Genesis: 実物理ベースの4Dダイナミックワールドシミュレーションのためのオープンソース生成物理エンジン综合介绍 Genesis 是一个为通用机器人和具身 AI 学习设计的生成性物理世界。它提供了一个统一的仿真平台,支持多种材料和物理现象的模拟。Genesis 旨在通过结合生成性 AI 和物理仿真,解锁...最新のAIツール# AI Java オープンソースプロジェクト# AIテキストとイメージを3Dへ6ヶ月前01.5K
Kolors: 高品質画像生成のためのテキスト画像変換モデル、中国語ポスター生成もサポート包括的な紹介 Kolorsは、Racerチームによって開発された、ポテンシャル拡散技術に基づく大規模なテキスト画像生成モデルです。このモデルは、数十億のテキスト-画像データのペアで学習され、中国語と英語の両方の入力をサポートし、高品質で複雑な意味的に正確な画像を生成することができます。最新のAIツール# AI Java オープンソースプロジェクト# AI自己展開イメージ生成ツール6ヶ月前01.1K
ColorFlow:カートゥーンシェーディング、白黒画像の自動シェーディングによる画像の色の一貫性と品質の向上综合介绍 ColorFlow是由腾讯ARC团队开发的图像序列自动着色工具,旨在解决黑白图像序列的自动着色问题。该工具利用检索增强的着色管道,通过参考图像池准确生成各种元素的颜色,包括角色的头发颜色和服...最新のAIツール# AIイメージスタイルコントロール# AI Java オープンソースプロジェクト6ヶ月前01.2K
BrushEdit:画像修復・編集のオールインワンツール、テンセントアークがリリース综合介绍 BrushEdit 是由腾讯ARC实验室开发的一款全能图像修复和编辑工具。该工具基于最新的AI技术,能够自动识别和修复图像中的缺陷,同时支持用户进行交互式编辑。BrushEdit 结合了多种...最新のAIツール# AIイメージエディター# AI Java オープンソースプロジェクト6ヶ月前01K
アウトライン: 正規表現、JSON、Pydanticモデルによる構造化テキスト出力の生成综合介绍 Outlines 是一个由 dottxt-ai 开发的开源库,旨在通过结构化文本生成来提升大语言模型(LLM)的应用能力。该库支持多种模型集成,包括 OpenAI、transformers...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング4ヶ月前01.2K
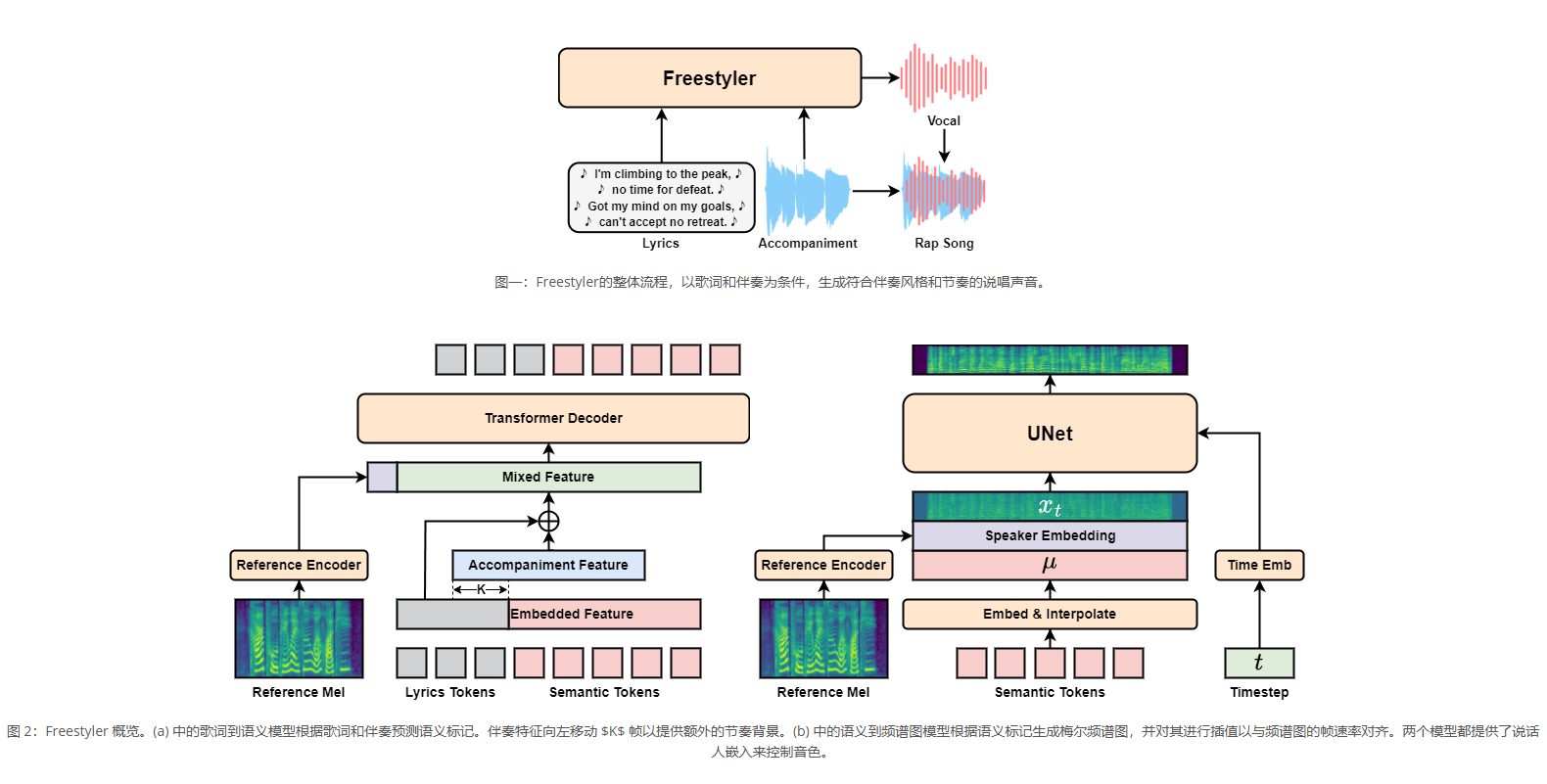
RapBank: 歌詞とバッキングトラックからラップ(Rap)ボーカルを直接生成するモデル(現在オープンデータセット)综合介绍 RapBank 是一个专为说唱歌词生成而设计的数据集和工具集。该项目由 NZqian 创建,旨在通过收集和处理来自 YouTube 的说唱歌曲,为研究人员和开发者提供一个高质量的说唱歌词数据...最新のAIツール# AI Java オープンソースプロジェクト# AIミュージック6ヶ月前01.1K
R2R: マルチモーダルコンテンツを解析し、知識グラフとハイブリッド検索を組み合わせた高度AI検索(RAG)システム综合介绍 R2R(RAG to Riches)是一个先进的AI检索系统,支持检索增强生成(RAG)功能,具备生产就绪的特性。该系统基于容器化的RESTful API构建,提供多模态内容解析、混合搜索功...最新のAIツール# AI Java オープンソースプロジェクト# 知識検索とRAGフレームワーク6ヶ月前01.1K
Megrez-3B-Omni:テキスト、画像、音声のマルチモーダル理解と解析をサポートするエンドサイド・マルチモーダル理解モデル综合介绍 Infini-Megrez是由无问芯穹(Infinigence AI)开发的边缘智能解决方案,旨在通过软硬件协同设计,实现高效的多模态理解和分析。该项目的核心是Megrez-3B模型,支持图...最新のAIツール# AI Java オープンソースプロジェクト# マルチモーダルなリアルタイム・インタラクティブ製品5ヶ月前01K
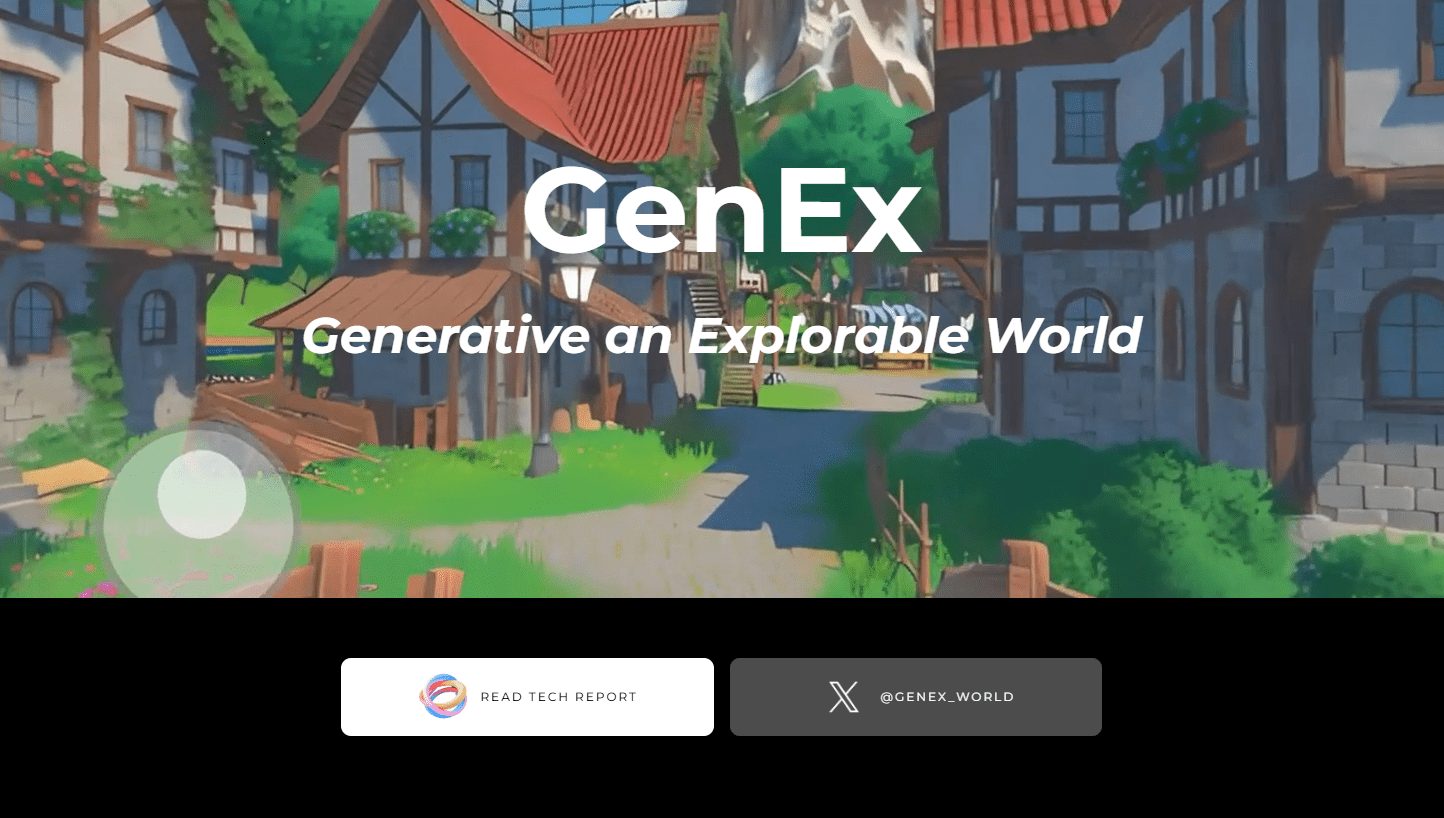
GenEx:1枚の画像から探索可能な360°3D世界を生成(コードは順次オープンソース化)一般的な紹介 GenExは、1枚の画像から完全に探索可能な360°の3D世界を生成できる先進的なAIモデルである。ユーザーはこの生成された世界をインタラクティブに探索することができる。GenExは想像空間における造形的AIの境界を押し広げ、...最新のAIツール# AI Java オープンソースプロジェクト# AIテキストとイメージを3Dへ6ヶ月前01.1K
RAGFlow: 深い文書理解に基づくオープンソースのRAGエンジンで、効率的な検索強化生成ワークフローを提供します。包括的な紹介 RAGFlowは、深い文書理解技術に基づいたオープンソースのRAG(Retrieval Augmented Generation)エンジンです。RAGFlowは、あらゆる規模の企業向けに効率的なRAGワークフローを提供し、実際の文書に基づいた複雑な形式のデータを提供できる大規模言語モデル(LLM)を組み込んでいます。最新のAIツール# AI Java オープンソースプロジェクト# ローコードワークフロー# 知識検索とRAGフレームワーク5ヶ月前01.6K
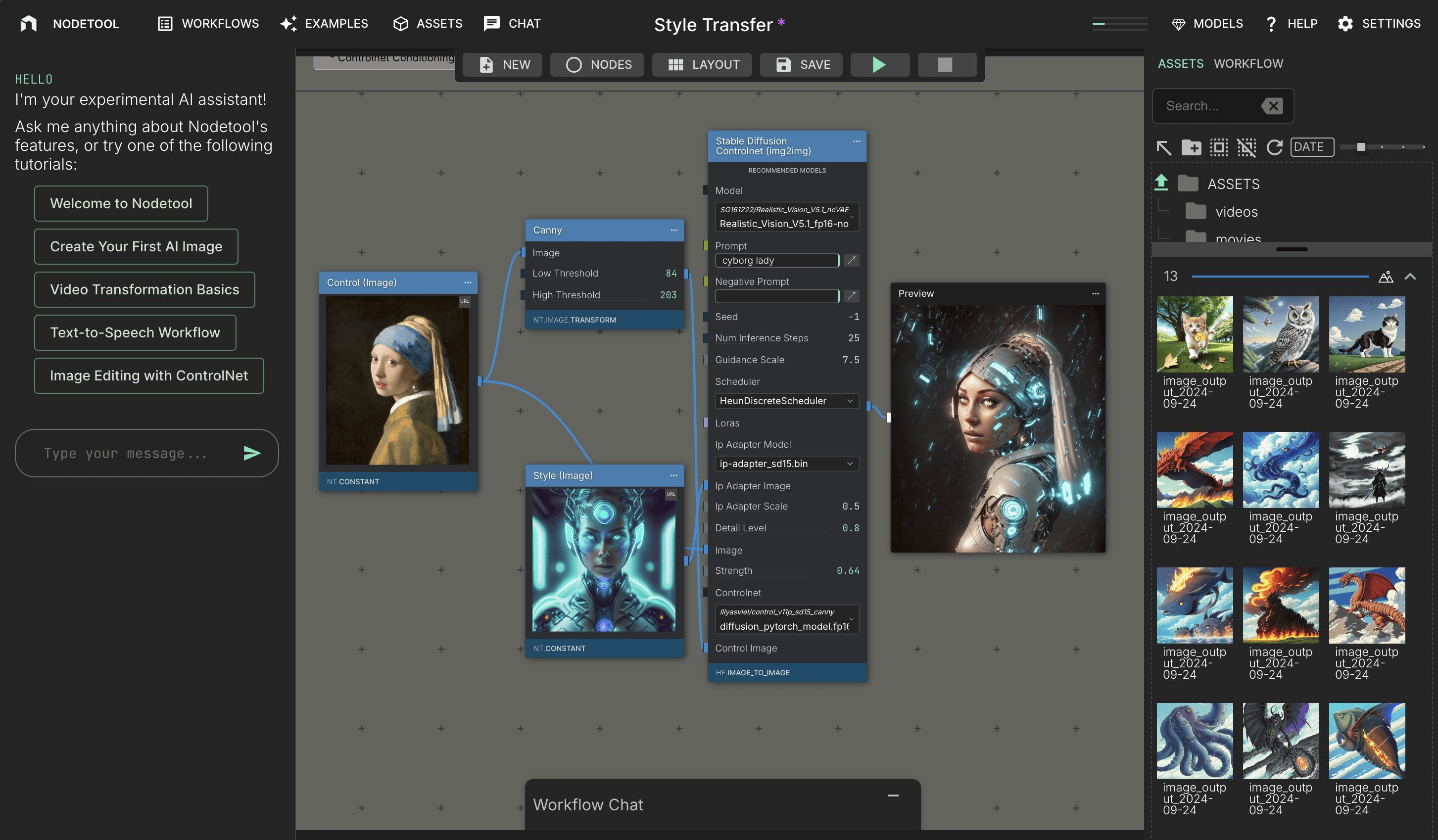
NodeTool: ノードオーケストレーションに基づくAIモデルのワークフロー可視化クライアント综合介绍 NodeTool 是一个创新的AI创作平台,旨在为AI爱好者、开发者、数据科学家和创意人士提供一个简单、直观的界面。无论您是艺术家、开发者还是初学者,NodeTool 都能帮助您快速原型化创...最新のAIツール# AI Java オープンソースプロジェクト# ローコードワークフロー6ヶ月前01K
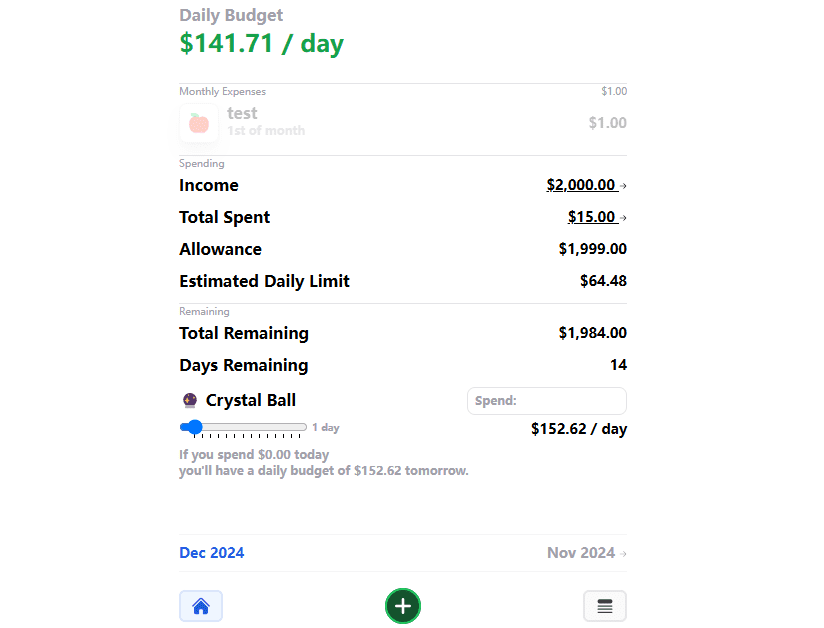
Porkybank:AIを活用した日々の予算管理が簡単にできる综合介绍 Porkybank 是一个开源的个人财务管理应用,旨在帮助用户轻松追踪每日预算。通过简单的公式(收入 - 支出)/ 天数 = 现金,用户可以直观地了解自己的财务状况。该项目托管在 GitHu...最新のAIツール# AI Java オープンソースプロジェクト# AI生活効率化アシスタント5ヶ月前01K
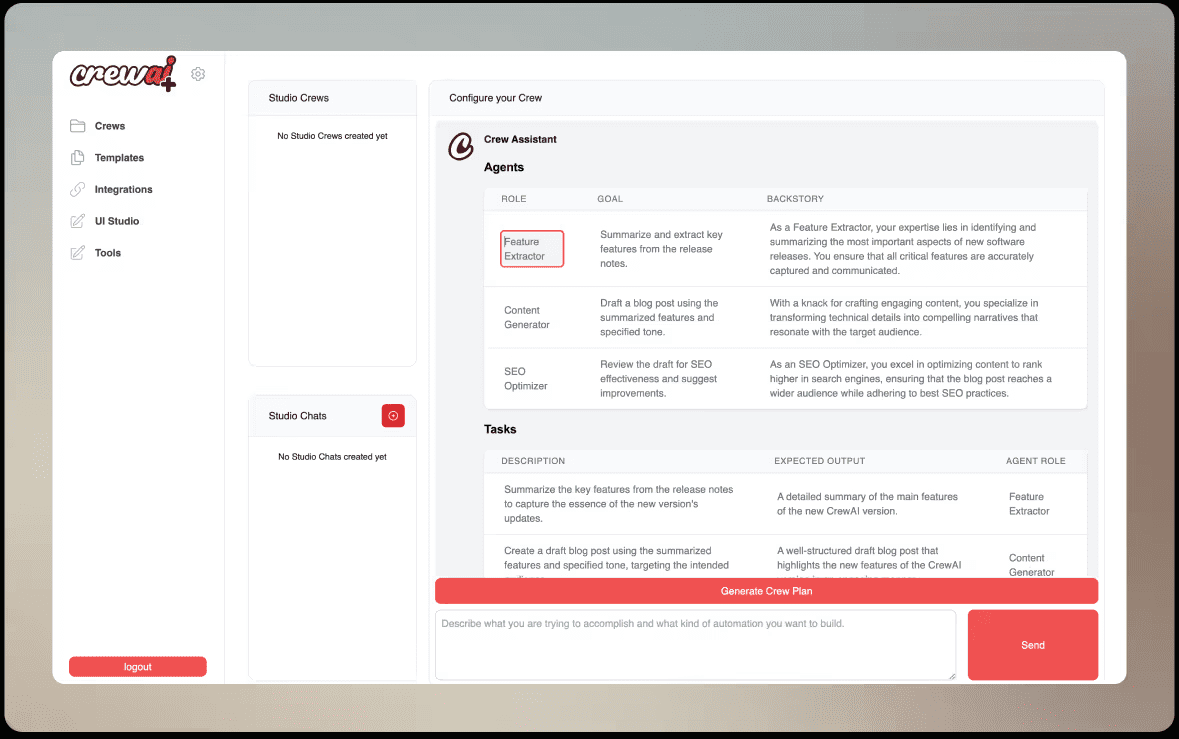
CrewAI:複雑なタスクを簡素化するマルチロールプレイ協調知能フレームワーク综合介绍 CrewAI 是一个先进的框架,旨在协调角色扮演和自主AI代理的协作。通过促进协作智能,CrewAI 使代理能够无缝协作,解决复杂任务。无论是构建智能助手平台、自动化客户服务团队,还是多代理...最新のAIツール# AI Java オープンソースプロジェクト# インテリジェントボディ開発フレームワーク6ヶ月前01.3K
Artab:ブラウザで開いた新しいタブで世界の名画を表示、Chromeプラグイン综合介绍 Artab 是一个浏览器扩展程序,旨在每次打开新标签页时展示世界上最伟大的艺术作品。该扩展程序适用于 Chrome、Edge 和 Firefox 浏览器。通过 Artab,用户可以在日常浏览...最新のAIツール# AI Java オープンソースプロジェクト6ヶ月前01.1K
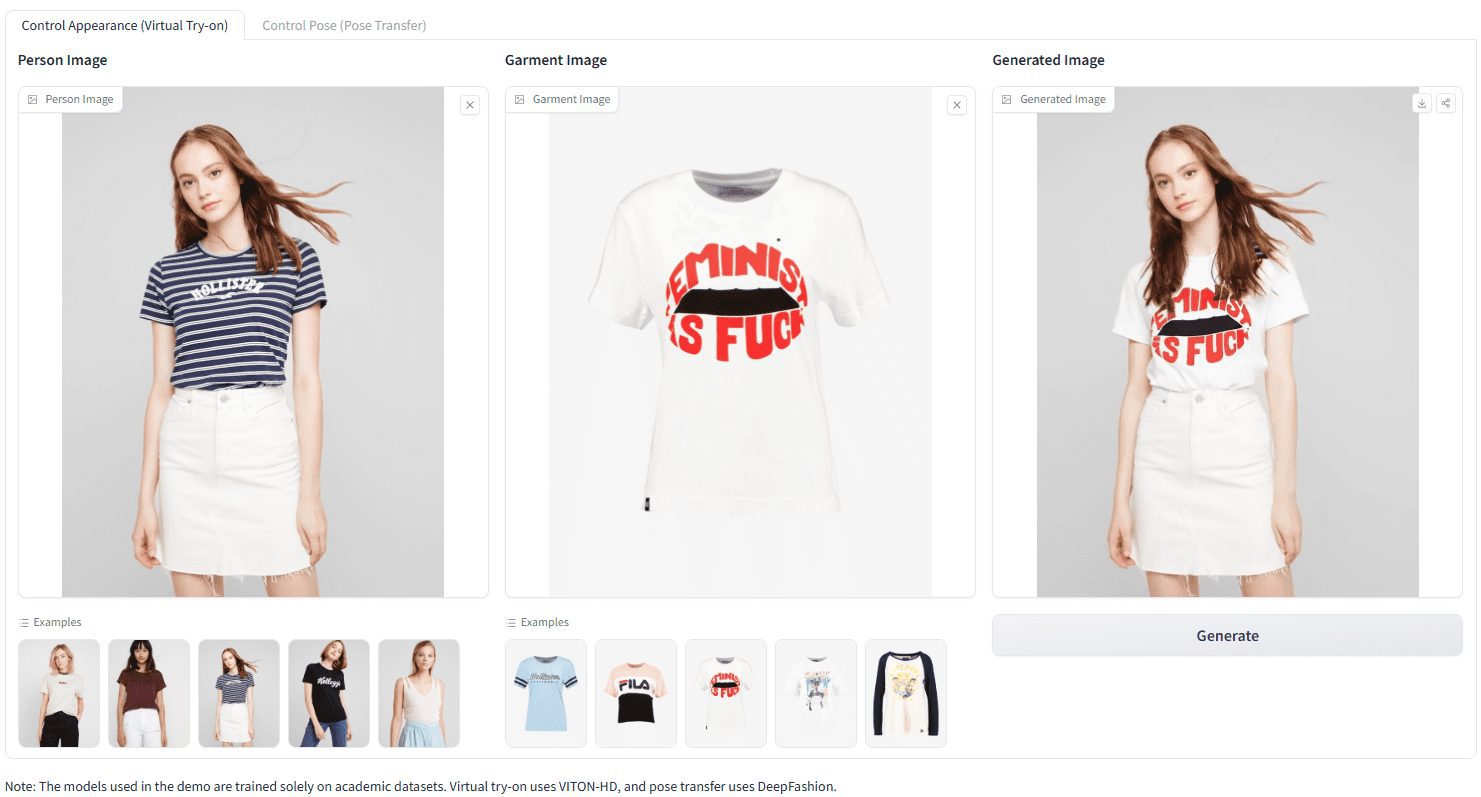
Leffa:高忠実度モデルのバーチャル試着とキャラクターポーズ調整、メタ・オープンソース制御キャラクター画像生成モデル包括的な紹介 Leffaは、制御可能なキャラクター画像を生成するための統一されたフレームワークであり、キャラクターの外見(バーチャルフィッティングなど)やポーズ(ポーズ転送など)の精密な操作を可能にする。このフレームワークは、ターゲットクエリをアテンション層の正しい参照キーにフォーカスさせることで、細かいディテールの歪みを大幅に低減する。最新のAIツール# AIイメージスタイルコントロール# AI Java オープンソースプロジェクト# AI フェイススワップとドレスアップ6ヶ月前01.5K
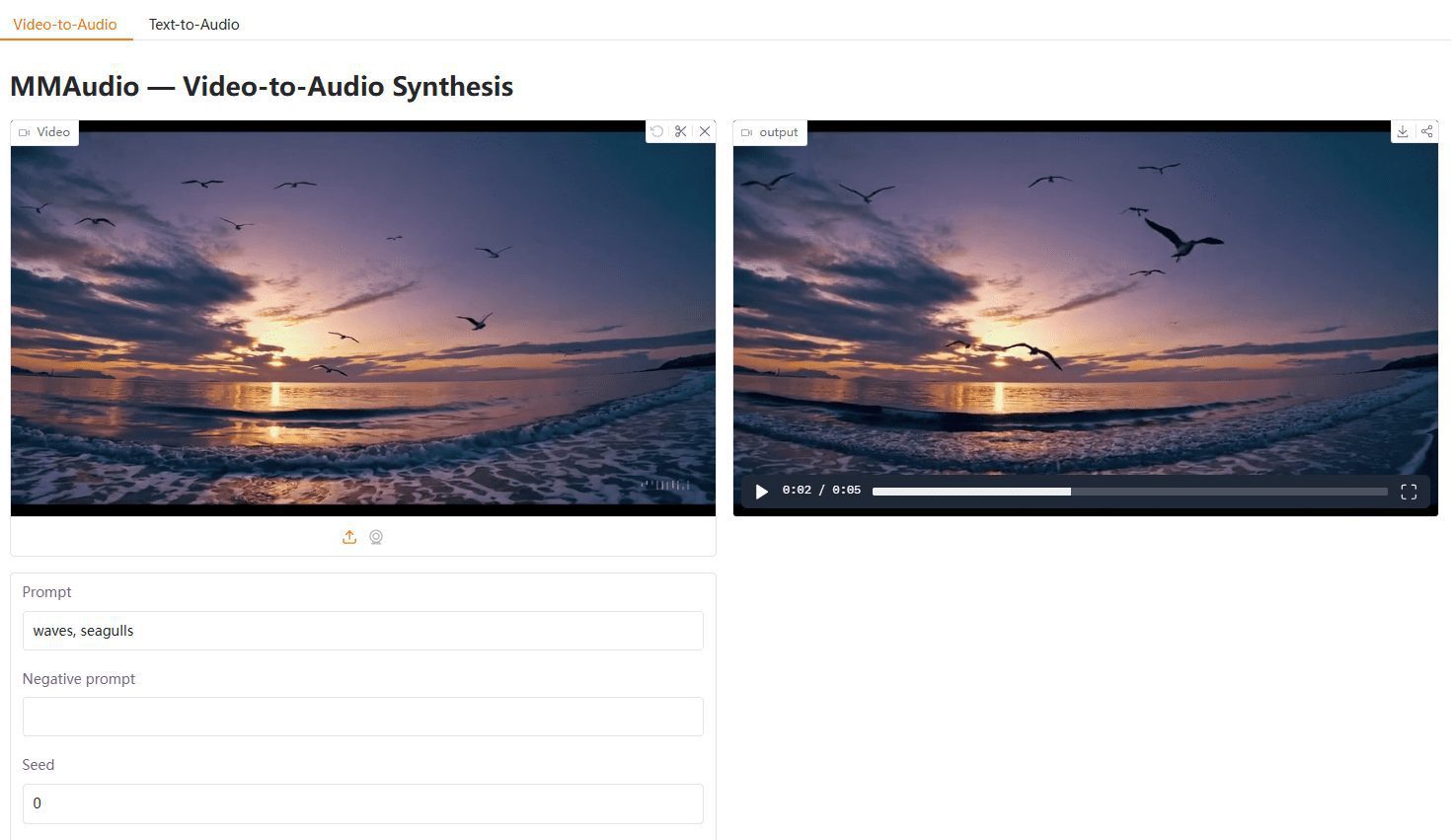
MMAudio:ビデオ映像に同期した効果音やサウンドトラックを生成する、ビデオと音声のマルチモーダル共同トレーニングツール综合介绍 MMAudio是一个开源项目,旨在通过多模态联合训练生成高质量的同步音频。该项目由香港中文大学的程浩基(Ho Kei Cheng)等人开发,主要功能是根据视频和/或文本输入生成同步音频。MM...最新のAIツール# AI Java オープンソースプロジェクト# AIミュージック6ヶ月前01.5K
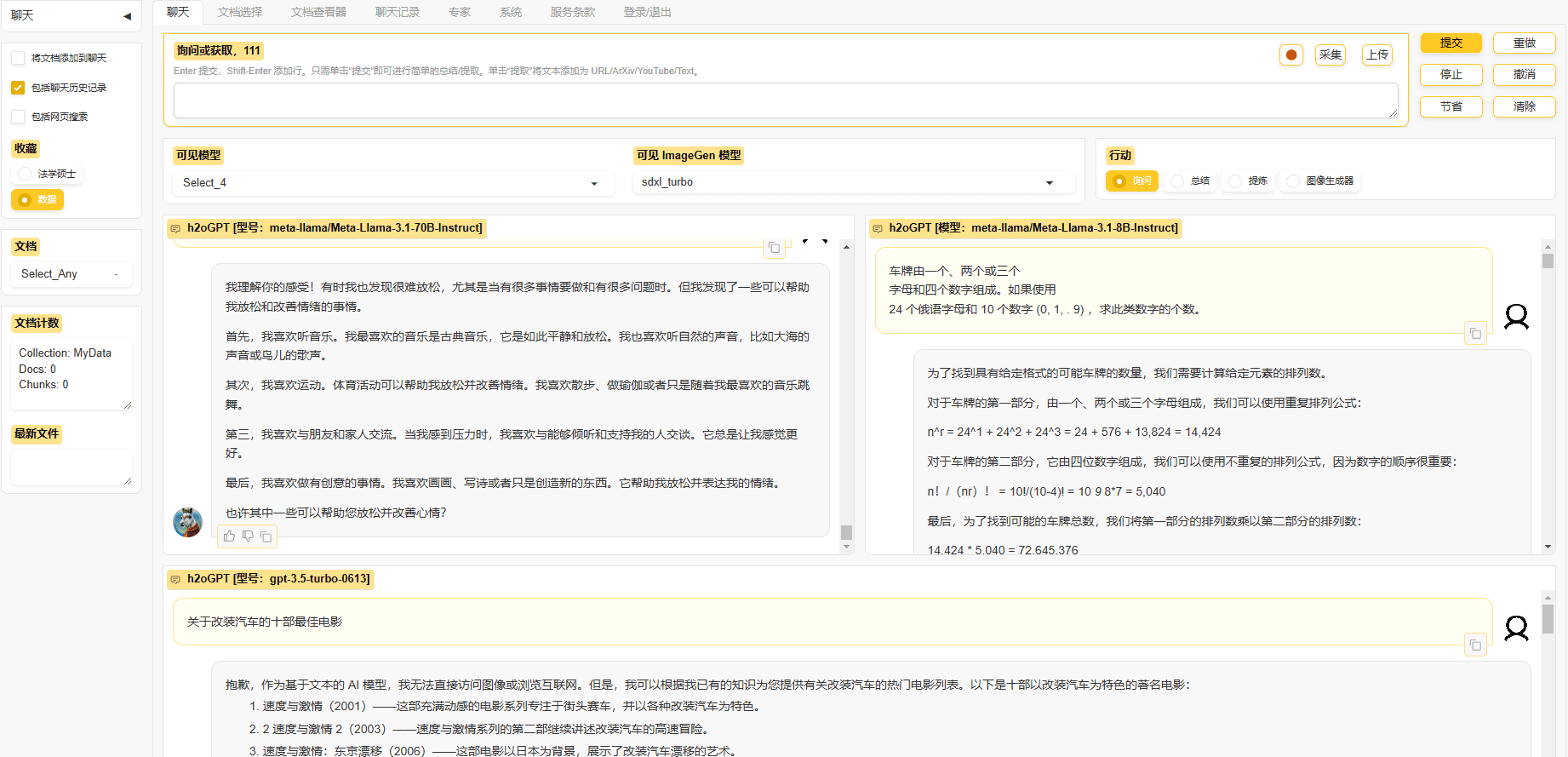
H2O GPT: ネイティブAI対話および文書処理ツールの柔軟な構成综合介绍 H2O GPT 是一个开源项目,旨在提供私有化的聊天和文档处理功能。该项目基于 Apache 2.0 许可证,支持多种 GPT 模型,包括 LLaMa2、Mistral、Falcon 等。用...最新のAIツール# AI Java オープンソースプロジェクト# AIローカライズチャットアプリケーション6ヶ月前01.1K
OpenChat: 複数のデータソースを迅速に統合するカスタムチャットボット概要 OpenChatは、大規模言語モデル(LLM)の使用を簡素化するために設計されたユーザーフレンドリーなチャットボットコンソールです。OpenChatは、2ステップのセットアッププロセスを提供することで、ユーザーが簡単に複数のカスタムチャットボットを作成し、管理することを可能にします。このプラットフォームはG...最新のAIツール# AI接客ロボット# AI Java オープンソースプロジェクト5ヶ月前01.1K
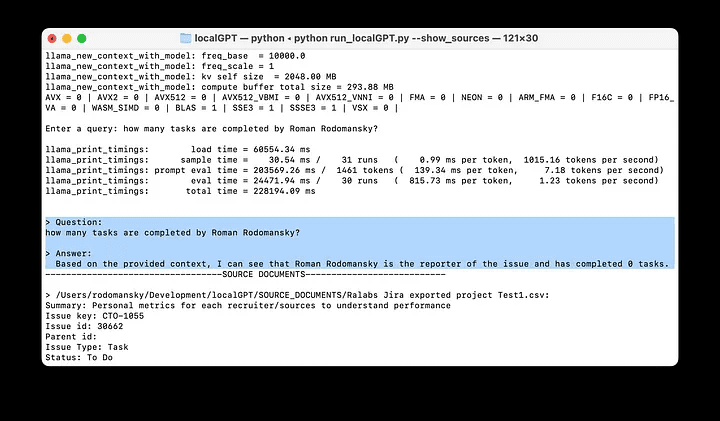
LocalGPT:ローカルデバイス上の複数のドキュメントと対話することで、データプライバシーを確保する一般的な紹介 LocalGPTはオープンソースプロジェクトで、ユーザーがローカルデバイス上のドキュメントと会話できるように設計されており、データのプライバシーを保証します。様々なオープンソースモデルを使用することで、LocalGPTはデータをクラウドにアップロードすることなく、ドキュメントコンテンツを処理し理解することができます。このプロジェクトは、様々なアプリケーションをサポートしています。最新のAIツール# AI Java オープンソースプロジェクト# 知識検索とRAGフレームワーク6ヶ月前01.1K