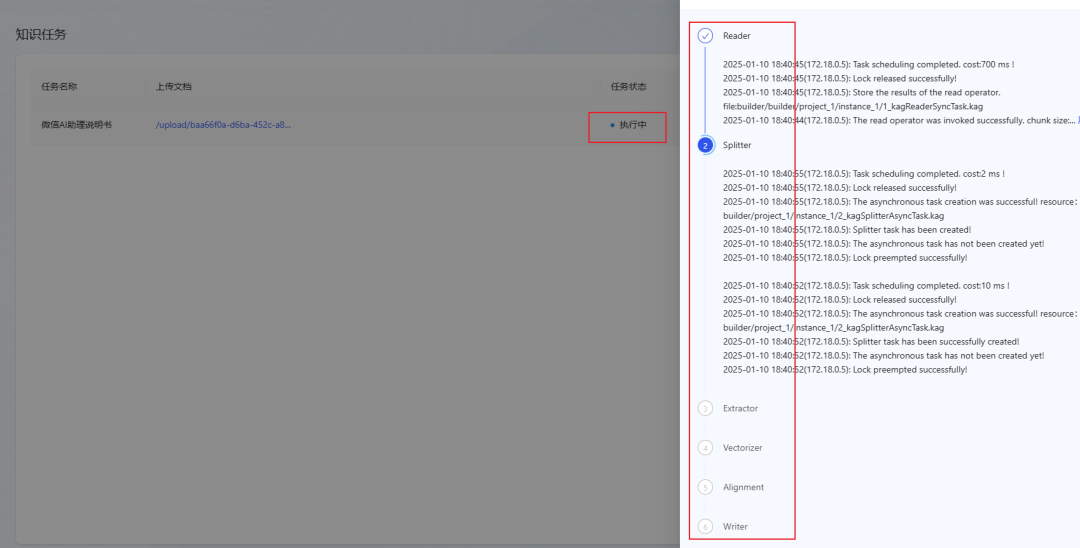
- Attendez que le statut de la tâche passe à Terminé, indiquant que le document a été importé avec succès dans la base de connaissances. (Si le statut n'a pas été mis à jour depuis longtemps, essayez d'actualiser la page).
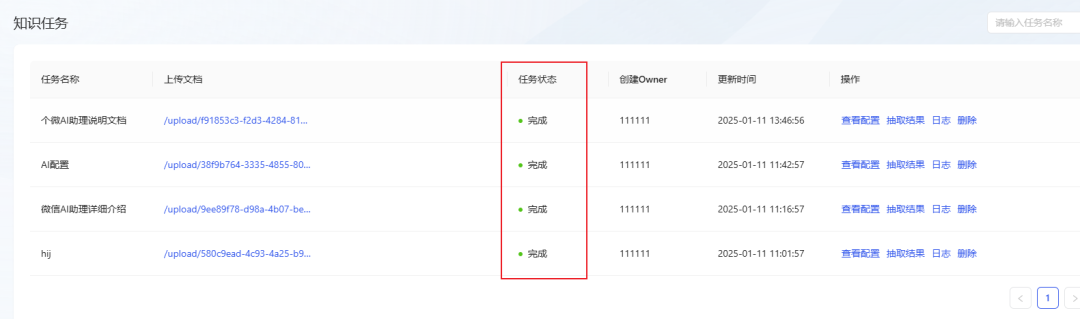
Étape 7 : Démonstration
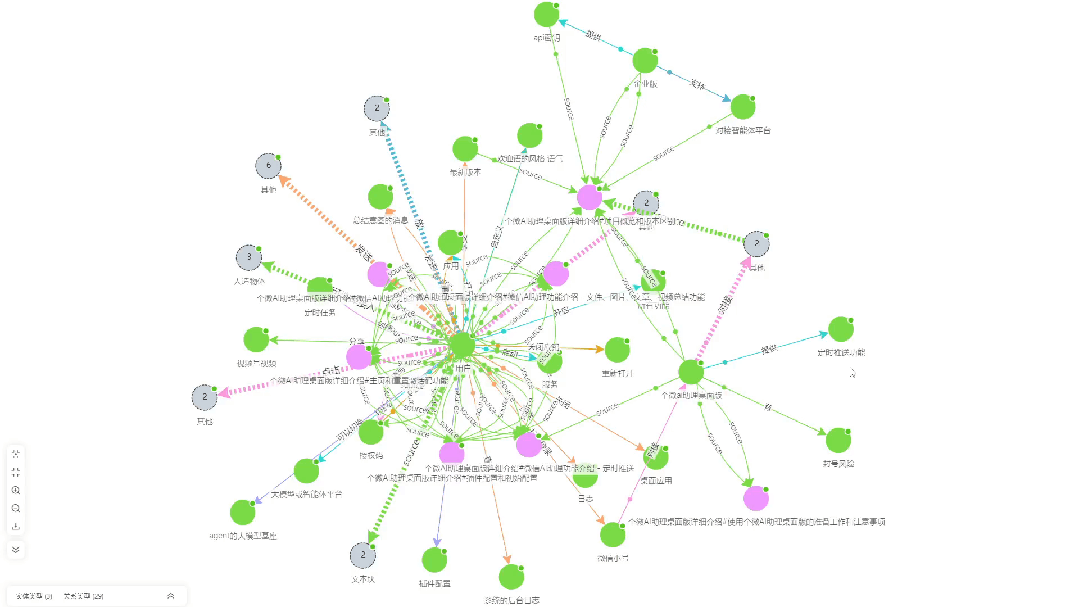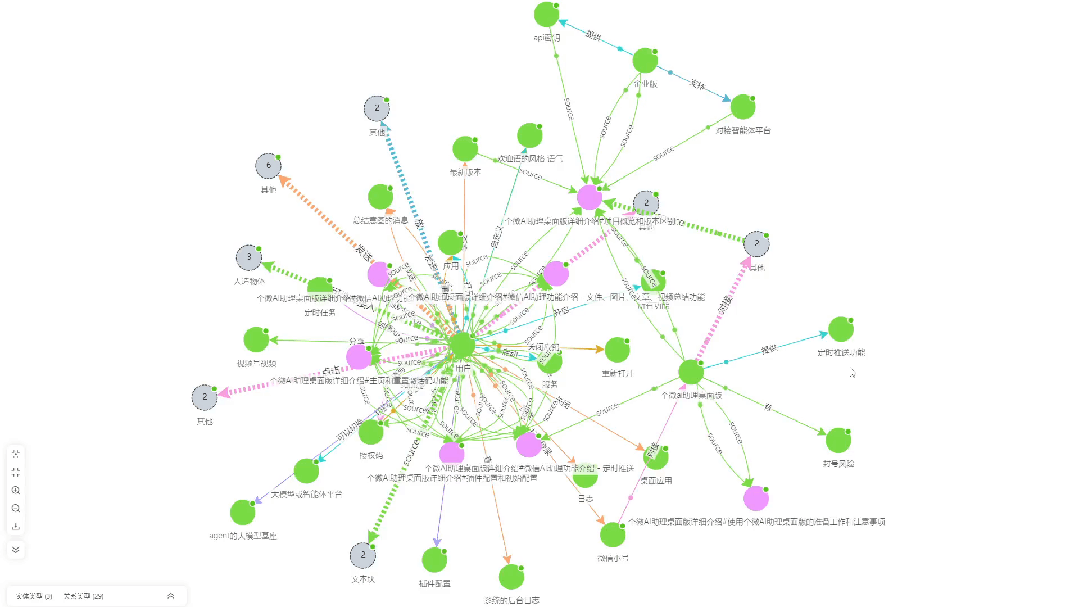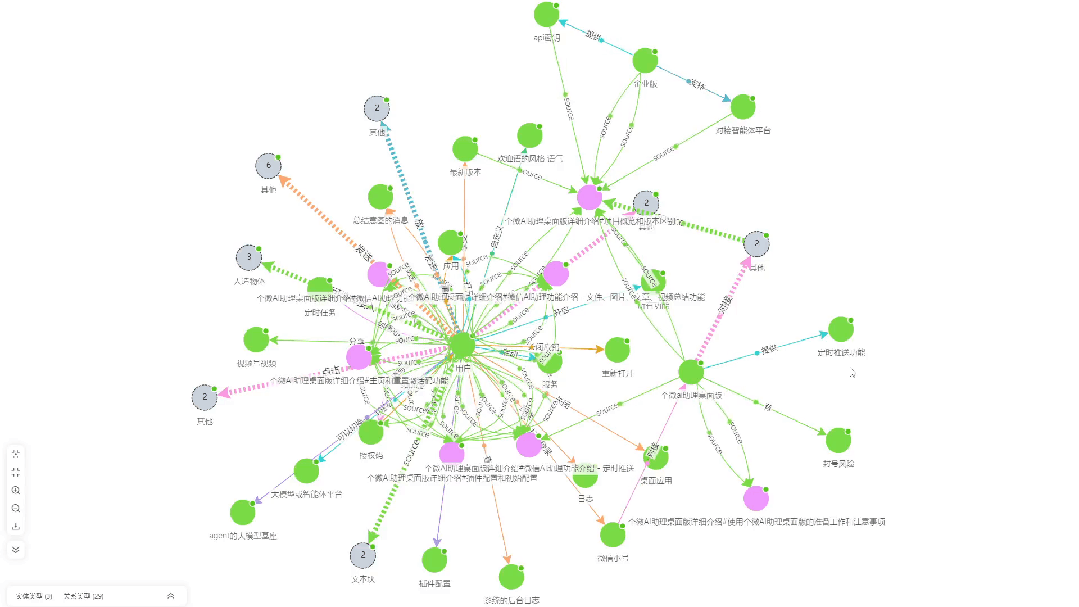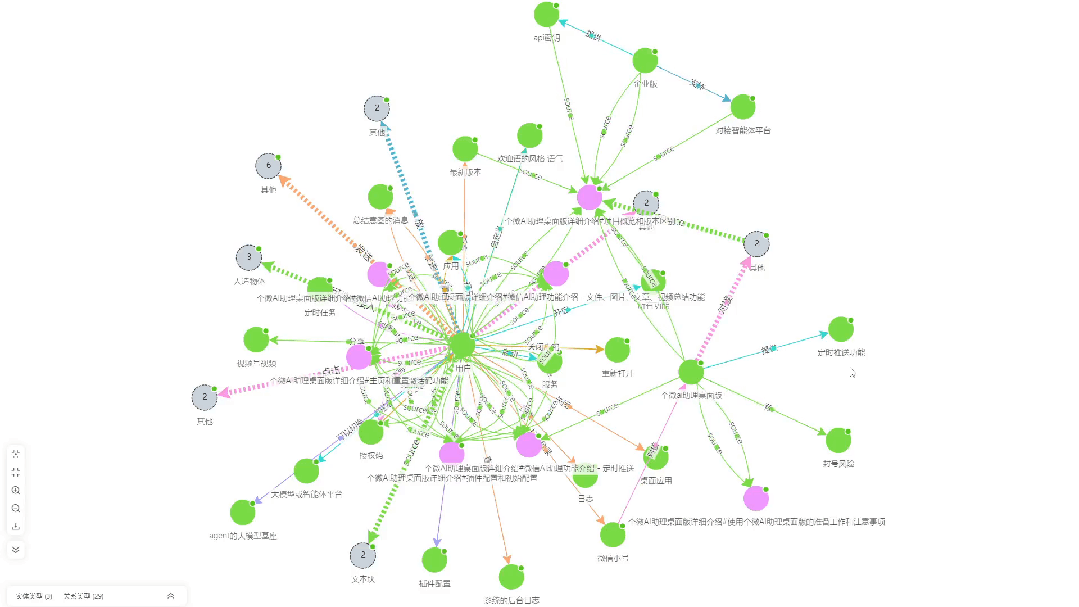
- Diagramme de corrélation pour l'extraction de connaissancesCe document est une visualisation des associations de connaissances extraites par KAG à partir du document.
- Test d'efficacité des questions-réponses: :
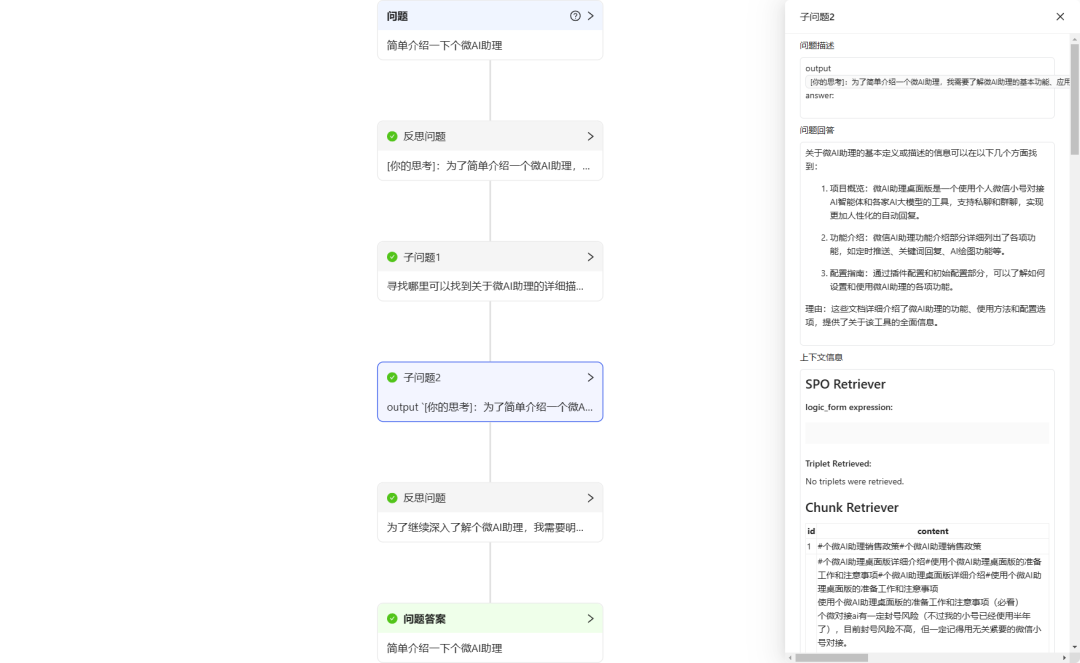
- Question 1 : "Présentez brièvement l'assistant personnel Micro AI".
KAG effectue un processus de réflexion et de raisonnement avant de trouver et de donner la réponse. On peut constater que les réponses données par KAG sont relativement précises et complètes. Cependant, le temps de réponse est lent, environ 40 secondes (KAG n'est donc peut-être pas adapté à des scénarios simples de questions-réponses).

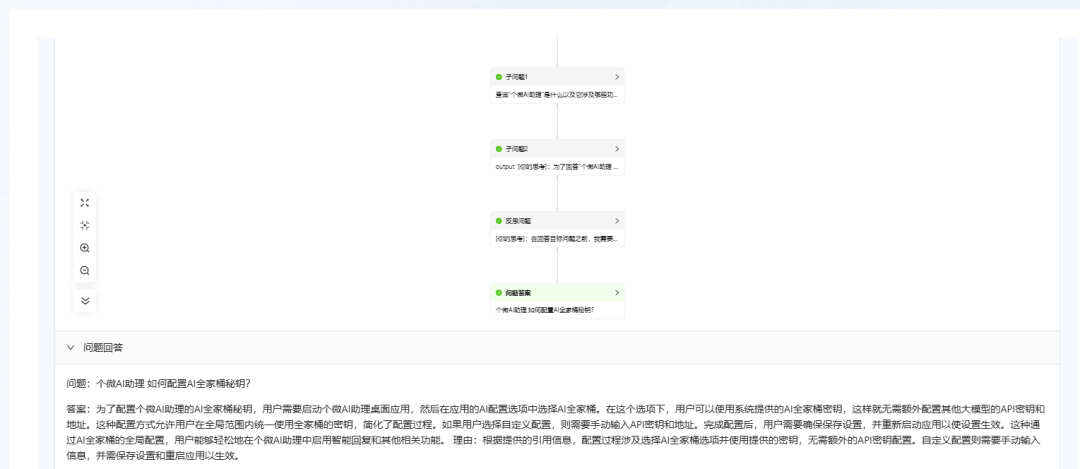
- Question 2 : "Comment configurer la clé secrète de l'AI Family Bucket pour le Personal Micro AI Assistant ?"
KAG est également en mesure de fournir une réponse, mais cela prend plus de temps.
Résumé et perspectives
Grâce à l'expérience ci-dessus, nous pouvons voir que le cadre de la base de connaissances KAG est encore en phase de développement rapide, certaines fonctionnalités et l'expérience de l'utilisateur doivent encore être améliorées (comme l'ajustement des paramètres de la base de connaissances, l'édition de la base de connaissances et la modification de la fonction ne sont pas parfaites, l'utilisation de l'utilisation de certains bogues peut également être rencontrée). Cependant, d'après les mises à jour de Github, l'équipe de KAG procède activement à l'itération du code et à l'optimisation fonctionnelle.
L'orientation technique de KAG, qui fusionne les graphes de connaissance et la recherche vectorielle, est très prometteuse. Tout comme la technologie RAG nécessite des données de base de connaissances de haute qualité, l'augmentation du modèle et le réglage des paramètres pour obtenir des résultats optimaux, le développement de KAG nécessite également une amélioration et une optimisation continues.
Comme mentionné au début de l'article, KAG est mieux adapté à des domaines spécialisés tels que les soins de santé, la finance, le droit, le gouvernement, etc., qui nécessitent un raisonnement complexe, plutôt qu'à des scénarios simples de questions-réponses au jour le jour (où la réactivité est un défaut).
À l'heure actuelle, KAG n'a pas encore ouvert l'API, et l'on s'attend à ce qu'après l'ouverture de l'API à l'avenir, elle puisse être intégrée dans l'application Agent, et grâce au mécanisme d'identification des problèmes, les problèmes simples et complexes peuvent être déplacés pour tirer parti des avantages de KAG dans le traitement des problèmes complexes.
Dans l'ensemble, cet article vise à vous donner un aperçu de la technologie de pointe qu'est KAG. Bien que KAG ne soit pas encore parfait, il a montré un grand potentiel en tant que cadre de base de connaissances open source. Nous pensons qu'avec les efforts conjoints de la communauté et l'itération continue de la technologie, KAG apportera plus de possibilités dans le domaine des bases de connaissances IA.
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes



Pas de commentaires...