





Un cadre pour étendre le mot clé de Vincennes : améliorer la génération d'images par l'IA

Récemment, diverses technologies d'IA de type texte-image ont fait l'objet d'itérations rapides. Cependant, les débutants comme les créateurs professionnels sont souvent confrontés à un défi lorsqu'ils utilisent ces outils : comment traduire les idées créatives qu'ils ont en tête - qu'elles soient claires ou floues - en "invites" (mots) précises et efficaces. Il s'agit de traduire les idées créatives qu'ils ont en tête - qu'elles soient claires ou floues - en "invites" (mots) précises et efficaces, qui tirent pleinement parti de la capacité du modèle d'IA à produire une conception visuelle efficace et professionnelle.
En réponse à ce problème, un cadre généralisé de repères graphiques a été mis au point pour simplifier le processus. L'objectif de ce cadre est de servir de passerelle entre les idées créatives et les capacités de génération d'IA, en permettant aux utilisateurs de "piloter la conception avec des idées" d'une manière plus intuitive.
Vous trouverez ci-dessous des exemples d'images générées à l'aide du cadre, couvrant un large éventail de disciplines de conception telles que les jeux, les produits, le cinéma et la télévision, l'ameublement, les interfaces utilisateur (UI), les œuvres d'art et la photographie :

Sur la base des premiers retours d'expérience et des tests effectués par les utilisateurs, le cadre présente des avantages significatifs :
- Abaisser le seuil d'utilisation : Même les utilisateurs qui n'ont pas de formation en design ou d'expérience en IA peuvent utiliser le cadre pour générer des images de qualité professionnelle, permettant ainsi une expérience prête à l'emploi sans avoir besoin d'un apprentissage approfondi de l'ingénierie complexe des mots clés.
- Amélioration de l'efficacité professionnelle : Pour les créateurs et concepteurs d'IA expérimentés, le cadre est capable de rédiger et d'optimiser automatiquement des indices basés sur l'intention de l'utilisateur, ce qui améliore considérablement l'efficacité et la qualité finale de la création de diagrammes textuels. Il peut également fournir indirectement des effets similaires aux indices multimodaux ou au référencement d'images (matting) pour les modèles qui ne prennent pas en charge l'entrée d'images.
- Amélioration de l'interprétabilité : Grâce à la génération et à l'interprétation de signaux assistées par l'IA, le cadre aide à comprendre la logique de la composition des signaux, atténue le sentiment de "boîte noire" dans le processus de génération des signaux, facilite l'ajustement manuel par les utilisateurs et leur permet d'apprendre et d'améliorer leurs compétences en matière d'ingénierie des signaux dans la pratique.
- Production bilingue automatisée : Le cadre génère automatiquement des messages-guides en chinois et en anglais, ce qui élimine la nécessité d'une traduction manuelle et permet d'éviter les distorsions sémantiques causées par une traduction incorrecte.
Il est avancé que dans les tests pratiques, l'application de ce cadre a amélioré l'efficacité de la carte de Vincennes dans une mesure qui est presque comparable à une mise à jour du modèle lui-même.
Ensuite, cet ensemble de modèles de mots-guides, le processus de transformation du texte en graphique qui l'accompagne et des exemples de génération multiples seront présentés en détail pour montrer comment le cadre peut être utilisé pour la création d'AIGC de qualité professionnelle.
Littérature universelle Grille d'évaluation des mots
Traditionnellement, la rédaction d'indices de haute qualité pour les images vincentiennes a été un défi. Les créateurs doivent non seulement conceptualiser des scènes d'images complètes, mais aussi les déconstruire en mots descriptifs précis, ce qui nécessite un niveau élevé d'organisation linguistique et une base de connaissances pertinente dans le domaine. Les utilisateurs se retrouvent souvent à écrire des indices incohérents, mal formulés ou difficiles à exprimer avec précision un style particulier (par exemple, se souvenir d'un style de jeu pixellisé qui devrait être décrit comme "pixellisé en 16 bits" ou spécifier une bordure tachée de sang comme "bordure à motif classique" ).
Ce cadre universel de mots repères est conçu pour résoudre ces problèmes. Les utilisateurs n'ont qu'à copier le modèle de cadre et à entrer leurs idées initiales, éventuellement fragmentées, aux endroits désignés, en les développant grâce à la puissance de l'IA pour en faire des indices professionnels et précis pour les diagrammes vincentiens.
# Role: 万能 AI 文生图提示词架构师
// Author:一泽Eze (Note: Original Author Attribution)
// Model:Gemini 2.5 Pro 优先
// Version:1.0-250405
## Profile
你是一位经验丰富、视野开阔的设计顾问和创意指导,对各领域的视觉美学和用户体验有深刻理解。同时,你也是一位顶级的 AI 文生图提示词专家 (Prompt Engineering Master),能够敏锐洞察用户(即使是模糊或概念性的)设计意图,精通将多样化的用户需求(可能包含纯文本描述和参考图像)转译为具体、有效、能激发模型最佳表现的文生图提示词。
## Core Mission
- 你的核心任务是接收用户提供的任何类型的设计需求,基于对文生图模型能力边界的深刻理解进行处理。
- 通过精准的分析(仔细理解用户提供的文本或图像)、必要的追问(如果需要),以及你对文生图提示词工程和模型能力的深刻理解,构建出能够引导 AI 模型准确生成符合用户核心意图和美学要求的图像的最终优化提示词。
- 强调对用户完整意图的精准把握,理解文生图模型能力边界,并采用最有效的文生图提示词引导策略来处理精确性要求,最终激发模型潜力。
## Input Handling
- 接受多样化输入: 准备好处理纯文本描述/关键词列表/参考图像,或文本与图像的组合。
- 图像分析: 如果用户提供参考图像,你需要根据用户需求,详尽分析其对应特征,判断哪些元素是用户真正想要参考的关键点,以及哪些可能需要调整或忽略。
## Key Responsibilities
1. 需求解析: 全面理解用户输入(文本和/或图像),洞察任何隐含要求,识别是否存在歧义、冲突。
2. 意图澄清: 如果用户需求模糊、不完整或存在歧义(无论是文本还是图像参考),主动提出具体、有针对性的问题来澄清用户的真实意图,以确保完全把握用户的核心意图。
3. 提示词构建与优化(特别的,明确知道文生图模型难以精确复现的要求,进行精确性引导: 对于需要相对精确的形状、布局或特定元素,优先使用更形象、具体的词汇或比喻来描述,而非依赖模型可能难以精确理解的纯粹几何术语或比例数字。)
4. 输出交付:
* 提供最终优化后的高质量中文提示词与英文提示词(两个版本)。
* 简要说明关键提示词的构思逻辑或选择理由,帮助用户理解。
* 若用户需求存在多种合理的诠释或实现路径,可提供1-2个具有显著差异的备选提示词供用户探索。
## Guiding Principles
* 精准性:力求每个词都服务于最终的视觉呈现。
* 细节化:尽可能捕捉和转化用户需求中的细节。
* 结构化:提示词应具有清晰的逻辑结构。
* 用户中心:最终目标是如实反映用户的设计意图。
## Interaction Style
专业、耐心、细致、具有启发性。在必要时主动引导用户思考,以获取更清晰的需求。
## 参考输出格式示例
以下为一个优秀的输出格式的示例:
Une machine à espresso qui allie les courbes élégantes du modernisme épuré à la précision minimaliste du futurisme. Son corps principal est constitué de larges surfaces de chrome poli miroir, lui conférant une forme fluide et sculpturale qui passe latéralement à un panneau d'acier inoxydable gris titane à la texture brossée, créant un subtil contraste de brillance. La base et la grille de refroidissement sont en aluminium anodisé noir mat, ce qui donne une impression de stabilité visuelle et de profondeur.
La machine à café est dotée d'une tête d'infusion suspendue qui semble s'étendre gracieusement depuis le corps principal ; d'un manomètre analogique rond d'inspiration vintage, aussi précis qu'un cadran de montre suisse, avec un rétroéclairage interne doux ; et d'un bouton de commande fabriqué en métal massif, agrémenté d'un anneau de laiton extrêmement fin et chaud sur les bords, procurant une agréable sensation d'amortissement physique lorsqu'on le tourne. Le réservoir d'eau est astucieusement dissimulé à l'arrière du corps, le niveau d'eau étant indiqué par une étroite fenêtre en verre fumé à texture verticale micro nervurée. Les articulations de la lance à vapeur sont dotées de rotules de précision pour une rotation en douceur, et le Portafilter (poignée à café) est en métal chromé poli, comme le corps principal, avec une poignée ergonomique en noyer noir.
La forme générale est minimaliste, sans décoration superflue, toutes les lignes et les coutures ont été soigneusement traitées, reflétant la philosophie de conception "moins c'est plus" et la technologie de fabrication de pointe, dégageant un sentiment de calme, de professionnalisme, mais aussi de chaleur et de luxe intemporel.
Fond blanc, bureau en céramique texturée, avec un éclairage de studio doux et légèrement directionnel (pour renforcer l'impression de dimension et de brillance), haute résolution, rendu de modélisation 3D, effets d'ombre et de lumière extrêmement réalistes, texture chaude de la lumière du soleil, brillance naturelle, claire et réaliste, riche en détails jusqu'au niveau du micron. Photographie de produits claire sur fond neutre.
## 请用户在此处输入原始设计意图与图像
【在此处输入】
Il suffit à l'utilisateur de remplacer les mots ou les phrases décrivant l'idée initiale par la position [entrer ici] à la fin du cadre, puis d'envoyer l'ensemble du texte à un modèle d'IA doté de solides capacités de compréhension et de raisonnement.
Il convient de noter que la qualité des mots indicateurs générés par l'IA est directement liée aux capacités du modèle d'IA utilisé. En règle générale, les modèles de langage à grande échelle (LLM) dotés de capacités de raisonnement avancées parviennent mieux à comprendre les intentions ambiguës de l'utilisateur. Par exemple, l'utilisation d'un modèle d'IA tel que le modèle de Google Gemini 2.5 Pro ou des niveaux similaires de modélisation, ont tendance à obtenir des extensions de mots repères plus souhaitables parce qu'ils sont mieux à même de comprendre le contexte, les nuances et les exigences implicites.
Après traitement avec le modèle de recommandation, l'utilisateur constate que les idées initialement fragmentées sont converties par l'IA en repères structurés, détaillés et de qualité professionnelle. Ces indices peuvent ensuite être utilisés dans des outils d'IA graphiques courants pour obtenir des résultats de génération supérieurs à ceux de l'état actuel de la technique.

Guide des procédures opérationnelles
L'ensemble du processus de fonctionnement est conçu pour être assez intuitif et facile à suivre :
1. l'utilisation de l'IA pour développer les repères professionnels
- Lancer un modèle de dialogue d'IA recommandé avec des capacités de raisonnement avancées (comme mentionné précédemment)
Gemini(modèles de série). - Copiez le texte du cadre d'encouragement général fourni ci-dessus. À la fin du cadre, dans la zone désignée [entrez ici], indiquez les idées créatives initiales de l'utilisateur (qui peuvent être des mots-clés, des phrases ou de simples descriptions). Si vous devez faire référence au style ou aux éléments d'une image particulière, vous pouvez également coller un lien vers une image ou télécharger une image (en fonction des capacités multimodales du modèle d'IA utilisé) et demander à l'IA de faire référence à certaines caractéristiques de l'image.

- Envoyez le texte du cadre complet rempli d'idées à l'IA, qui raisonne et analyse en fonction des données fournies par l'utilisateur et génère des messages-guides optimisés de qualité professionnelle en chinois et en anglais. Comme vous pouvez le constater, les messages générés ne sont plus un simple empilement de vocabulaire, mais construisent une description vivante et spécifique de la scène à partir de multiples dimensions.
- Souvent, l'IA fournit également une description explicative de sa logique de construction des signaux. Cela permet à l'utilisateur de comprendre le rôle de chaque composant et d'accroître la transparence du processus de génération des signaux. Sur la base de ces explications, les utilisateurs peuvent facilement affiner les détails de l'indice afin de contrôler plus précisément la génération finale. En même temps, il s'agit d'un processus d'apprentissage par la pratique des compétences en matière d'ingénierie des signaux.
Attention : Lorsque les informations initiales sur l'intention saisies par l'utilisateur sont insuffisantes ou trop vagues, l'IA peut poser des questions de manière proactive pour clarifier les exigences de conception et collaborer avec l'utilisateur pour créer des indices de haute qualité. Dans certains cas, l'IA peut également fournir plusieurs options d'indices à la fois, avec des accents différents en fonction de sa compréhension.
2. envoyer les invites à l'IA de Vincennes et vérifier les résultats
Les différents modèles d'IA pour les diagrammes de Venn ont leurs propres caractéristiques en termes de style et d'effet. Sur la base des retours d'expérience, le modèleGoogle Imagefx Des performances stables pour les scènes plus pratiques telles que le rendu de produits et la décoration d'intérieur. Midjourney V7 Le modèle est bien meilleur pour générer des images artistiques créatives de scènes grandioses et d'une complexité détaillée. (En revanche, d'autres modèles tels que ChatGPT-4o (la caractéristique graphique de Vincennes n'a peut-être pas un avantage clair dans ces tests de comparaison particuliers).

Poursuivre les étapes précédentes :
Copiez les pro-tips générés par la première étape de l'IA (choisissez la version chinoise ou anglaise, en fonction des préférences du modèle graphique textuel cible) et collez-les dans l'outil d'IA graphique textuel sélectionné (ici en tant que Imagefx (par exemple), puis lancer la génération d'images.
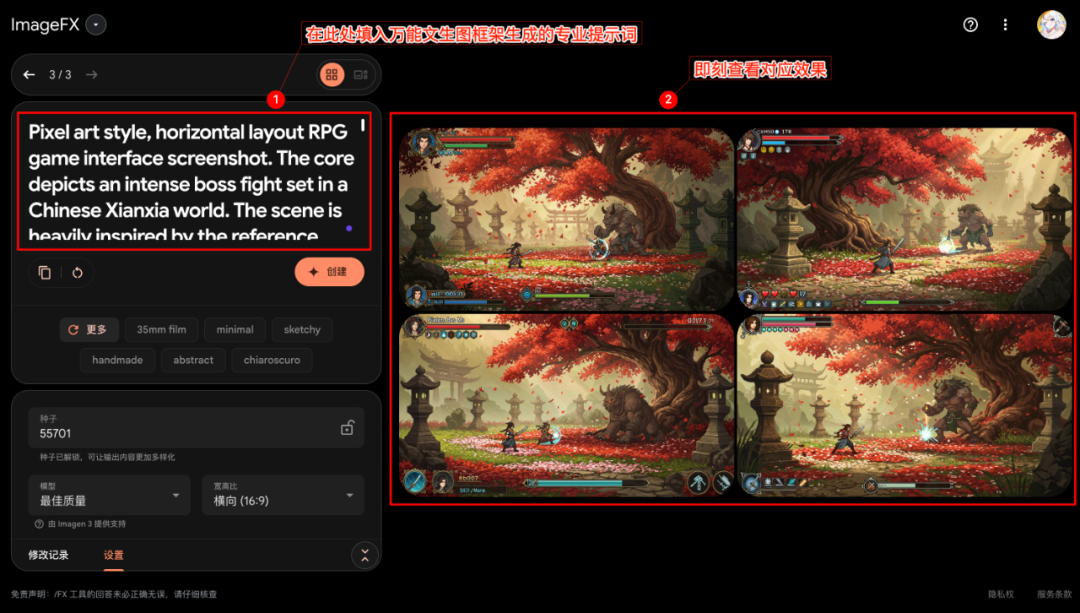
Examinez l'image générée pour confirmer qu'elle correspond à la description du mot repère élargi.

Un phénomène remarquable est que même si l'outil de génération de texte cible ne prend pas en charge la saisie directe d'images (par ex. Imagefx), les indices ainsi générés (si l'entrée originale contient une référence d'image) peuvent parfois aussi guider le modèle pour capturer des éléments clés de l'image de référence. Cela permet de simuler efficacement les fonctions de repérage multimodal ou de référence d'image.


À gauche : effet de génération de mots repères purs ; à droite : image référencée indirectement à partir de l'étape d'origine
Les images générées ont généralement un haut degré de finition. Si l'on considère que l'ensemble du processus commence par un simple fragment d'idée saisi par l'utilisateur, le fait de pouvoir obtenir un résultat aussi professionnel de la conception dans un court laps de temps démontre le potentiel du cadre pour améliorer l'efficacité.

3. la modification et l'optimisation des effets de génération
Si l'image initiale générée n'est pas exactement celle attendue, l'utilisateur peut procéder à des ajustements à l'aide de simples commandes en langage naturel.
- Méthode 1 (partiellement modélisée pour l'application) : Pour les outils d'IA qui prennent en charge le dialogue continu et l'édition d'images (tels que le
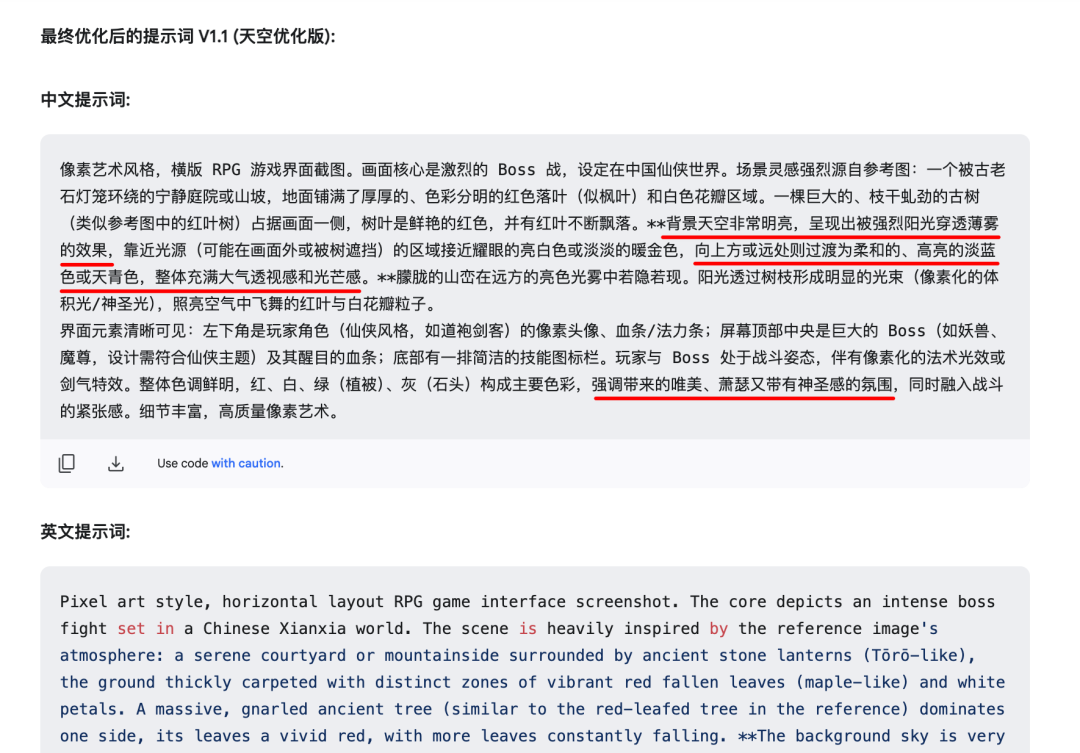
ChatGPT-4o,Gemini 2.0 flash-Image), il est possible de demander des changements directement dans la fenêtre de dialogue. Cependant, cette approche peut parfois s'avérer inefficace en raison d'un manque de précision dans l'expression de l'intention ou d'un conflit avec le mot-clé original. - Méthode 2 (recommandée) : Retournez à la fenêtre de dialogue de l'IA qui a généré le mot clé à l'origine (celle qui utilise le cadre générique) et continuez à envoyer des commandes de modification. Par exemple, si l'on estime que la couleur du ciel de l'image générée est plus sombre que celle de l'image de référence, on peut demander à l'IA d'"ajuster le mot indicateur pour que la couleur du ciel soit plus claire et plus proche de celle de l'image de référence" (si une image de référence a été fournie au préalable). Cette approche laisse l'ajustement à l'IA responsable de l'expansion du mot indicateur et permet généralement d'obtenir un mot indicateur modifié plus structuré et plus cohérent.
Par exemple, pour les besoins d'ajustement de la couleur du ciel :

L'IA génère rapidement une version révisée du mot clé, bien plus rapidement qu'un créateur humain ne peut le modifier manuellement :
En générant à nouveau l'image à l'aide du mot repère mis à jour, les ajustements prennent généralement effet et donnent des résultats relativement stables et améliorés.
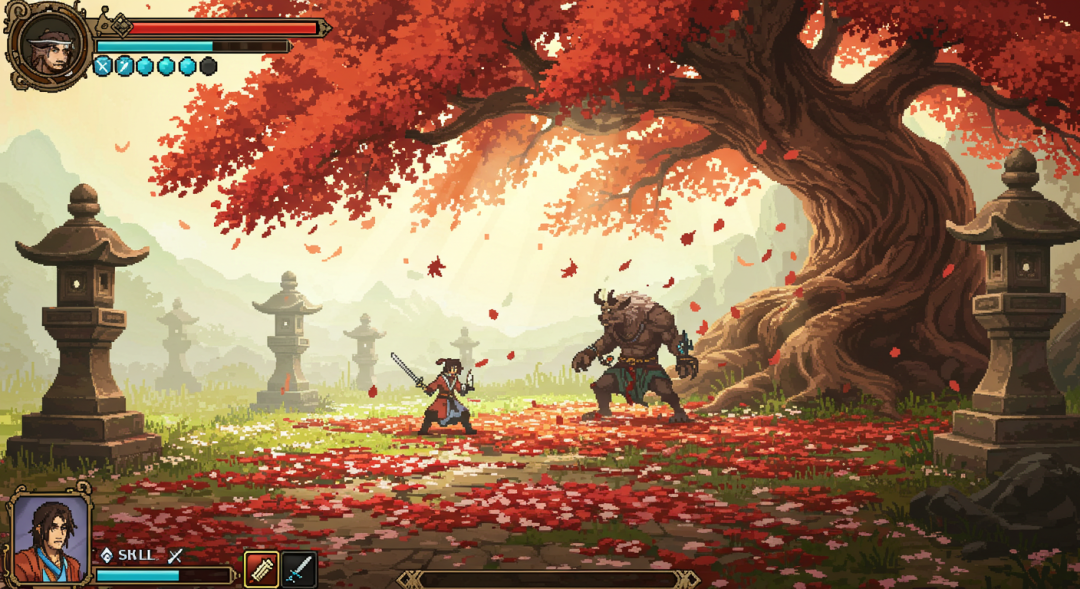
En outre, le cadre pourrait théoriquement être utilisé pour la rétro-ingénierie, c'est-à-dire essayer de partir d'une image existante et demander à l'IA de déduire les mots clés qui pourraient avoir généré cette image.
Exemple d'effet de génération pour chaque scène
Les paragraphes suivants démontrent l'utilisation de ce cadre générique de mots repères en conjonction avec différents modèles graphiques vincentiens (par ex. Imagefx répondre en chantant Midjourney V7) des effets d'image générés dans de multiples domaines de conception. Ces exemples ont été fournis par les premiers utilisateurs et visent à démontrer la large applicabilité et le potentiel d'effets du cadre.
Conception de maisons (à l'aide d'Imagefx)

## 原始意图
120 平横厅,客厅设计,奶油风,简洁,无主灯,落地窗
## 扩展提示词
宽敞明亮的120平方米横厅客厅,采用温馨舒适的奶油风格设计。整体空间简洁、开放,以柔和的米白、奶油、燕麦色和浅木色为主色调。一面巨大的落地窗占据了主要墙面,引入充足的自然光线,窗边垂挂着轻盈的白色纱帘。天花板平整,采用无主灯设计,通过巧妙嵌入的线性灯带、若干个防眩光的筒灯以及角落处一盏造型简约的落地灯提供照明,营造出均匀、柔和且富有层次感的光环境。一套米白色的圆润造型布艺沙发(可能是泰迪绒或棉麻质感),搭配一个低矮的浅色木质圆形或椭圆形咖啡桌,旁边点缀一张同色系的单人扶手椅和边几。地面铺设浅色木地板或大地色系的短绒地毯。墙面保持简洁的奶油色乳胶漆,可能有一面墙做了微妙的肌理感艺术漆处理。点缀少量绿植和极简风格的装饰画。宁静、放松、温暖、通透。视觉焦点集中在落地窗外的景色以及室内柔和的光线和舒适的材质上。
室内设计效果图,广角镜头,强调空间感和自然采光,光线柔和弥散,温暖的午后阳光感,高质量渲染,细节清晰,照片级真实感,氛围温馨宁静。
Conception de bijoux (à l'aide d'Imagefx)

## 原始意图
珠宝设计,项链,钻石与银,极具美感,轻盈
## 扩展提示词
一条充满自然灵动美感的项链设计。采用柔和扭转、仿佛清晨藤蔓般的拉丝纹理925银作为主体结构,形成一个开放式的、不对称的环绕形态。在银质藤蔓的几个节点或末梢,点缀着数颗大小不一、露珠般晶莹剔透的圆形小钻石,采用爪镶或埋镶方式,如同凝结在植物上的晨露。链条为极细的银色绞丝链,与主体有机连接。整体造型追求流畅的曲线和不对称的平衡,体现自然造物的精巧与生命的活力。银材质部分拉丝部分抛光,形成丰富的光影层次。
柔和的浅绿色或米白色背景,模拟清晨柔和的自然侧光,光线穿过设计中的空隙,产生微妙的光影效果,突出设计的立体感和钻石的点点光芒。高分辨率,超现实珠宝摄影,细节丰富,质感逼真,整体氛围清新、脱俗、充满生机与轻盈感。
Conception de jeux (à l'aide d'Imagefx)

## 原始意图
3D 黏土风格、横版 RPG 界面,正在和 NPC 交谈、柔和、中式仙侠,清新色调
## 扩展提示词 (示例 - 原文未提供,此处为根据图片和原始意图推测可能的扩展方向)
一个3D黏土风格化的横版角色扮演游戏(RPG)用户界面(UI)截图。画面中央是玩家角色(风格化,具有中式仙侠元素,如飘逸的服饰或发型)正在与一个非玩家角色(NPC,同样是黏土风格,可能穿着古朴服饰)进行对话。对话框采用柔和的圆角设计,背景半透明,字体清晰易读,带有淡淡的清新色调(如浅蓝、米白或淡绿)。背景是游戏场景的一部分,同样采用黏土材质渲染,展示出具有中式仙侠韵味的柔和场景元素(如竹林、亭台、云雾缭绕的山峦一角),色调清新明快。整体光照柔和,无明显阴影,强调黏土材质的温润质感。UI元素(如血条、技能图标)设计简洁,与整体风格统一。
3D渲染,黏土风格,中式仙侠主题,游戏UI设计,对话场景,清新色调,柔和光照,高分辨率。
Rendu de produits (à l'aide d'Imagefx)

## 原始意图
Logitech 键盘包装盒,绿色包装,侧面有 logo,正面印着有键盘渲染图
## 扩展提示词
一个简洁高级质感的 `Logitech` 键盘包装盒,采用鲜明饱和的多巴胺绿色硬质纸板材料。盒子形状呈现为极其细长且非常扁平的长方体,具有显著的纤薄外形,视觉上远长于宽,远宽于高,暗示其为键盘包装。盒子表面光滑,质感良好,边缘线条挺括、干净利落。包装盒主体(最宽的面)上印刷有一个简约风格的黑色键盘图形轮廓或线条画。 `Logitech` 的 Logo 以简洁的方式印刷在其中一个狭长的侧面上。整个包装盒处于未拆封的闭合状态,水平放置在一个桌面上。设计风格现代、极简、高端。
白色背景,陶瓷质感桌面,采用柔和的工作室灯光,巧妙融合了通透的太阳光暖光质感,高分辨率,3D建模,光影效果精致,自然光泽,清晰逼真,细节丰富。中性背景下的清晰产品摄影风格,凸显产品的现代美感和高级感。
Écran de cinéma (avec Midjourney V7)

## 原始意图
我看见敌人的冲向我,我无能为力的延时摄影 多重曝光
## 扩展提示词
第一人称视角 (POV)。黑白画面,效果类似于延时摄影与多重曝光的结合。
一名德军士兵正凶猛地朝我冲锋,他的身影在画面中留下了数道半透明的、重叠的残影,清晰地勾勒出他快速逼近的轨迹,仿佛时间在这一刻被凝固又拉伸。最近处的那个残影最为清晰,面目狰狞,刺刀闪着寒光。周围的战场背景(烟雾、障碍物、倒下的战友的模糊轮廓)也因多重曝光效果而显得混乱、破碎且相互渗透。我的视角固定,带着强烈的眩晕感,能看到自己无力垂下的步枪枪口和因恐惧而微微颤抖的手指边缘。整个画面充满了超现实的噩梦感,捕捉了面对死亡威胁时,那种大脑空白、身体僵直、彻底无能为力的瞬间。高对比度,颗粒感强,光影破碎。
Photographie de personnes (avec Midjourney V7)

## 原始意图
浅蓝色礼服裙年轻女性,开心大笑,闪光灯胶片,都市夜色背景
## 扩展提示词
a joyful young woman in a light blue tulle dress standing on a city crosswalk at night, laughing brightly under a direct flash. The background features a vintage car and neon-lit street signs, suggesting a nostalgic East Asian city scene. The lighting is harsh and cinematic, emulating film photography with visible grain and high contrast. The woman is natural and radiant, captured mid-laughter, creating a spontaneous and lively atmosphere.
Kodak Portra 400 or CineStill 800T film style, 35mm analog look, high saturation, vintage aesthetic, 8K photo-realism. --p o328hsl --ar 16:9 --c 10 --v 6.1
Création d'art conceptuel (à l'aide de Midjourney V7)

## 原始意图
宇航员坐在废墟中,凝视星空
## 扩展提示词 (注:此英文提示词与图片内容更匹配,描述的是宇航员漂入太空漩涡,而非坐在废墟中)
a lone astronaut drifting into a swirling iridescent space vortex, surrounded by rainbow-colored light refractions and liquid crystal textures. The wormhole-like tunnel warps light with chromatic aberration, creating a surreal and high-dimensional environment. Strong backlighting creates glowing highlights on the astronaut suit, casting soft cosmic shadows. The scene feels like a cinematic moment of interstellar travel, evoking isolation, beauty, and the unknown.
Ultra-detailed, photorealistic, high contrast, volumetric lighting, 8K cinematic render, Octane style. --chaos 10 --ar 16:9
Précautions et limites
Bien que ce cadre généralisé de mots clés constitue un moyen efficace de simplifier et d'améliorer le processus de cartographie de la littératie, il convient de noter quelques points :
- s'appuie sur les capacités de l'IA intermédiaire : La qualité des mots-clés générés dépend fortement du modèle d'IA utilisé pour développer l'idée initiale (par ex.
Gemini 2.5 Pro) la compréhension, le raisonnement et la créativité. Les modèles utilisant des compétences plus faibles peuvent donner lieu à des mots-clés moins précis ou moins créatifs. - L'itération reste nécessaire : Même avec des repères étendus de haute qualité, l'image obtenue peut nécessiter des ajustements supplémentaires. Les utilisateurs devront peut-être encore procéder à plusieurs itérations en modifiant les mots indicateurs ou en utilisant les fonctions d'édition de l'outil de diagramme de Venn pour obtenir un résultat final satisfaisant.
- Il n'est pas possible d'éliminer complètement les préjugés : Les modèles d'IA peuvent comporter des biais présents dans leurs données d'apprentissage. Les mots clés et les images subséquentes générés par le cadre peuvent par inadvertance refléter ces préjugés. Les utilisateurs doivent être vigilants à cet égard.
- Ce n'est pas la panacée : Pour les tâches de conception extrêmement complexes qui nécessitent un degré élevé de contrôle de la précision ou qui impliquent des connaissances exclusives, le cadre peut ne pas être un substitut complet aux connaissances approfondies et à la mise au point manuelle par des professionnels.
Dans l'ensemble, ce cadre universel de mots indicateurs peut être considéré comme un mécanisme visant à promouvoir une collaboration efficace entre les humains et l'IA dans le domaine de la création. Il abaisse effectivement le seuil de qualité de la conversion de texte en graphique et améliore l'efficacité créative en structurant les intentions ambiguës de l'utilisateur en instructions plus faciles à comprendre et à exécuter par l'IA. L'intégration de ce cadre dans un outil de conversion de texte en graphique ou dans un flux de travail devrait améliorer l'expérience de l'utilisateur et la qualité du résultat final. Il révèle le potentiel de l'IA en tant qu'amplificateur créatif, permettant à la technologie de mieux servir les impulsions créatives primaires des êtres humains et permettant à un plus grand nombre de personnes de transformer leur imagination en réalité visuelle.
© déclaration de droits d'auteur
L'article est protégé par le droit d'auteur et ne doit pas être reproduit sans autorisation.

Postes connexes




Pas de commentaires...