
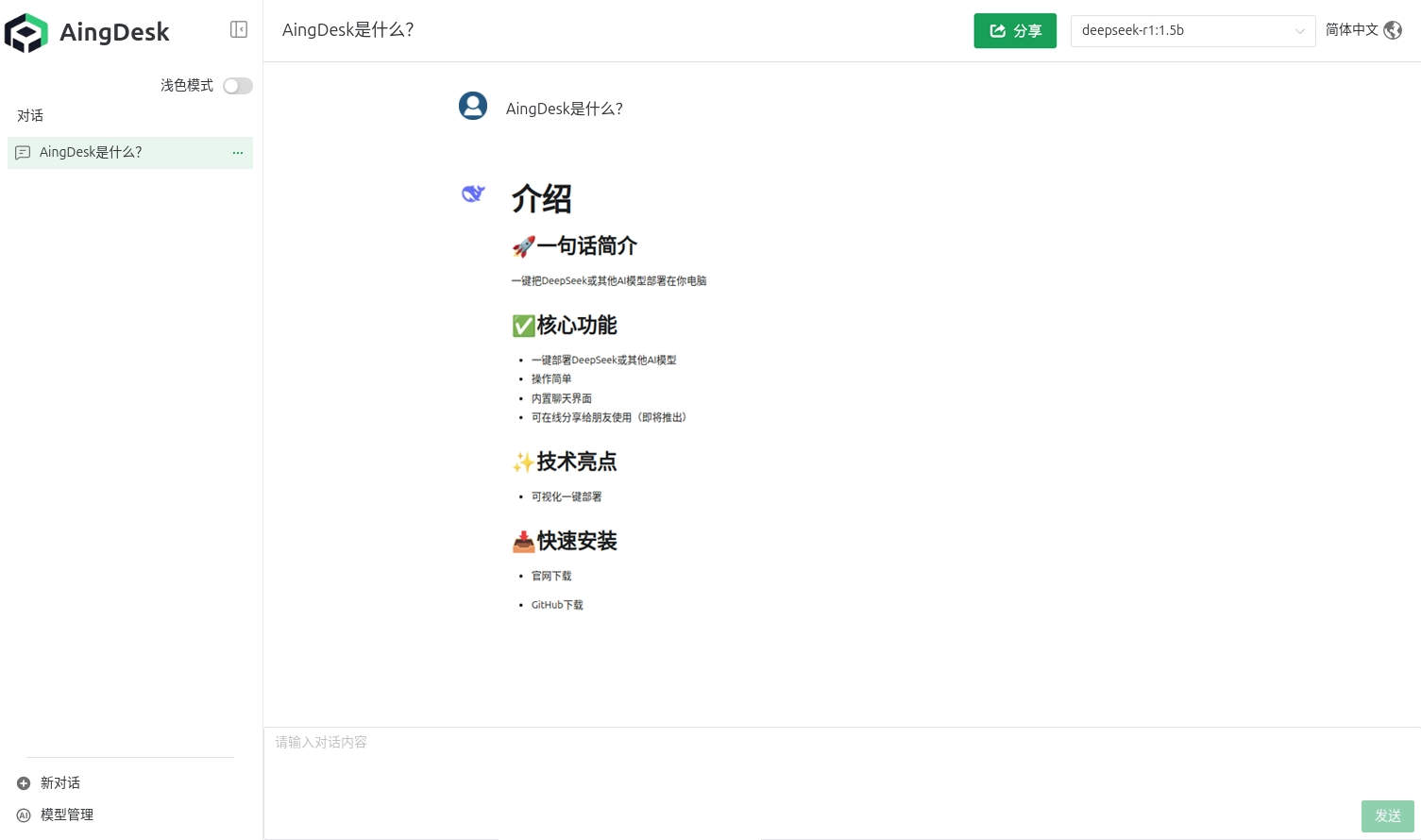
OmniParse:从文档/多媒体中提取任何非结构化数据解析为结构化数据

Introduction générale
OmniParse是一个强大的数据解析与优化平台,旨在将任何非结构化数据转换为结构化、可操作的数据,优化后适用于GenAI(生成式人工智能)框架。无论是处理文档、表格、图像、视频、音频文件还是网页内容,OmniParse都能让您的数据变得干净、结构化,并为AI应用程序如RAG(检索增强生成)和微调等做好准备。


- 开源演示地址:https://colab.research.google.com/github/adithya-s-k/omniparse/blob/main/examples/OmniParse_GoogleColab.ipynb
Liste des fonctions
- 完全本地化,无需外部API
- 适用于T4 GPU
- 支持约20种文件类型
- 将文档、多媒体和网页转换为高质量的结构化Markdown
- 表格提取、图像提取/字幕、音频/视频转录、网页爬取
- 使用Docker和Skypilot轻松部署
- 友好的Colab环境
- 由Gradio提供支持的交互式UI
Utiliser l'aide
Processus d'installation
- entrepôt de clones: :
git clone https://github.com/adithya-s-k/omniparse cd omniparse - 创建虚拟环境: :
conda create -n omniparse-venv python=3.10 conda activate omniparse-venv - Installation des dépendances: :
poetry install # 或者 pip install -e . # 或者 pip install -r pyproject.toml
使用Docker
- 从Docker Hub拉取OmniParse API镜像: :
docker pull savatar101/omniparse:0.1 - 运行Docker容器,暴露端口8000: :
# 如果使用GPU docker run --gpus all -p 8000:8000 savatar101/omniparse:0.1 # 否则 docker run -p 8000:8000 savatar101/omniparse:0.1
运行服务器
- 启动服务器: :
python server.py --host 0.0.0.0 --port 8000 --documents --media --web--documents:加载所有帮助解析和摄取文档的模型(如Surya OCR系列模型和Florence-2)。--media:加载Whisper模型以转录音频和视频文件。--web:设置Selenium爬虫。
支持的数据类型
- fichier (informatique): :
.doc,.docx,.pdf,.ppt,.pptx - 图像: :
.png,.jpg,.jpeg,.tiff,.bmp,.heic - 视频: :
.mp4,.mkv,.avi,.mov - 音频: :
.mp3,.wav,.aac - 网页:动态网页,
http://.com
exemple d'utilisation
- 文档解析: :
python server.py --host 0.0.0.0 --port 8000 --documents这将加载所有文档解析模型,准备处理文档类型的数据。
- 多媒体解析: :
python server.py --host 0.0.0.0 --port 8000 --media这将加载Whisper模型,准备处理音频和视频文件。
- 网页爬取: :
python server.py --host 0.0.0.0 --port 8000 --web这将设置Selenium爬虫,准备处理网页内容。
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes


Pas de commentaires...