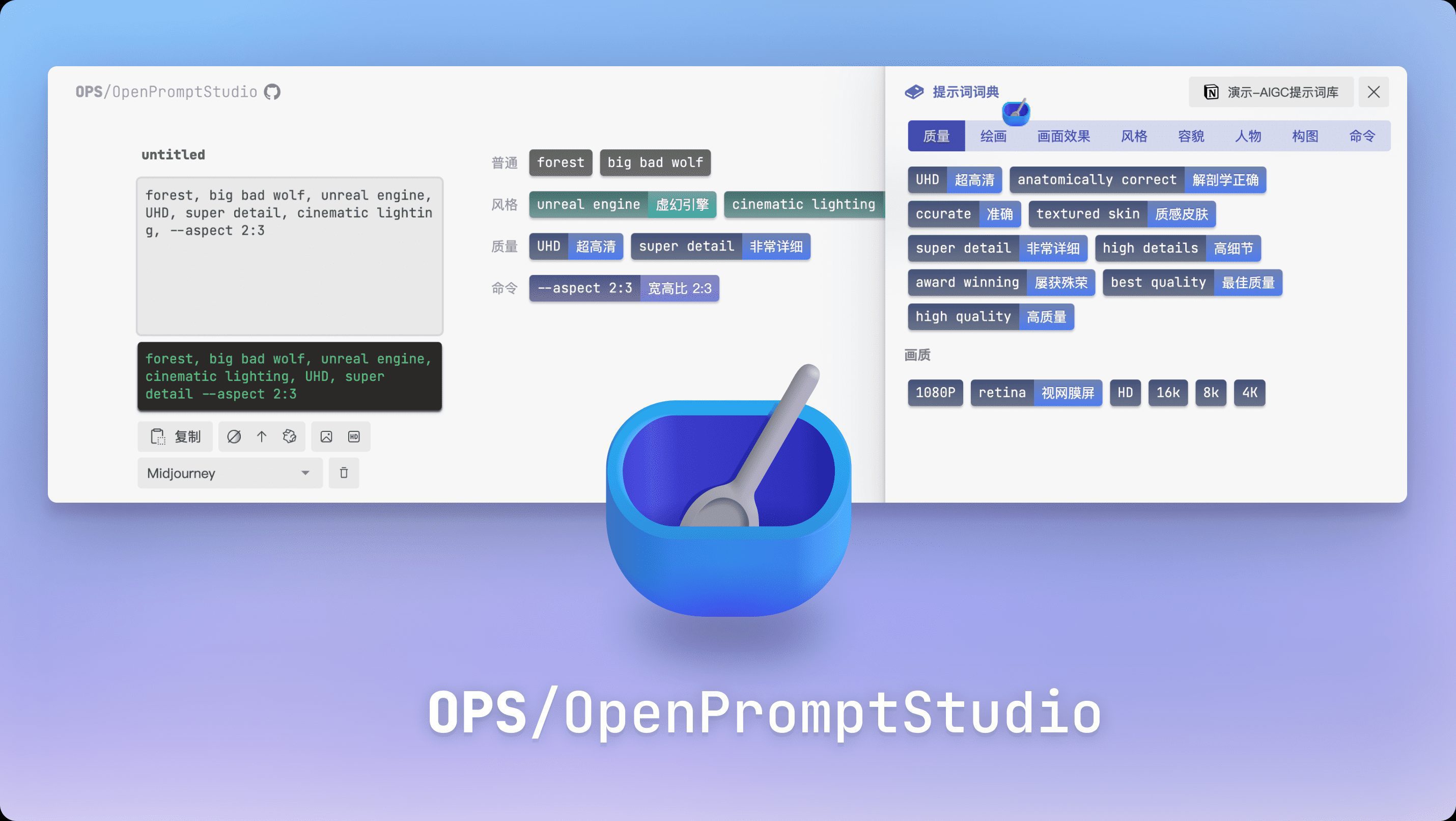
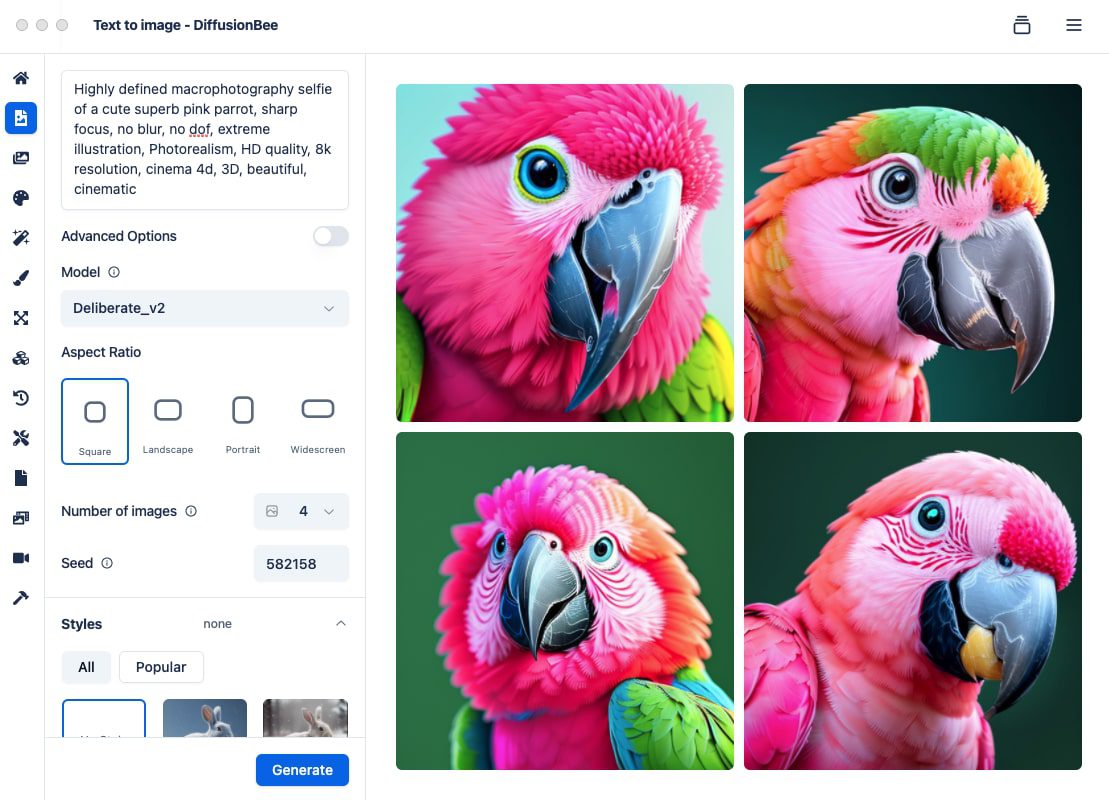
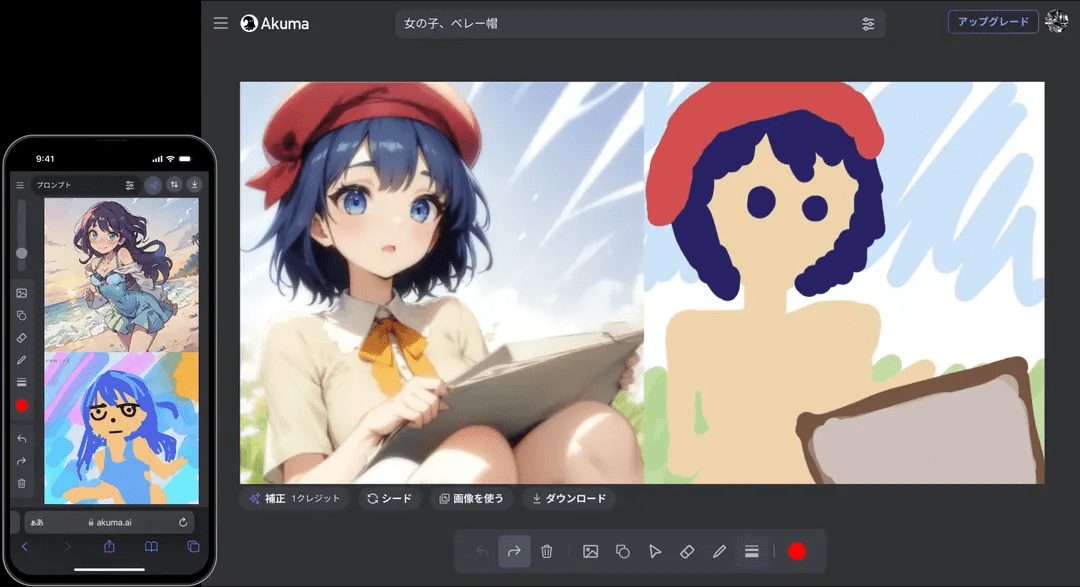
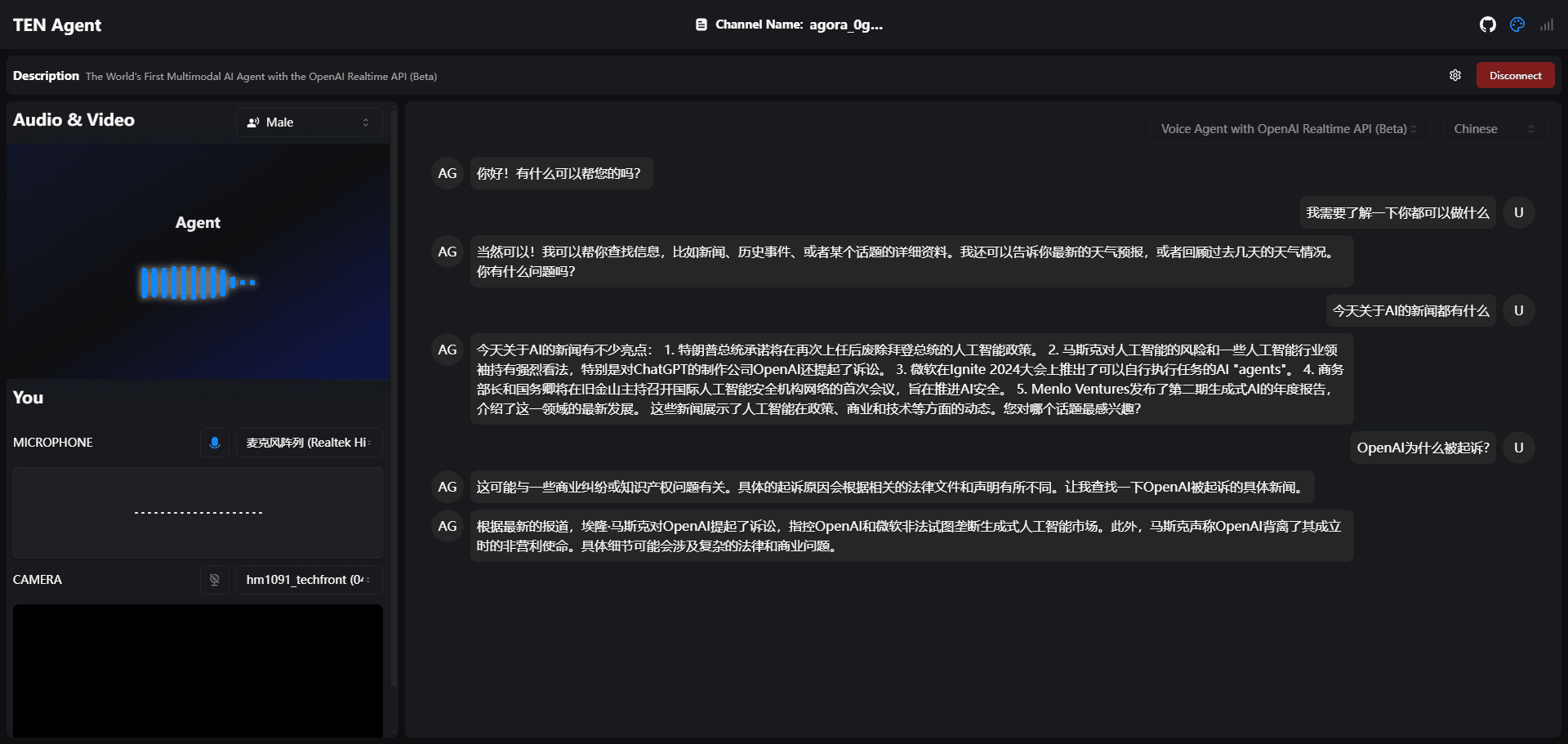
Introduction générale llama.cpp est une bibliothèque implémentée en C/C++ pur, conçue pour simplifier le processus d'inférence pour les grands modèles de langage (LLM). Elle prend en charge un large éventail de plates-formes matérielles, y compris Apple Silicon, les GPU NVIDIA et les GPU AMD, et fournit une variété de quant...