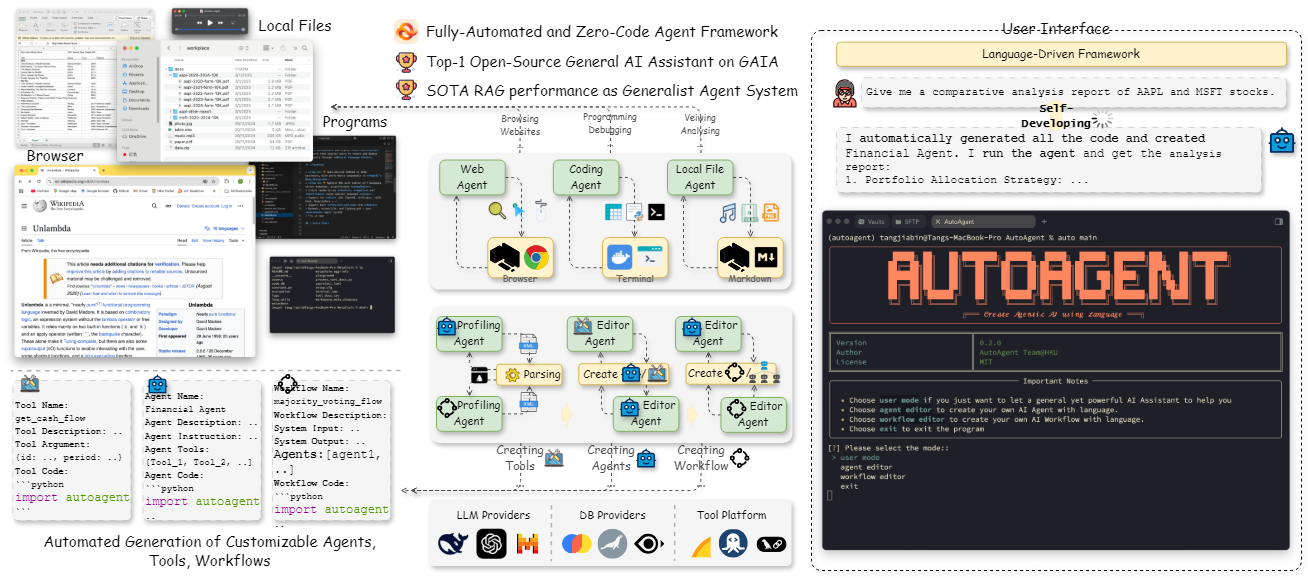
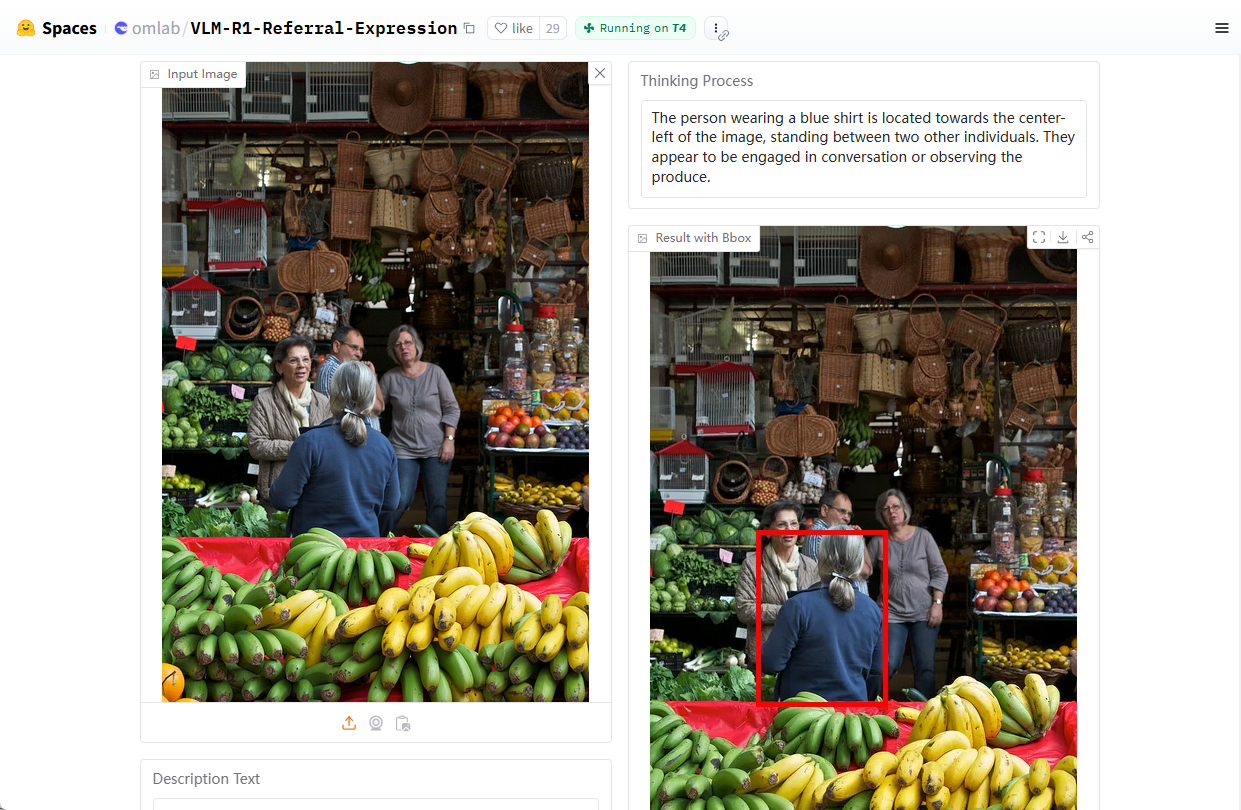
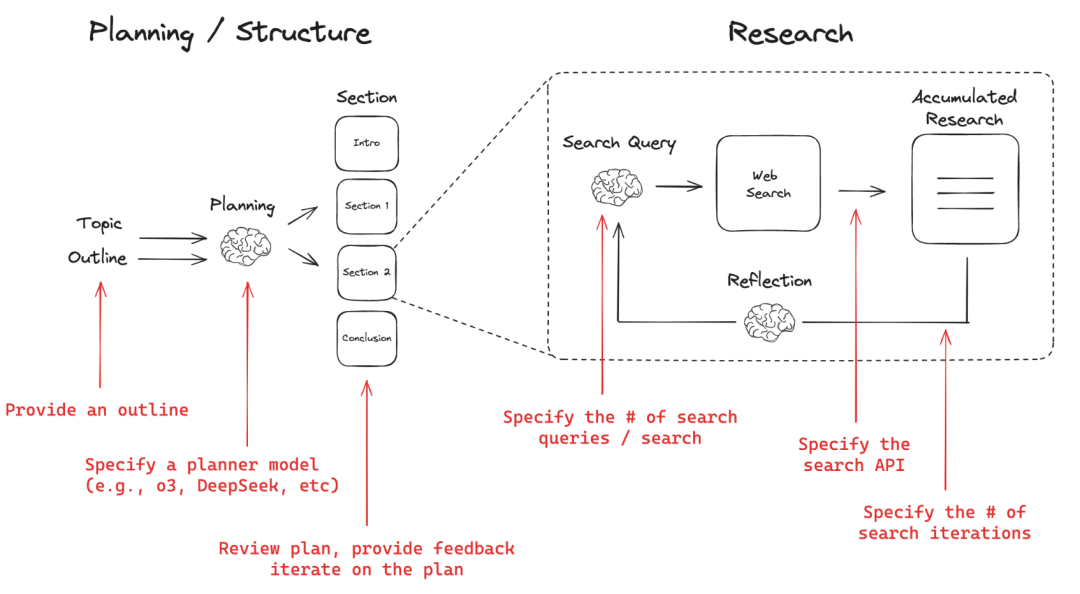
Introduction détaillée Crawl4LLM est un projet open source développé conjointement par l'université Tsinghua et l'université Carnegie Mellon, qui se concentre sur l'optimisation de l'efficacité de l'exploration du web pour le pré-entraînement des grands modèles (LLM). Il réduit considérablement l'inefficacité du crawling en sélectionnant intelligemment des données web de haute qualité, affirmant pouvoir...