Knowledge Table : un outil open source pour l'extraction et l'exploration efficaces de données structurées

Introduction générale
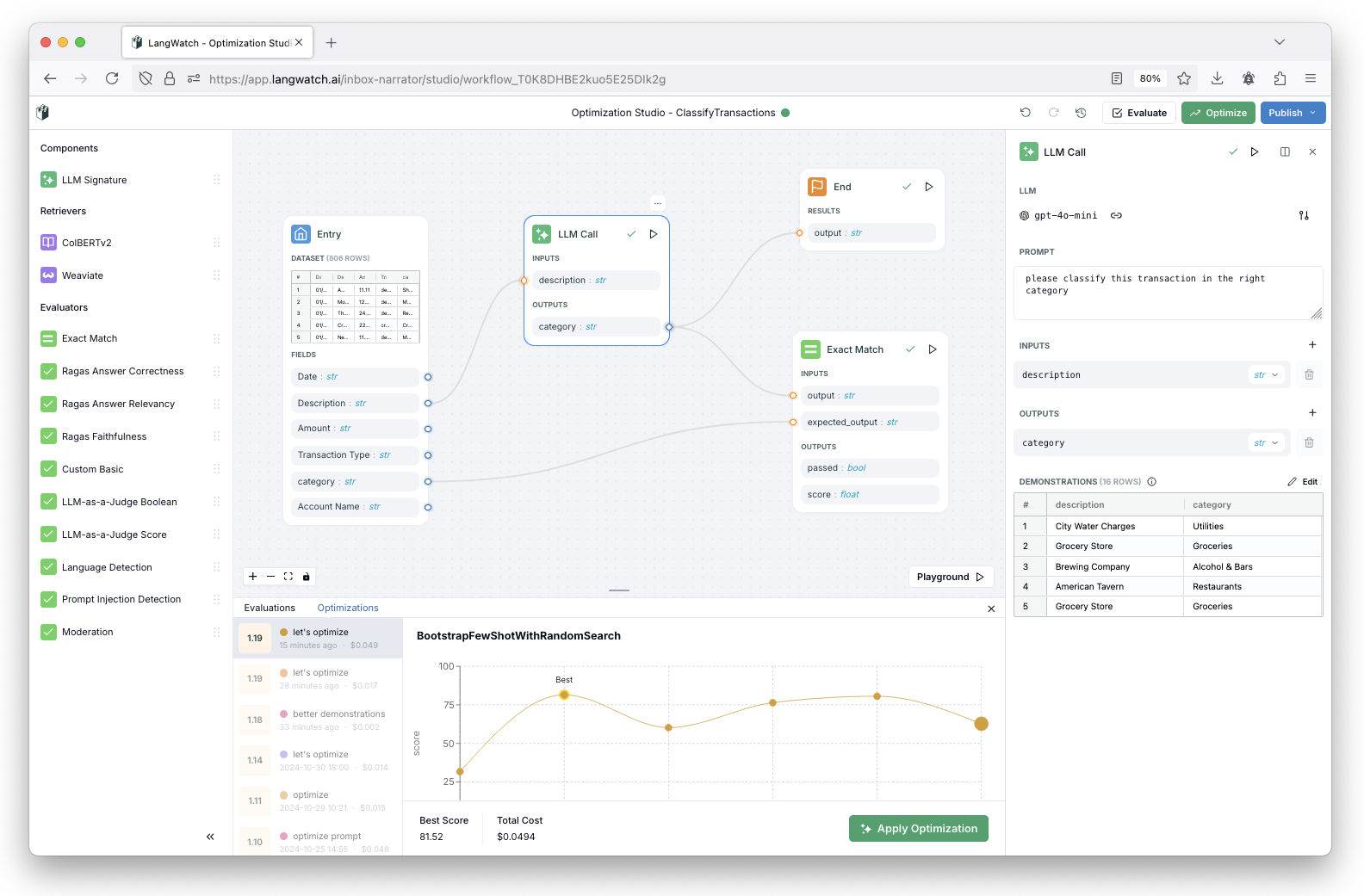
Knowledge Table est un projet open source conçu pour simplifier le processus d'extraction et d'exploration de données structurées à partir de documents non structurés. Les utilisateurs peuvent créer des représentations de connaissances structurées telles que des tableaux et des graphiques par le biais d'une interface d'interrogation en langage naturel. L'outil prend en charge des règles d'extraction et des options de formatage personnalisées, et assure la traçabilité des données en affichant les sources de données par le biais d'une interface utilisateur. Knowledge Sheets offre aux utilisateurs professionnels une interface familière de feuille de calcul, tout en fournissant aux développeurs un backend flexible et hautement configurable pour une variété de besoins de traitement de données.


Liste des fonctions
- l'extraction du langage naturel (ELN)Les données structurées peuvent être extraites de documents non structurés à l'aide de requêtes en langage naturel.
- Règles d'extraction personnaliséesLes utilisateurs peuvent définir des règles d'extraction pour garantir la qualité des données.
- contrôle du formatLe format de sortie des données extraites peut être contrôlé.
- Filtrage des documentsFiltrer les documents en fonction des métadonnées ou des données extraites.
- Exportation de triades au format CSV ou cartographiqueLe logiciel permet de télécharger les données extraites au format CSV ou au format tuple.
- extraction de la chaîneLes questions peuvent faire référence à des chroniques antérieures.
Utiliser l'aide
Installation et fonctionnement
- Docker en cours d'exécution: :
- Assurez-vous que Docker et Docker Compose sont installés.
- Utilisation des commandes
docker-compose up -d --buildLancer l'application. - Accès à la partie frontale
http://localhost:3000et le back-endhttp://localhost:8000.
- opération locale: :
- Clonage de la base de code :
git clone https://github.com/yourusername/knowledge-table.git - Allez dans le répertoire backend et créez un environnement virtuel :
cd knowledge-table/backend/ python3 -m venv venv source venv/bin/activate # Windows使用 venv\Scripts\activate pip install -r requirements.txt - Démarrer le service back-end :
cd src/ python -m uvicorn knowledge_table_api.main:app
- Clonage de la base de code :
- Paramètres frontaux: :
- Allez dans le répertoire front-end et installez les dépendances :
cd ../frontend/ curl https://bun.sh/install | bash # 安装Bun bun install bun start - Les services frontaux se trouvent dans la section
http://localhost:5173Accès.
- Allez dans le répertoire front-end et installez les dépendances :
Processus d'utilisation
- Télécharger un documentLes documents non structurés sont téléchargés dans la table des connaissances, le système les divise en morceaux et les stocke dans une base de données vectorielle.
- Définition des problèmes et des règlesDéfinir le type de données à extraire et les questions correspondantes, que le système traitera sur la base de ces informations.
- Voir les résultatsL'utilisateur peut visualiser le résultat structuré après le traitement des données et procéder aux ajustements nécessaires.
mise en garde
- Veiller à ce que les lois et règlements pertinents soient respectés afin d'éviter de porter atteinte aux droits et aux intérêts d'autrui.
- Les données extraites sont régulièrement validées afin de garantir leur exactitude et leur actualité.
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes

Pas de commentaires...