
Step-Audio-AQAA是什么
Step-Audio-AQAA 是 StepFun 团队推出的端到端大型音频语言模型,用于音频查询-音频回答(AQAA)任务。能直接处理音频输入生成自然、准确的语音回答,无需依赖传统的自动语音识别(ASR)和文本到语音(TTS)模块,简化了系统架构并消除了级联错误。Step-Audio-AQAA 的训练过程包括多模态预训练、监督微调(SFT)、直接偏好优化(DPO)以及模型合并。通过这些方法,模型在语音情感控制、角色扮演、逻辑推理等复杂任务中表现出色。在 StepEval-Audio-360 基准测试中,Step-Audio-AQAA 在多个关键维度上超越了现有的 LALM 模型,展现了在端到端语音交互中的强大潜力。
Step-Audio-AQAA的主要功能
- 直接处理音频输入:能直接从原始音频输入生成语音回答,无需依赖传统的自动语音识别(ASR)和文本到语音(TTS)模块。
- 无缝语音交互:支持从语音到语音的交互,用户可以用语音提问,模型直接以语音回答,提升交互的自然性和流畅性。
- 情感语调调整:支持在句子级别调整语音的情感语调,例如表达高兴、悲伤或严肃等情绪。
- スピーチコントロール:用户可以根据需要调整语音回答的速度,使其更符合场景需求。
- 音色和音调控制:能根据用户指令调整语音的音色和音调,适应不同的角色或场景。
- 多语言交互:支持中文、英语、日语等多种语言,满足不同用户的语言需求。
- 方言支持:涵盖中文的四川话、粤语等方言,提升模型在特定地区的适用性。
- 语音情感控制:能根据上下文和用户指令,生成带有特定情感的语音回答。
- ロールプレイング:支持在对话中扮演特定角色,例如客服、教师、朋友等,生成符合角色特征的语音回答。
- 逻辑推理和知识问答:能处理复杂的逻辑推理任务和知识问答,生成准确的语音回答。
- 高品質の音声出力:通过神经声码器生成高保真、自然流畅的语音波形,提升用户体验。
- 语音连贯性:在长句或段落生成中保持语音的连贯性和一致性,避免语音断续或突变。
- 文本与语音交错输出:支持文本和语音的交错输出,用户可以根据需要选择语音或文本回答。
- 多模态输入理解:能理解包含语音和文本的混合输入,生成相应的语音回答。
Step-Audio-AQAA的项目地址
- HuggingFaceモデルライブラリ:https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- arXivテクニカルペーパー:https://arxiv.org/pdf/2506.08967
Step-Audio-AQAA的技术原理
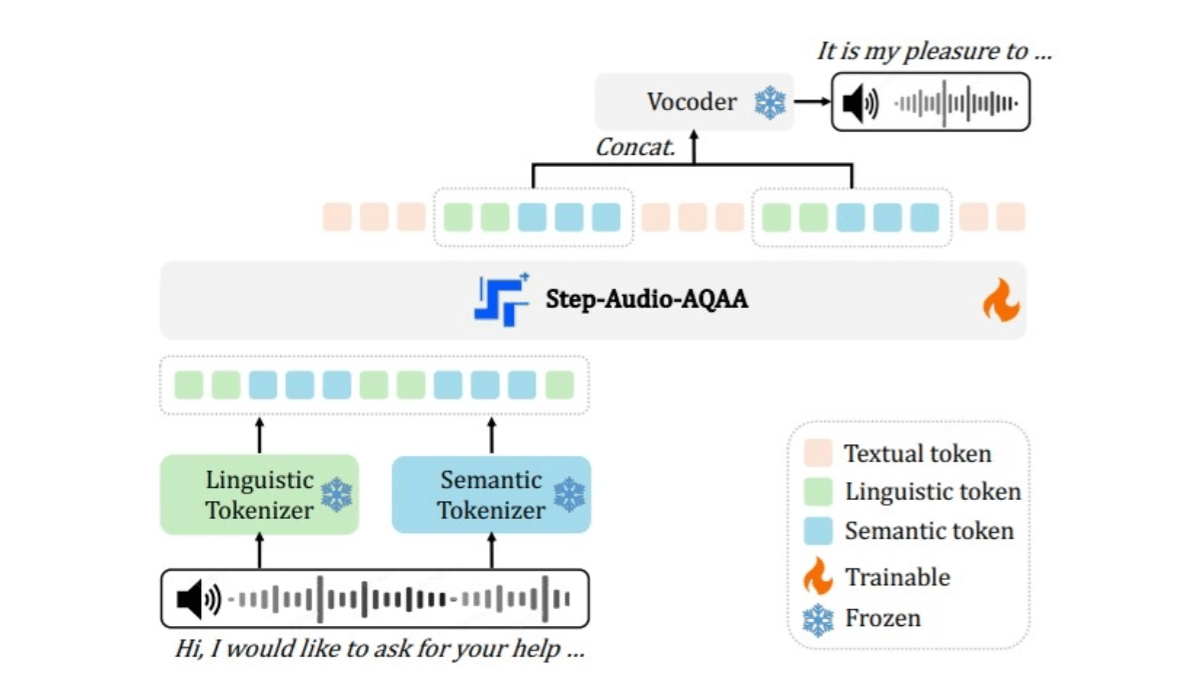
- 双码本音频分词器:将输入音频信号转换为结构化的标记序列。包含两个分词器:语言分词器提取语音的音素和语言属性,以 16.7 Hz 的频率采样,码本大小为 1024;语义分词器捕捉语音的声学特征,如情感和语调,以 25 Hz 的频率采样,码本大小为 4096。能更好地捕捉语音中的复杂信息。
- 骨干 LLM:使用预训练的 1300 亿参数多模态 LLM(Step-Omni),预训练数据涵盖文本、语音和图像三种模态。将双码本音频标记嵌入到统一的向量空间中,通过多个 変圧器 块进行深度语义理解和特征提取。
- 神经声码器:将生成的音频标记合成为自然、高质量的语音波形。采用 U-Net 架构,结合 ResNet-1D 层和 Transformer 块,能高效地将离散的音频标记转换为连续的语音波形。
Step-Audio-AQAA的核心优势
- 端到端音频交互:Step-Audio-AQAA 能直接从原始音频输入生成自然流畅的语音回答,无需依赖传统的自动语音识别(ASR)和文本到语音(TTS)模块。端到端的设计避免了传统方案中因自动语音识别或文本转语音环节出错导致的结果失真。
- 多言語サポート:模型支持多种语言,包括中文(含四川话、粤语)、英语、日语等,能满足不同用户的语言需求。
- 精细的语音特征控制:Step-Audio-AQAA 能进行精细的语音特征控制,例如情感语调、语速等,生成更符合需求的语音回答。在语音情感控制方面表现尤为出色。
Step-Audio-AQAA的适用人群
- 智能语音助手用户:希望使用语音交互设备(如智能音箱、智能助手)进行日常操作(如查询信息、设置提醒、播放音乐等)的用户。
- 游戏爱好者:喜欢与游戏中的 NPC 进行语音交互,获得更沉浸式游戏体验的玩家。
- 教育用户:学生和家长,希望通过语音交互进行学习(如语言学习、知识问答等)。
- 老年人和儿童:对于不擅长使用文字输入的用户,语音交互更加便捷和自然。
- 有声读物创作者:需要生成高质量语音内容的创作者,如有声读物、广播剧等。
- 视频制作者:制作视频内容(如短视频、直播)时,需要语音交互或语音生成功能的创作者。
© 著作権表示
この記事は著作権で保護されており、許可なく複製することは禁じられている。

関連記事



コメントはありません