Comment choisir le meilleur modèle d'intégration pour les applications RAG ?


L'incorporation de vecteurs est au cœur des applications actuelles de la Génération Augmentée de Récupération (GAR). Ils capturent les informations sémantiques des objets de données (par exemple, le texte, les images, etc.) et les représentent sous forme de tableaux de nombres. Dans les applications d'IA générative actuelles, ces vecteurs d'intégration sont généralement générés par des modèles d'intégration. Comment choisir le bon modèle d'intégration pour une application RAG ? Globalement, cela dépend du cas d'utilisation et des exigences spécifiques. Ensuite, décomposons les étapes afin d'examiner chacune d'entre elles individuellement.
01. identifier les cas d'utilisation spécifiques
Nous examinons les questions suivantes sur la base des exigences d'application du RAG :
Premièrement, le modèle générique est-il suffisant pour répondre aux besoins ?
Deuxièmement, y a-t-il des besoins spécifiques ? Par exemple, la modalité (texte ou image uniquement, pour les options d'intégration multimodale, voir la rubriqueComment choisir le bon modèle d'intégration"), des domaines spécifiques (par exemple, le droit, la médecine, etc.)
Dans la plupart des cas, un modèle générique est généralement choisi pour les modes souhaités.
02. sélection de modèles génériques
Comment choisir un modèle polyvalent ? Le classement du Massive Text Embedding Benchmark (MTEB) dans HuggingFace répertorie une variété de modèles d'incorporation de texte actuels, propriétaires et libres, et pour chaque modèle d'incorporation, le MTEB répertorie une variété de mesures, y compris les paramètres du modèle, la mémoire, les dimensions d'incorporation et le nombre maximum de tokens, Pour chaque modèle d'intégration, le MTEB énumère diverses mesures, notamment les paramètres du modèle, la mémoire, les dimensions d'intégration, le nombre maximal de tokens et leurs résultats dans des tâches telles que l'extraction et le résumé.
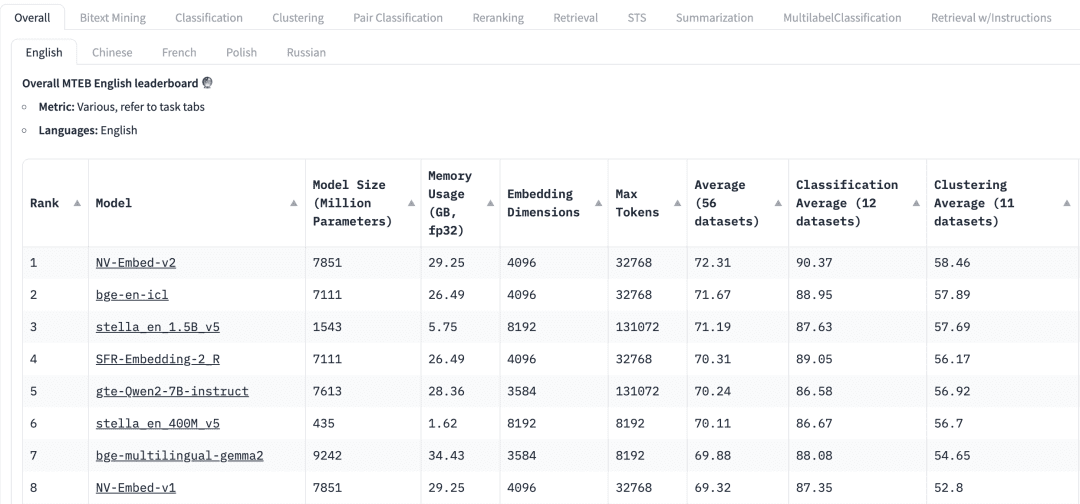
Les facteurs suivants doivent être pris en compte lors de la sélection d'un modèle d'intégration pour une application RAG :
mandatsLe tableau de bord de la MTEB : En haut du tableau de bord de la MTEB, nous verrons différents onglets de tâches. Pour une application RAG, il se peut que nous devions nous concentrer davantage sur la tâche "Récupérer", où nous pouvons choisir de Retrial Cet onglet.
multilinguismeLe modèle d'intégration est basé sur la langue de l'ensemble de données dans lequel le RAG est appliqué afin de sélectionner le modèle d'intégration pour la langue correspondante.
score: Indique la performance du modèle sur un ensemble de données de référence spécifique ou sur plusieurs ensembles de données de référence. Différentes mesures d'évaluation sont utilisées en fonction de la tâche. En règle générale, ces mesures prennent des valeurs comprises entre 0 et 1, les valeurs les plus élevées indiquant une meilleure performance.
Taille du modèle et utilisation de la mémoireCes mesures nous donnent une idée des ressources informatiques nécessaires à l'exécution du modèle. Si les performances de recherche s'améliorent avec la taille du modèle, il est important de noter que la taille du modèle affecte aussi directement la latence. En outre, les modèles de grande taille peuvent être surajustés et avoir une faible performance de généralisation, ce qui les rend peu performants en production. Par conséquent, nous devons rechercher un équilibre entre les performances et la latence dans un environnement de production. En général, nous pouvons commencer par un petit modèle léger et construire rapidement l'application RAG. Une fois que le processus sous-jacent de l'application fonctionne correctement, nous pouvons passer à un modèle plus grand et plus performant pour optimiser davantage l'application.
Dimensions de l'encastrement: Il s'agit de la longueur du vecteur d'intégration. Si des dimensions d'intégration plus importantes permettent de capturer des détails plus fins dans les données, les résultats ne sont pas nécessairement optimaux. Par exemple, avons-nous vraiment besoin de 8192 dimensions pour des données documentaires ? Probablement pas. En revanche, les dimensions d'intégration plus petites permettent une inférence plus rapide et sont plus efficaces en termes de stockage et de mémoire. Nous devons donc trouver un bon équilibre entre la capture du contenu des données et l'efficacité de l'exécution.
Nombre maximum de jetons: indique le nombre maximum de jetons pour un seul encapsulage. Pour les applications courantes de RAG, la meilleure taille de morceau pour l'intégration est généralement un seul paragraphe, auquel cas un modèle d'intégration avec un nombre maximal de tokens de 512 devrait suffire. Cependant, dans certains cas particuliers, nous pouvons avoir besoin de modèles avec un plus grand nombre de jetons pour traiter des textes plus longs.
03. évaluation des modèles dans les applications RAG
Bien que nous puissions trouver des modèles génériques dans les classements de la MTEB, nous devons traiter leurs résultats avec prudence. Sachant que ces résultats sont déclarés par les modèles eux-mêmes, il est possible que certains modèles produisent des scores qui gonflent leurs performances parce qu'ils peuvent avoir inclus les ensembles de données de la MTEB dans leurs données d'apprentissage, qui sont, après tout, des ensembles de données accessibles au public. En outre, les ensembles de données que les modèles utilisent pour l'étalonnage peuvent ne pas représenter fidèlement les données utilisées dans notre application. Nous devons donc évaluer les modèles d'intégration sur nos propres ensembles de données.
3.1 Ensembles de données
Nous pouvons générer un petit ensemble de données étiquetées à partir des données utilisées par l'application RAG. Prenons l'exemple de l'ensemble de données suivant.
| Langue | Description |
|---|---|
| C/C++ | Langage de programmation à usage général connu pour ses performances et son efficacité. largement utilisé dans le développement de systèmes/logiciels, de jeux et d'applications nécessitant des performances élevées. |
| Java | Langage de programmation polyvalent, orienté objet, conçu pour avoir le moins de dépendances possibles au niveau de l'implémentation. Il est largement utilisé pour la création d'applications d'entreprise, d'applications mobiles (en particulier Android) et d'applications web en raison de sa portabilité et de sa robustesse. |
| Python | Langage de programmation interprété de haut niveau, connu pour sa lisibilité et sa simplicité. Il prend en charge de nombreux paradigmes de programmation et est largement utilisé dans le développement web, l'analyse de données, l'intelligence artificielle, le calcul scientifique et l'automatisation. Il prend en charge de nombreux paradigmes de programmation et est largement utilisé dans le développement web, l'analyse de données, l'intelligence artificielle, le calcul scientifique et l'automatisation. |
| JavaScript | Langage de programmation dynamique de haut niveau principalement utilisé pour créer du contenu interactif et dynamique sur le web. Il s'agit d'une technologie essentielle pour le développement web frontal. Il s'agit d'une technologie essentielle pour le développement web frontal et elle est de plus en plus utilisée côté serveur avec des environnements tels que Node.js. |
| C# | Il est utilisé pour développer une large gamme d'applications, y compris des applications web, de bureau, mobiles et des jeux, en particulier au sein de l'écosystème Microsoft. Il est utilisé pour développer une large gamme d'applications, y compris des applications web, de bureau, mobiles et des jeux, en particulier au sein de l'écosystème Microsoft. |
| SQL | Langage spécifique à un domaine, utilisé pour la programmation et la gestion de bases de données relationnelles, essentiel pour l'interrogation, la mise à jour et la gestion des données dans les bases de données. Il est essentiel pour l'interrogation, la mise à jour et la gestion des données dans les bases de données et est largement utilisé dans l'analyse des données et la veille stratégique. |
| PHP | Il est intégré au HTML et est largement utilisé pour construire des pages web dynamiques et des applications, avec une forte présence dans les systèmes de gestion de contenu comme WordPress. Il permet également de créer des applications web dynamiques, avec une forte présence dans les systèmes de gestion de contenu tels que WordPress. |
| Golang | Langage de programmation compilé, à typage statique, conçu par Google. Connu pour sa simplicité et son efficacité, il est utilisé pour construire des applications évolutives et performantes, en particulier dans les services en nuage et les systèmes distribués. -et performantes, en particulier dans les services en nuage et les systèmes distribués. |
| Rouille | Langage de programmation de systèmes axé sur la sécurité et la concurrence, qui assure la sécurité de la mémoire sans utiliser de ramasse-miettes et qui est utilisé pour construire des logiciels fiables et efficaces, en particulier dans la programmation de systèmes et l'assemblage de sites web. Il assure la sécurité de la mémoire sans utiliser de ramasse-miettes et est utilisé pour construire des logiciels fiables et efficaces, en particulier dans la programmation de systèmes et l'assemblage de sites web. |
3.2 Création de l'intégration
Ensuite, nous utilisons lepymilvus[model]Pour l'ensemble de données ci-dessus, le vecteur Embedding correspondant est généré. à propos de l'ensemble de données. pymilvus[model] Pour l'utilisation, voir https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
Ensuite, l'Embedding généré est déposé dans la collection de Milvus.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 Requêtes
Nous définissons des fonctions d'interrogation pour faciliter le rappel du vecteur Embedding.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 Évaluation de la performance du modèle d'intégration
Nous utilisons deux modèles d'intégration de l'OpenAI.text-embedding-3-small répondre en chantant text-embedding-3-largepour les deux requêtes suivantes sont comparées. Il existe de nombreuses mesures d'évaluation telles que la précision, le rappel, le MRR, le MAP, etc. Ici, nous utilisons la précision et le rappel.
Précision Évalue le pourcentage de contenu réellement pertinent dans les résultats de la recherche, c'est-à-dire le nombre de résultats renvoyés qui sont pertinents par rapport à la requête.
Précision = TP / (TP + FP)
Dans ce cas, les vrais positifs (TP) sont ceux qui correspondent vraiment à la requête, tandis que les faux positifs (FP) sont ceux qui ne sont pas pertinents dans les résultats de la recherche.
Le rappel évalue la quantité de contenu pertinent récupéré avec succès à partir de l'ensemble des données.
Rappel = TP / (TP + FN)
Les faux négatifs (FN) désignent tous les éléments pertinents qui ne sont pas inclus dans l'ensemble des résultats finaux.
Pour une explication plus détaillée de ces deux concepts
Demande de renseignements 1: :auto garbage collection
Articles connexes : Java, Python, JavaScript, Golang
| Rang | texte-embedding-3-petit | texte-embedding-3-grand |
|---|---|---|
| 1 | ❎ Rouille | ❎ Rouille |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Précision | 0.50 | 0.50 |
| Rappel | 0.50 | 0.50 |
Demande de renseignements 2: :suite for web backend server development
Éléments connexes : Java, JavaScript, PHP, Python (les réponses incluent un jugement subjectif)
| Rang | texte-embedding-3-petit | texte-embedding-3-grand |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Précision | 0.75 | 1.0 |
| Rappel | 0.75 | 1.0 |
Pour ces deux requêtes, nous avons comparé les deux modèles d'intégration en termes de précision et de rappel. text-embedding-3-small répondre en chantant text-embedding-3-large Le modèle d'intégration peut être utilisé comme point de départ. Nous pouvons l'utiliser comme point de départ pour augmenter le nombre d'objets de données dans l'ensemble de données ainsi que le nombre de requêtes afin que le modèle d'intégration puisse être évalué plus efficacement.
04 Résumé
Dans les applications de génération augmentée de recherche (RAG), la sélection de modèles d'incorporation de vecteurs appropriés est cruciale. Dans cet article, nous montrons qu'après avoir sélectionné un modèle générique de la MTEB à partir des besoins réels de l'entreprise, la précision et le rappel sont utilisés pour tester le modèle sur la base d'un ensemble de données spécifiques à l'entreprise, afin de sélectionner le modèle d'incorporation le plus approprié, ce qui permet d'améliorer efficacement la précision du rappel de l'application de RAG.
Le code complet est disponible en téléchargement
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Articles connexes




Pas de commentaires...