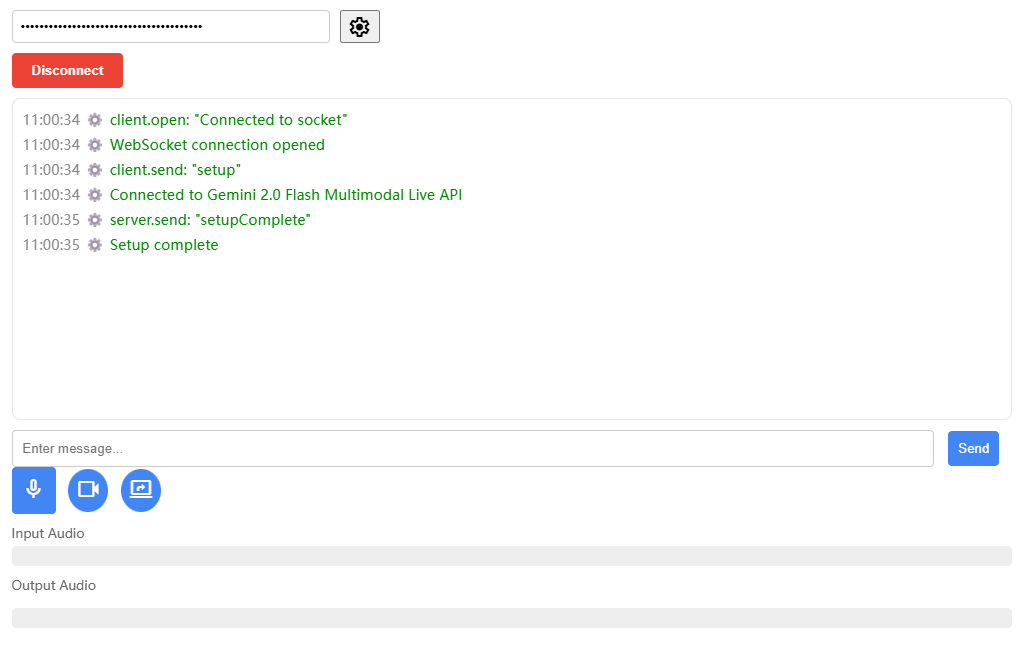
Ming-lite-omni - Macromodèles multimodaux unifiés open source par l'équipe Ant 100

Ming-lite-omni是什么
Ming-Lite-Omni是蚂蚁集团百灵大模型团队开源的统一多模态大模型,基于高效的Mixture of Experts(MoE)架构构建。Ming-Lite-Omni支持处理文本、图像、音频和视频等多种模态的数据,具备强大的理解和生成能力。在图像识别、视频理解、语音问答等任务上,模型均展现出卓越的性能,支持全模态输入输出,能实现自然流畅的多模态交互体验。Ming-Lite-Omni优化计算效率,支持处理大规模数据且支持实时交互,具有高度的可扩展性。模型应用场景广泛,为用户提供一体化的智能解决方案,具有广阔的应用前景。

Ming-lite-omni的主要功能
- interaction multimodale:支持文本、图像、音频、视频等多种输入输出,实现自然流畅的交互体验。支持多轮对话,提供连贯的交互。
- 理解与生成:强大的理解能力,能准确识别和理解多种模态的数据。高效的生成能力,支持生成高质量的文本、图像、音频和视频内容。
- Traitement efficace:基于MoE架构,优化计算效率,支持大规模数据处理和实时交互。
Ming-lite-omni的官网地址
- HuggingFace模型库: :https://huggingface.co/inclusionAI/Ming-Lite-Omni
如何使用Ming-lite-omni
- Préparation de l'environnement: :
- 安装Python:推荐使用Python 3.8或更高版本。从Python官网下载并安装。
- 安装依赖库:在终端或命令行中运行以下命令,安装必要的依赖库。
pip install -r requirements.txt
pip install data/matcha_tts-0.0.5.1-cp38-cp38-linux_x86_64.whl
pip install diffusers==0.33.0
pip install nvidia-cublas-cu12==12.4.5.8 # 如果使用NVIDIA GPU- Télécharger les modèles:从Hugging Face下载Ming-Lite-Omni模型。
git clone https://huggingface.co/inclusionAI/Ming-Lite-Omni
cd Ming-Lite-Omni- Modèles de chargement:使用以下代码加载模型和处理器:
import os
import torch
from transformers import AutoProcessor, GenerationConfig
from modeling_bailingmm import BailingMMNativeForConditionalGeneration
# 设置模型路径
model_path = "Ming-Lite-Omni-Preview"
# 加载模型
model = BailingMMNativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True
).to("cuda")
# 加载处理器
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)- 准备输入数据:根据需求准备输入数据。Ming-Lite-Omni支持多种模态输入,以文本和图像输入为例。
- saisie de texte: :
messages = [
{
"role": "HUMAN",
"content": [
{"type": "text", "text": "请详细介绍鹦鹉的生活习性。"}
],
},
]- 图像输入: :
messages = [
{
"role": "HUMAN",
"content": [
{"type": "image", "image": os.path.join("assets", "flowers.jpg")},
{"type": "text", "text": "What kind of flower is this?"}
],
},
]- Prétraitement des données:使用处理器对输入数据进行预处理:
text = processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = processor.process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
)
inputs = inputs.to(model.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)- 模型推理:调用模型进行推理,生成输出:
generation_config = GenerationConfig.from_dict({'no_repeat_ngram_size': 10})
generated_ids = model.generate(
**inputs,
max_new_tokens=512,
use_cache=True,
eos_token_id=processor.gen_terminator,
generation_config=generation_config,
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(output_text)- 输出结果:模型会生成相应的输出,根据需要进一步处理或展示结果。
Ming-Lite-Omni的核心优势
- 多模态融合:支持文本、图像、音频和视频等多种模态的输入和输出,实现全面的多模态交互。
- 高效架构:基于Mixture of Experts (MoE)架构,动态路由优化计算效率,减少资源浪费。
- 统一理解与生成:编码器-解码器架构支持一体化的理解和生成,提供连贯的交互体验。
- 优化推理:混合线性注意力机制降低计算复杂度,支持实时交互,适用快速响应场景。
- largement utilisé:适用智能客服、内容创作、教育、医疗和智能办公等多个领域。
- 开源与社区支持:开源模型,社区提供丰富资源,便于开发者快速上手和创新。
Ming-Lite-Omni的适用人群
- utilisateur professionnel:需要高效多模态解决方案的科技公司和内容创作企业。
- 教育工作者和学生:希望用AI辅助教学和学习的教师和学生。
- 医疗健康从业者:需要辅助病历分析和医学影像解读的医疗工作者。
- 智能办公用户:需要处理文档和提高办公效率的企业员工和管理层。
- 普通消费者:使用智能设备和需要生成创意内容的个人用户。
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes



Pas de commentaires...