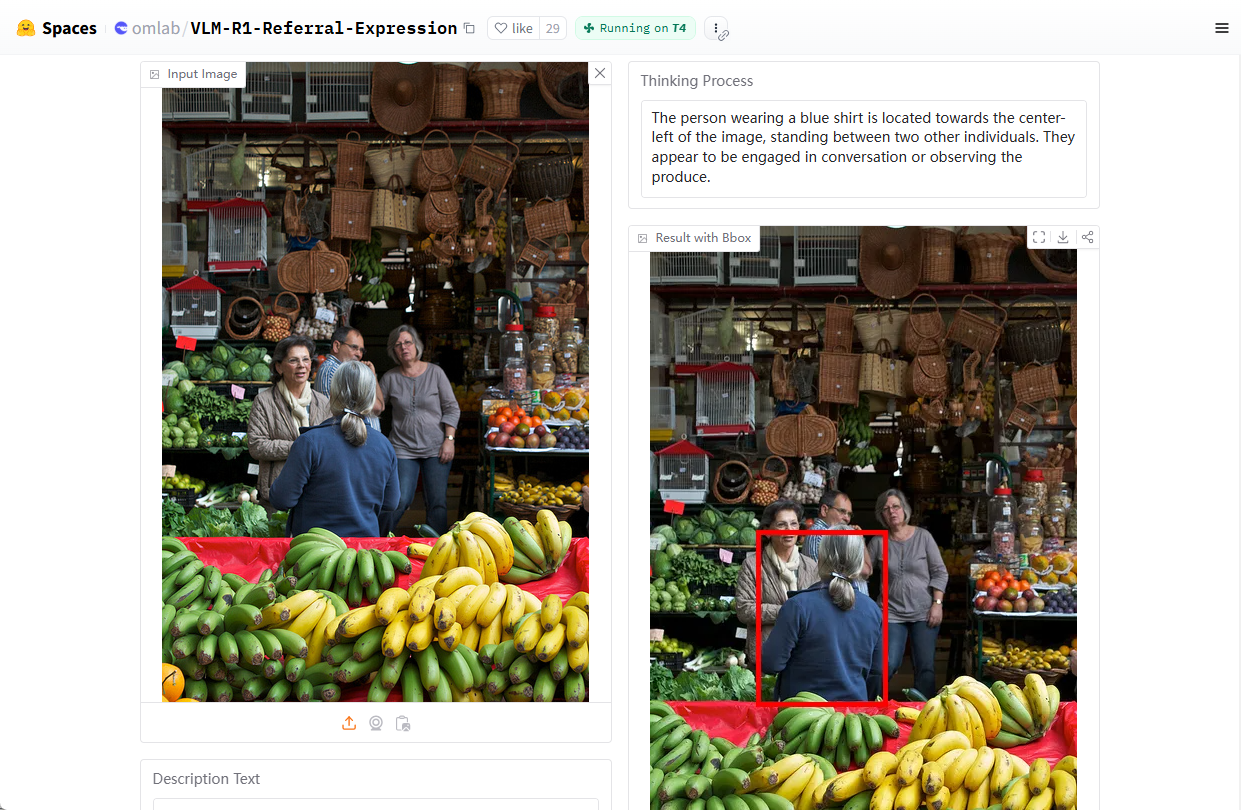
Llama 3.2 Reasoning WebGPU : Exécuter Llama-3.2 dans un navigateur

Introduction générale
Transformers.js est une bibliothèque JavaScript fournie par Hugging Face et conçue pour exécuter des modèles d'apprentissage automatique de pointe directement dans le navigateur sans l'aide d'un serveur. La bibliothèque est fonctionnellement équivalente à la bibliothèque de transformateurs de Hugging Face pour Python et prend en charge un large éventail de modèles et de tâches pré-entraînés, y compris le traitement du langage naturel, la vision par ordinateur et le traitement audio. L'exemple "llama-3.2-reasoning-webgpu" de ce projet est conçu pour démontrer les capacités de raisonnement du modèle LLama-3.2 sur le WebGPU, permettant aux utilisateurs de faire l'expérience d'un raisonnement de modèle de langage efficace directement dans le navigateur. Cet exemple démontre non seulement l'état de l'art de la technologie, mais donne également un aperçu de la manière dont la puissance de calcul des navigateurs modernes peut être exploitée pour traiter des tâches complexes d'intelligence artificielle.
Liste des fonctions
- Exécuter le modèle LLama-3.2 dans un navigateurLeveraging WebGPU technology for efficient model inference (Tirer parti de la technologie WebGPU pour une inférence efficace des modèles).
- Démonstration des performances du WebGPULes résultats de l'étude ont été publiés dans la revue WebGPU : ils mettent en évidence la supériorité des WebGPU en comparant les performances sur différents appareils.
- Offrir une expérience interactive à l'utilisateurLes utilisateurs peuvent interagir avec le modèle par le biais d'une interface simple, en saisissant du texte et en obtenant les résultats de l'inférence du modèle.
- Exemples de code et tutorielsLe site comprend des échantillons de code complets et des instructions sur la façon de configurer et d'exécuter le modèle LLama-3.2.
Utiliser l'aide
Environnement d'installation et de configuration
Étant donné que cet exemple s'exécute dans un environnement de navigateur, aucune étape d'installation particulière n'est requise, mais vous devez vous assurer que votre navigateur prend en charge le WebGPU :
- Vérification de la prise en charge des navigateurs: :
- Lorsque vous ouvrez la page d'exemple, le navigateur vérifie automatiquement si le WebGPU est pris en charge et, si ce n'est pas le cas, la page affiche une invite appropriée.
- WebGPU est actuellement pris en charge dans les dernières versions de Chrome, Edge et Firefox. Pour les utilisateurs de Safari, des fonctionnalités expérimentales spécifiques peuvent devoir être activées.
- Visitez la page d'exemple: :
- Accès direct via un lien sur GitHub
llama-3.2-reasoning-webgpuLa page d'exemple du
- Accès direct via un lien sur GitHub
exemple d'utilisation
- Modèles de chargement: :
- Une fois la page chargée, le chargement du modèle LLama-3.2 commencera automatiquement. Le processus de chargement peut prendre quelques minutes en fonction de la vitesse de l'internet et des performances de l'appareil.
- texte d'entrée: :
- Une fois la page chargée, vous verrez apparaître une zone de saisie de texte. Saisissez-y le texte sur lequel vous voulez raisonner.
- processus de raisonnement: :
- Cliquez sur le bouton "Raisonnement" et le modèle commencera à traiter vos données. Veuillez noter que le processus de raisonnement peut prendre un certain temps, en fonction de la longueur et de la complexité du texte.
- Voir les résultats: :
- Le modèle LLama-3.2 génère des résultats d'inférence basés sur vos données, qui peuvent être une réponse à une question, une traduction ou une forme de traitement du texte.
- Débogage et contrôle des performances: :
- Lors de l'inférence, la page peut afficher des statistiques de performance telles que la vitesse d'inférence (tokens par seconde, TPS). Cela vous aide à comprendre les capacités du WebGPU et les performances de l'appareil actuel.
Poursuite de l'étude et de l'exploration
- Étude du code source: Vous pouvez vous faire une bonne idée de ce qui se passe en regardant le code source sur GitHub (en particulier la section
worker.js) pour comprendre comment le modèle fonctionne dans le navigateur. - Modifications et contributionsSi vous êtes intéressé, vous pouvez cloner ce projet afin d'y apporter des modifications ou de nouvelles fonctionnalités. Le projet utilise l'interface Réagir et Vite, et si vous êtes familier avec ces outils, vous pouvez développer avec une relative facilité.
mise en garde
- Compatibilité avec les navigateursPour plus d'informations, veuillez consulter le site web de la Commission européenne : Assurez-vous que votre navigateur est à jour pour bénéficier d'une expérience optimale.
- dépendance à l'égard des performancesLes performances sont affectées par le matériel de l'appareil (en particulier le GPU) puisque l'inférence a lieu du côté du client.
- entreprise privéeLe traitement des données est effectué localement et n'est pas téléchargé sur un serveur, ce qui permet de protéger la confidentialité des données de l'utilisateur.
Grâce à ces étapes et instructions, vous pouvez explorer et utiliser pleinement cet exemple de projet pour découvrir les progrès de la technologie de l'IA dans votre navigateur.
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes



Pas de commentaires...