VOP: 複雑な図や数式を抽出するOCRツール综合介绍 Versatile OCR Program 是一个开源的光学字符识别(OCR)工具,专门为处理复杂的学术和教育文档设计。它能从PDF、图像等文件中提取文本、表格、数学公式、图表和示意图,并生...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング3ヶ月前0563
PDFコンテンツを自動的に解析し、オープンソースサービスのテキストとテーブルを抽出します。综合介绍 它能自动分析PDF文档的布局,识别页面中的文字、标题、图片、表格、公式等元素,并判断它们的正确顺序。工具支持OCR功能,可以把扫描PDF转为可搜索文本。它基于Docker运行,提供两种模型...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング3ヶ月前0615
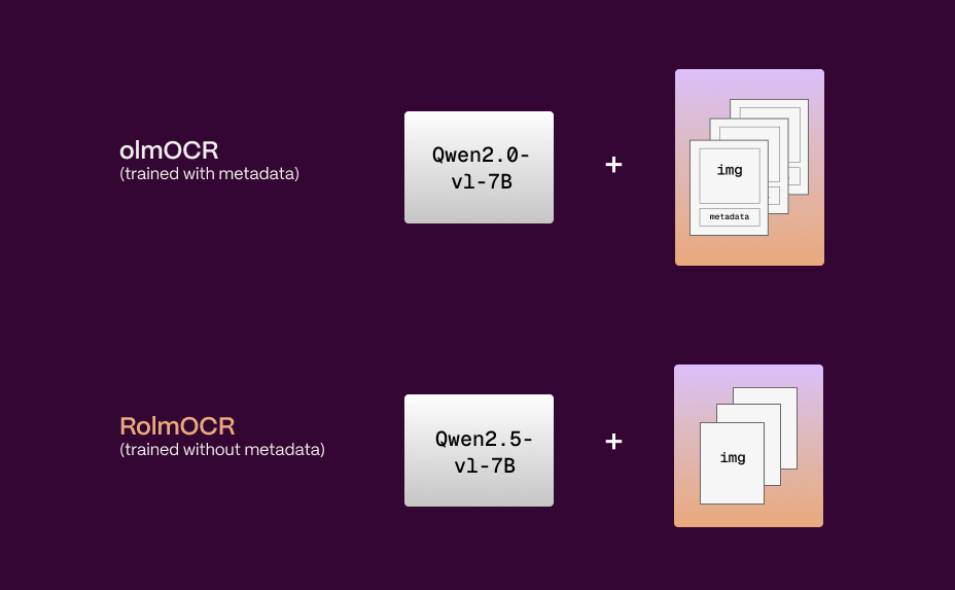
RolmOCR: 手書き文字と斜め文字を認識する文書OCRモデル综合介绍 RolmOCR 是由 Reducto AI 团队开发的一款开源光学字符识别(OCR)工具,基于 Qwen2.5-VL-7B 视觉语言模型。它能从图片和 PDF 文件中提取文字,速度比同类工具...最新のAIツール# AI Java オープンソースプロジェクト# OCR3ヶ月前0655
uniOCR: クロスプラットフォームのオープンソーステキスト認識ツール概論 uniOCRはmediar-aiチームによって開発されたオープンソースのテキスト認識ツールです。Rust言語に基づいており、macOS、Windows、Linuxシステムをサポートしています。画像からテキストを抽出することができます。最新のAIツール# AI Java オープンソースプロジェクト# OCR3ヶ月前0562
PDF Craft: PDFスキャン文書からMarkdownへのオープンソースツール综合介绍 PDF Craft 是一个开源工具,专为扫描书籍的PDF设计,能将其转换为Markdown格式。它由 oomol-lab 开发,托管在 GitHub 上,适合喜欢整理电子书的用户。工具通过本...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング4ヶ月前0871
SmolDocling:少量で効率的な文書処理のための視覚言語モデル综合介绍 SmolDocling 是由 ds4sd 团队与 IBM 合作开发的一个视觉语言模型(VLM),基于 SmolVLM-256M 打造,托管在 Hugging Face 平台。它体积小,只有 ...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング4ヶ月前0839
ミストラルOCR:94.89%総合精度、1000ページ/30秒、わずか1ドル在人类文明的历史长河中,每一次信息获取和解析方式的飞跃,都深刻地推动着社会进步。从远古的象形文字,到便携的纸莎草,再到后来出现的印刷术以及当今的数字化浪潮,每一次技术革新都极大地拓展了人类知识的传播范...最新のAIツール# AIオープンサービス# OCR# ドキュメントの抽出とクリーニング4ヶ月前0766
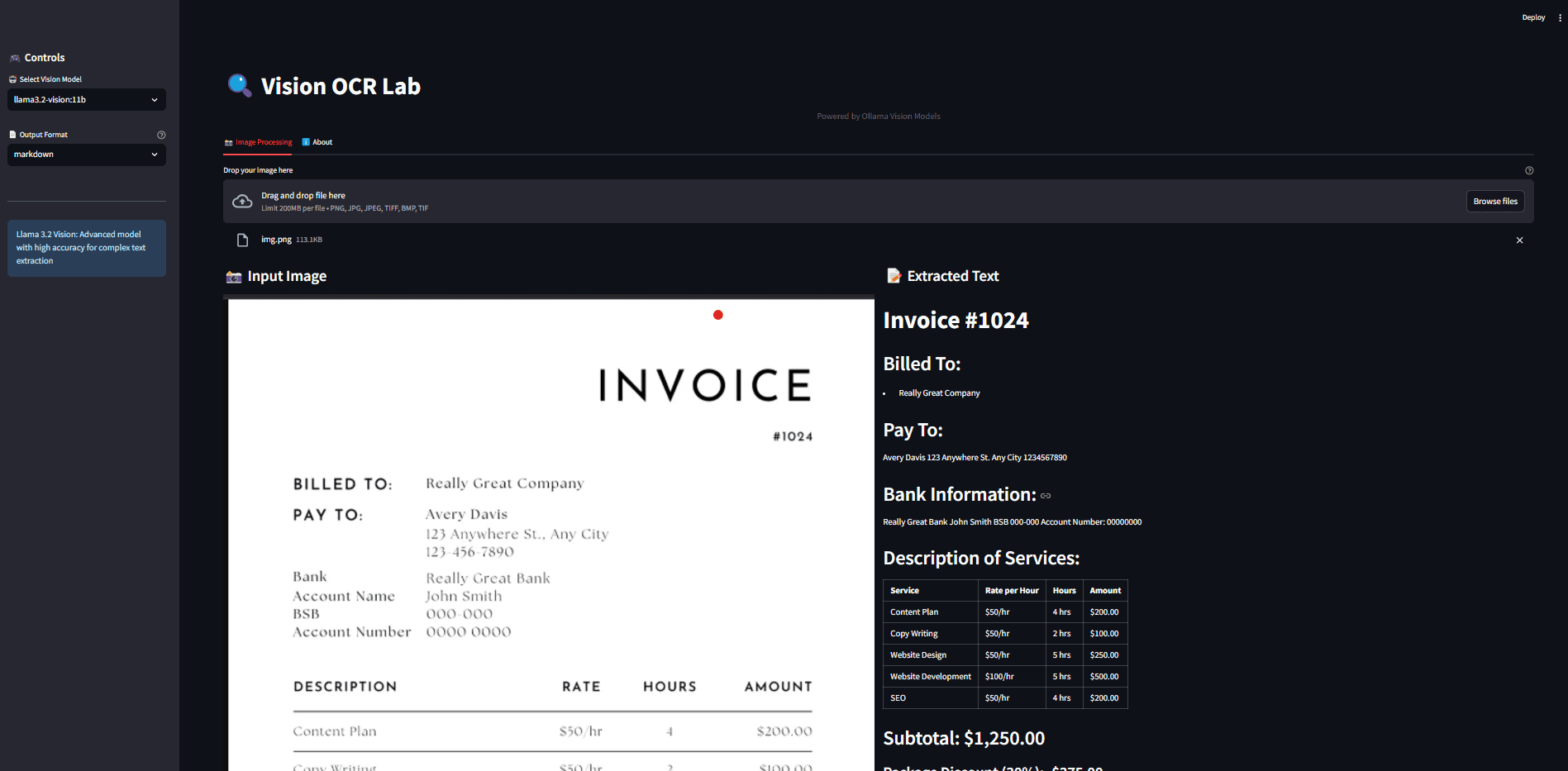
Ollama OCR: Ollamaの視覚モデルを使った画像からのテキスト抽出综合介绍 Ollama OCR是一个强大的光学字符识别(OCR)工具包,它利用Ollama平台提供的最先进视觉语言模型来从图像中提取文本。该项目既可作为Python包使用,也提供了用户友好的Strea...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング6ヶ月前02.2K
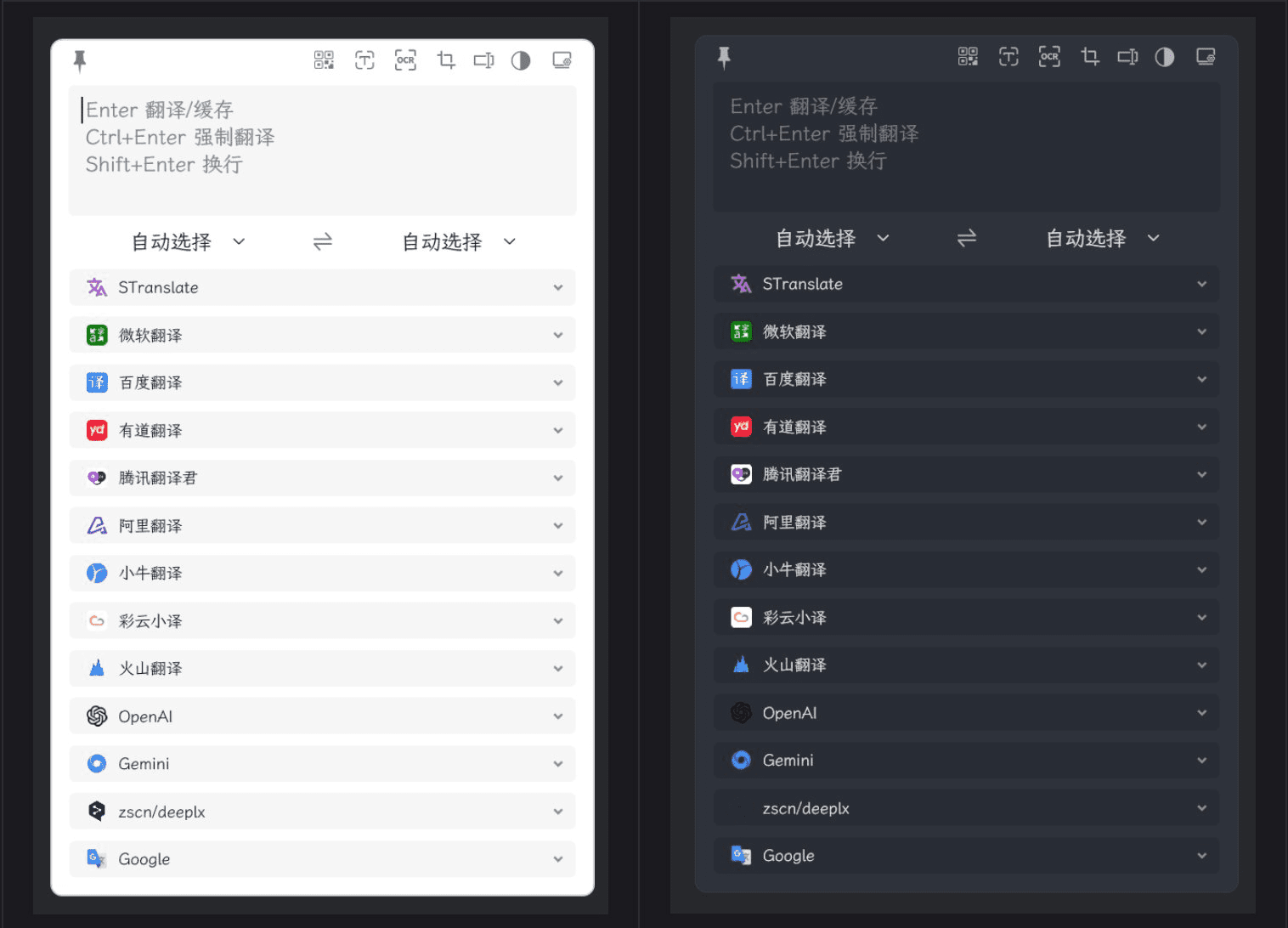
STranslate:複数の翻訳インターフェースとOCR機能を備えた軽量翻訳ツール一般的な紹介 STranslateは、WPFによって開発されたすぐに使用できる翻訳とOCRツールです。このツールは、幅広い言語とテキストタイプに対して、効率的で便利な翻訳と光学式文字認識(OCR)機能を提供するように設計されています。最新のAIツール# AI翻訳# OCR7ヶ月前01.1K
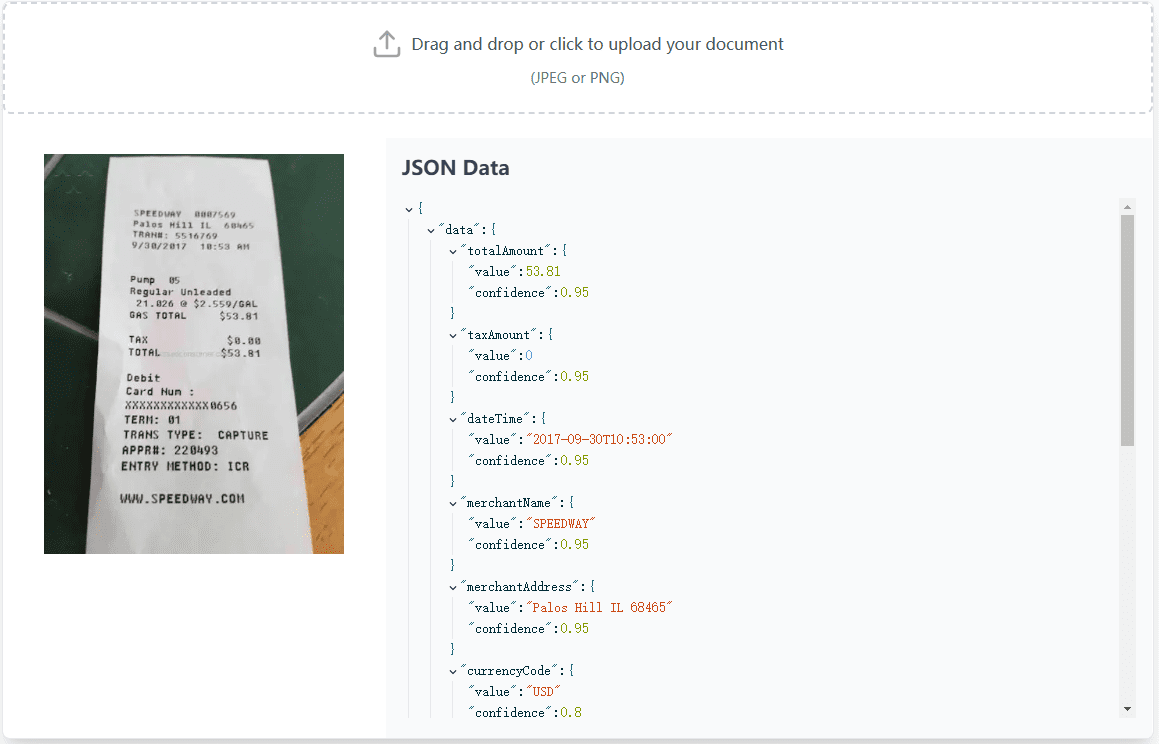
VisionParser:領収書や請求書を高精度に処理するOCRツール、APIあり综合介绍 VisionParser是一款专为处理收据和发票而设计的OCR(光学字符识别)工具。通过先进的生成式AI技术,VisionParser能够快速、准确地将各种收据和发票转换为结构化数据,适用于...最新のAIツール# OCR7ヶ月前01.1K
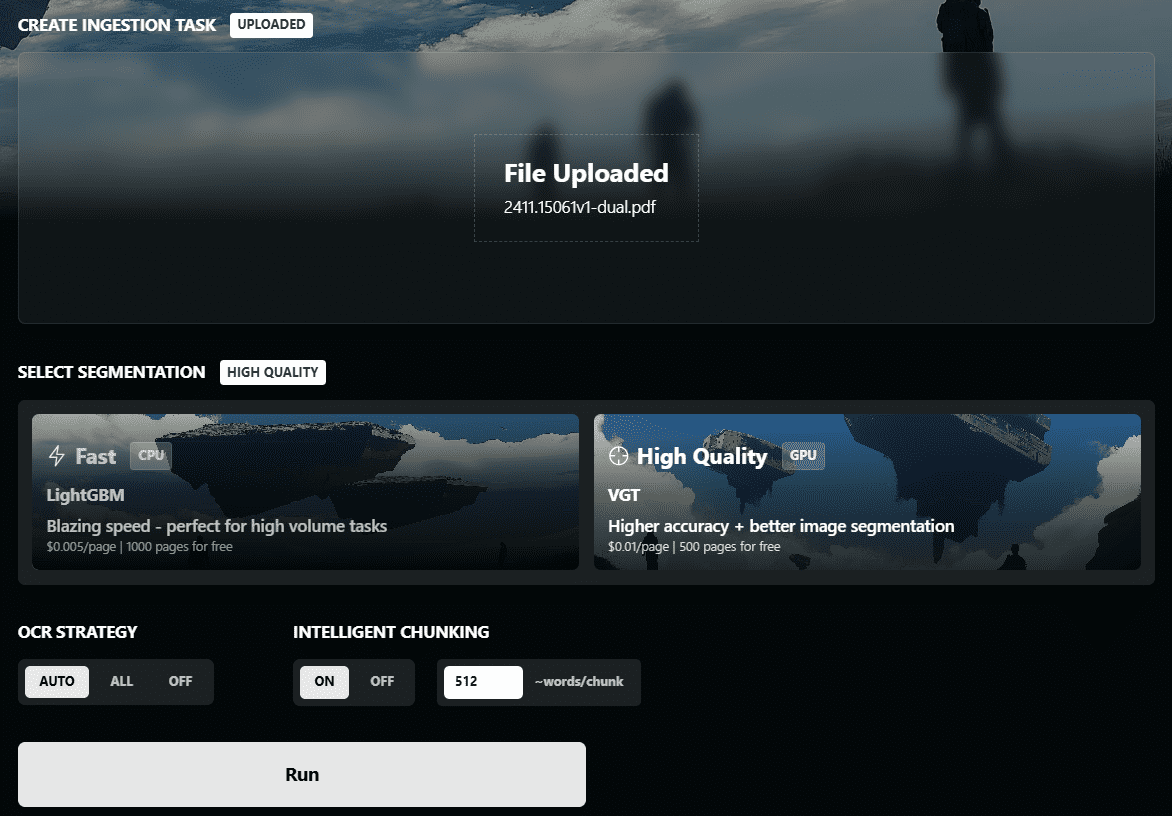
Chunkr: 文書の取り込みにビジュアルモデルを使用し、テキストの段落階層に基づくインテリジェントなチャンキングを行うオールインワンサービス。综合介绍 Chunkr 是一个自托管的 API,专门用于将 PDF、PPTX、DOCX 和 Excel 文件转换为适合 RAG(检索增强生成)和 LLM(大语言模型)使用的数据。该项目由 Lumina...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング7ヶ月前01.3K
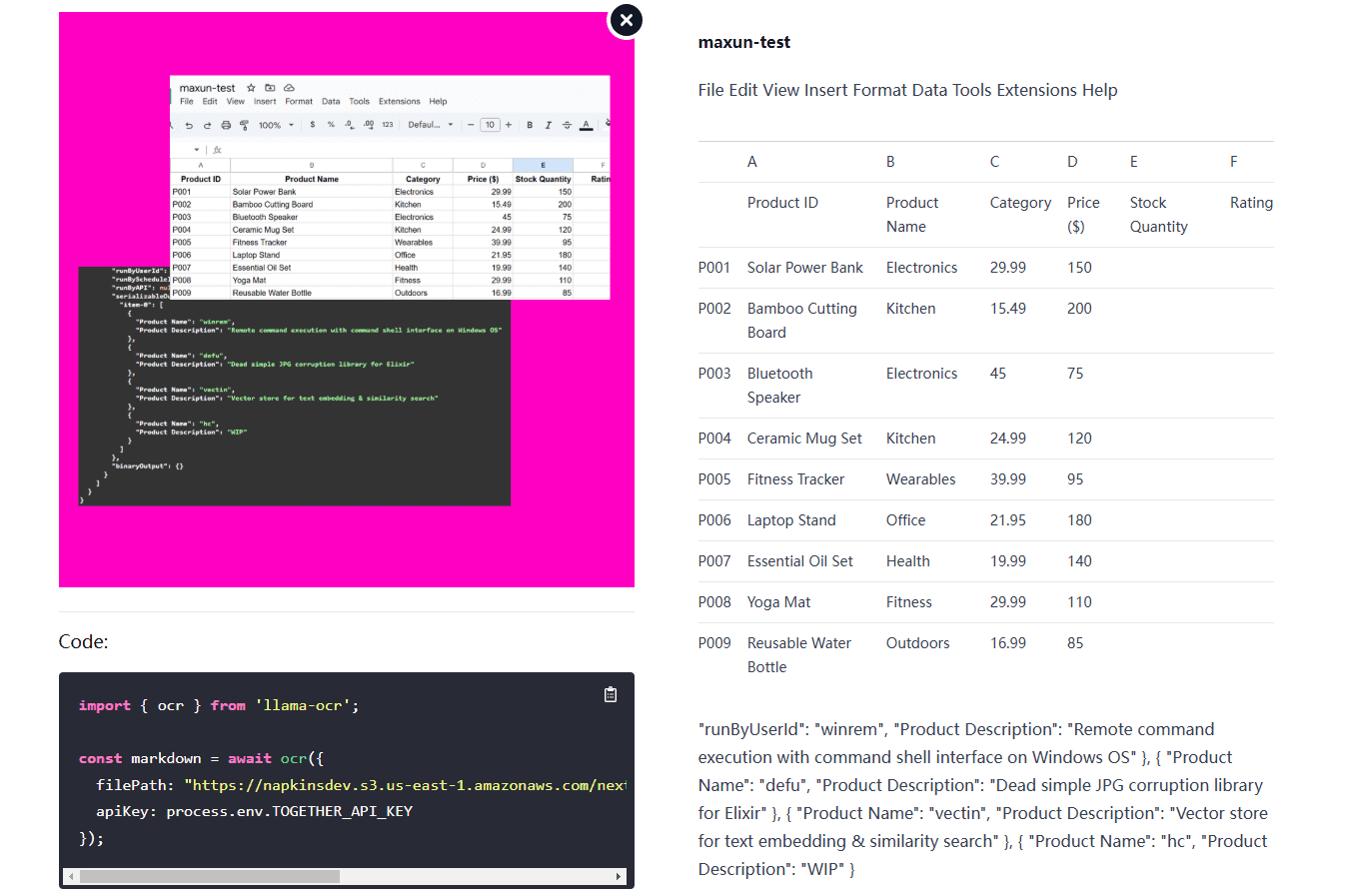
Llama OCR: 3行のコードで画像をMarkdownに変換するOCRライブラリ。概要 Llama OCRは、Llama 3.2 VisionをベースにしたOCR(光学式文字認識)ライブラリで、文書をMarkdown形式に変換することができます。このライブラリーはNutlope社によって開発され、Togetherを使用しています。最新のAIツール# AI Java オープンソースプロジェクト# OCR# Free Large Model API7ヶ月前01.4K
Docling:様々なフォーマットのドキュメントをサポート MarkdownやJSONへの解析とエクスポート PDFサポート OCR包括的な紹介 Doclingは、PDF、DOCX、PPTX、XLSX、画像、HTML、AsciiDocおよびMarkdownを含む幅広い文書形式をサポートする強力な文書解析およびエクスポートツールです。最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング7ヶ月前02.1K
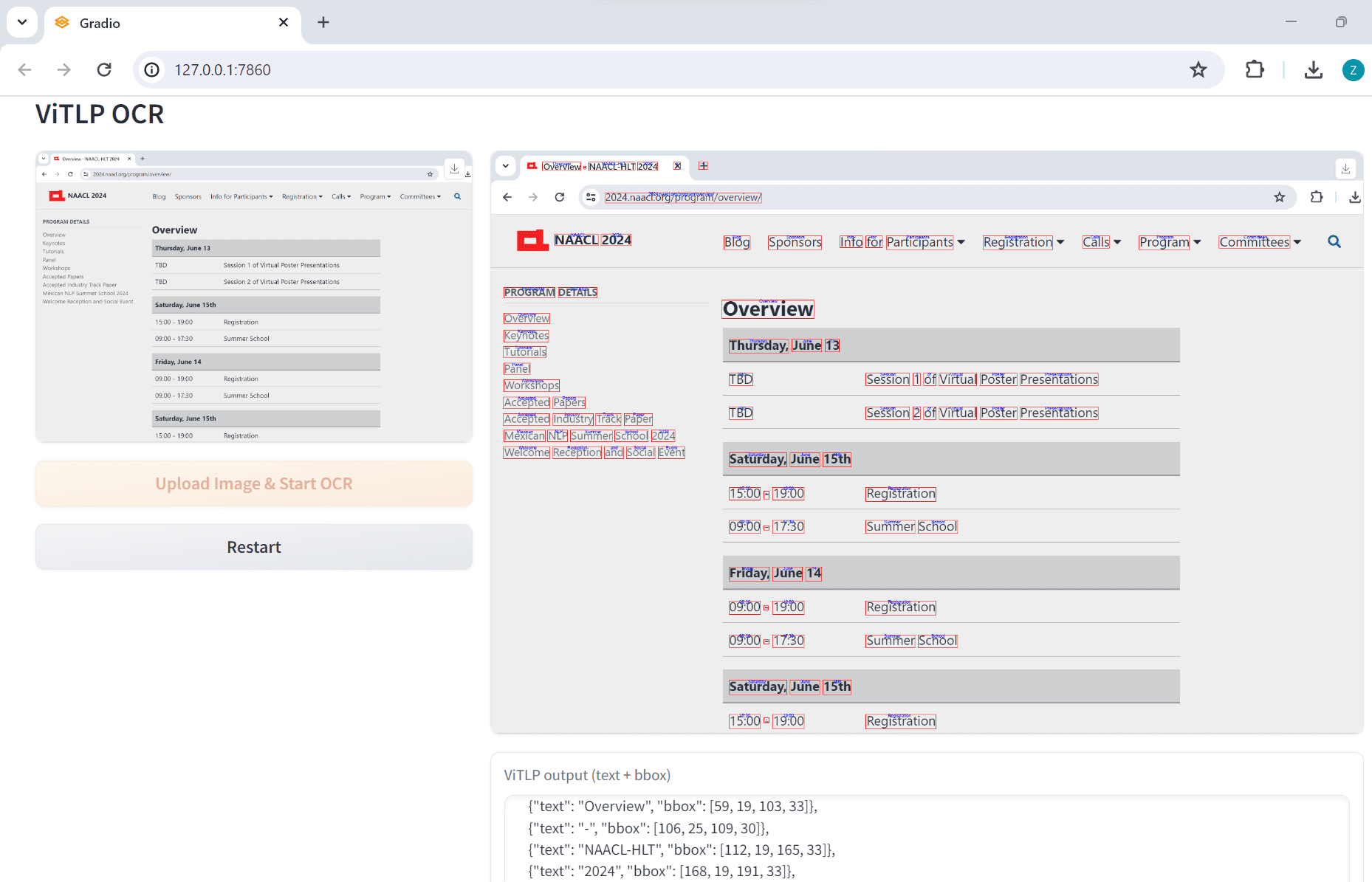
ViTLP: 組版が複雑なPDF文書から構造化データを抽出し、テキストレイアウトのための事前学習済みモデルを視覚的に誘導して生成する综合介绍 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)是一个开源项目,旨在通...最新のAIツール# OCR# ドキュメントの抽出とクリーニング7ヶ月前01.2K
ScreenPipe:記録された画面や操作情報を24時間収集し、AIアシスタント対話、要約、知識の見直しを通じて、ローカルの知識ベースに変換する概要 ScreenPipeはmediar-aiによって開発されたAIアシスタントツールで、スクリーンコンテンツの録画、スクリーンショットのキャプチャ、24時間365日の音声の録音に特化しています。rewind.aiとcursor.comを組み合わせたものです。最新のAIツール# AIテキストおよび音声/ビデオ要約ツール# AIノート# OCR8ヶ月前01.6K
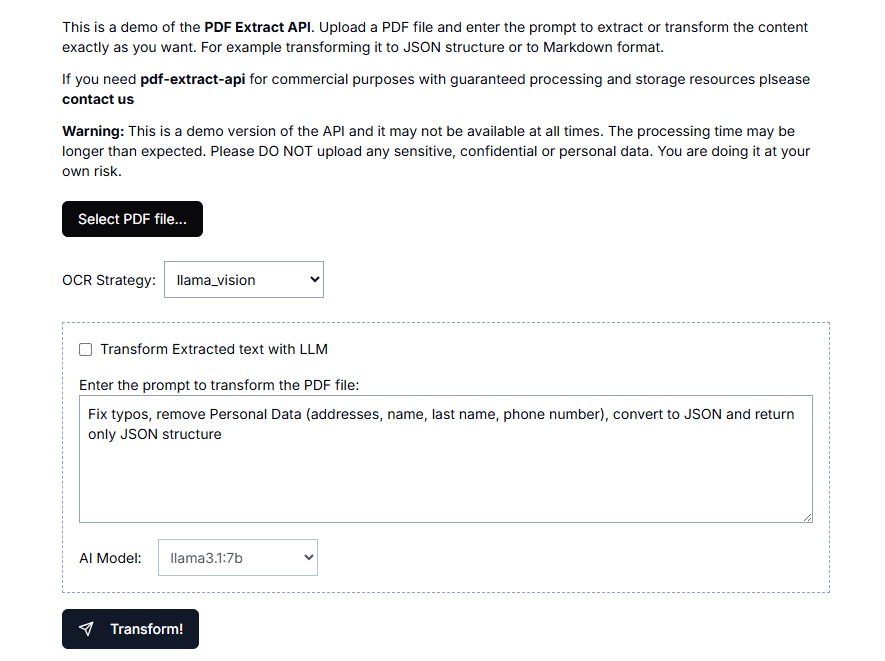
テキスト抽出 API (text-extract-api): テキスト情報の視覚的抽出、匿名化 PDF 抽出ツール包括的な紹介 テキスト抽出API(text-extract-api)は、さまざまな文書形式(PDF、Word、PPTXなど)からコンテンツを抽出し、解析するために設計された強力なツールです。このAPIは、最先端の光学式文字認識(OCR)技術とOl...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング6ヶ月前01.5K
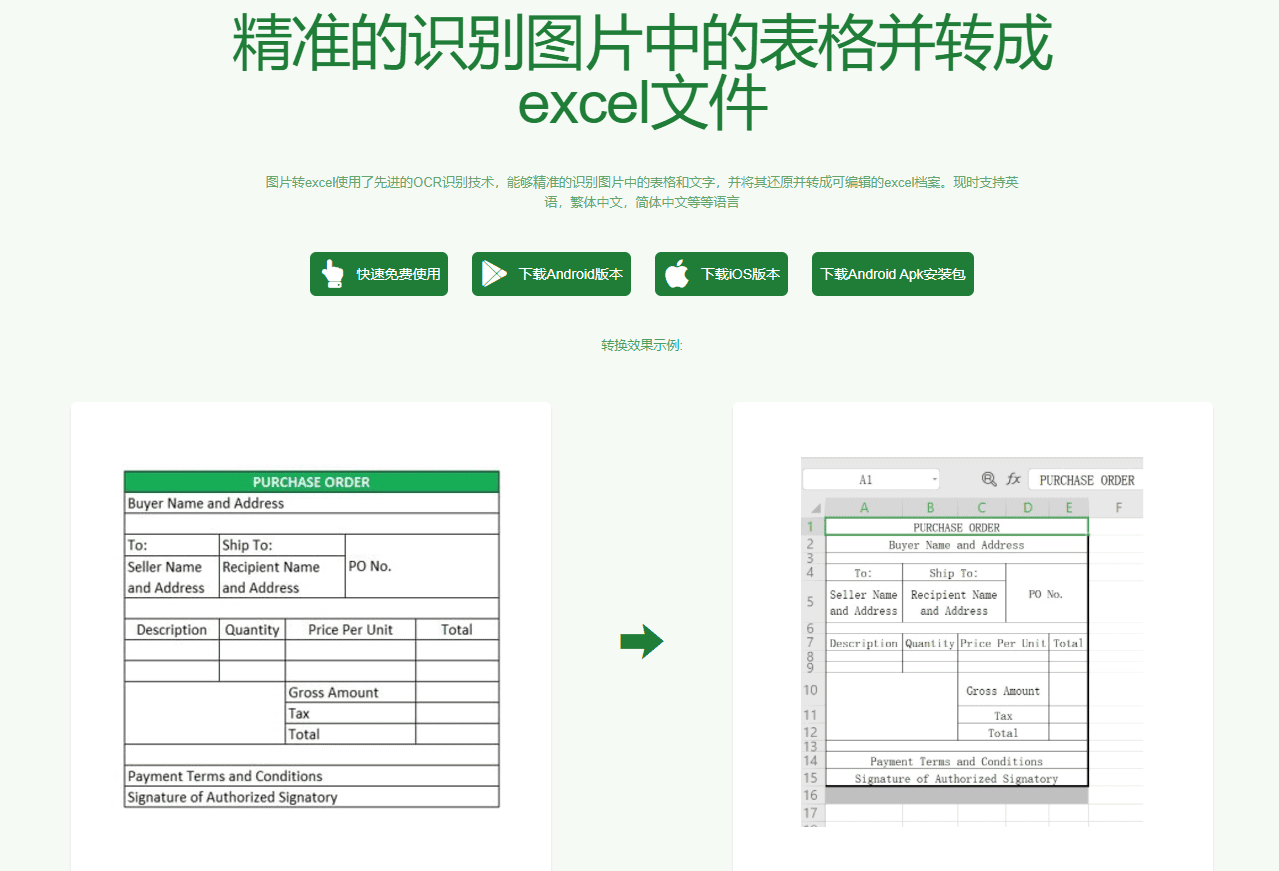
Picture to Excelフリーツール: 写真の複雑な書式を持つ表を効率的に識別し、Excelファイルに変換します。综合介绍 图片转Excel免费工具是一款高效的在线工具,能够快速准确地识别并转换图片中的表格数据至Excel文件。该工具支持多种图片格式,如JPG和PNG,并且可以在网页、iOS应用和Android应...最新のAIツール# OCR9ヶ月前01.4K
Datalab:専用のOCR認識AIモデル、PDF to Markdown(オープンソース/API)综合介绍 Datalab 提供了一系列先进的AI模型,专注于OCR、布局分析、PDF转Markdown等功能。这些模型不仅性能卓越,而且易于使用,并且是开源的。平台上的Marker模型可以快速准确地将...最新のAIツール# AIオープンサービス# AI Java オープンソースプロジェクト# OCR8ヶ月前01.6K
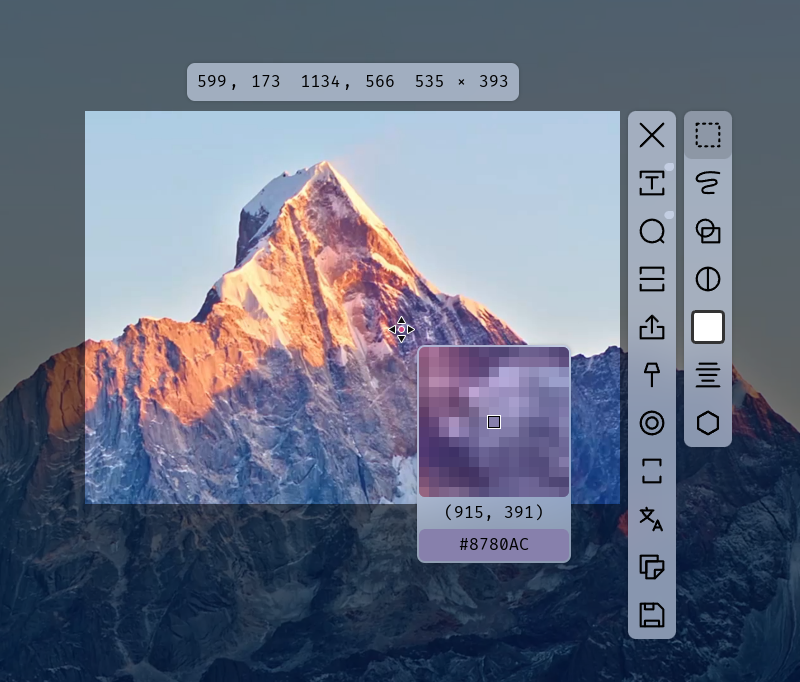
eSearch:多機能クロスプラットフォームOCRツール、統合検索|翻訳|検索マップ|画面録画およびその他の機能综合介绍 eSearch 是一款由 xushengfeng 开发的开源跨平台截图工具,支持 Windows、macOS 和 Linux 系统。它集成了多种功能,包括截图、OCR 识别、搜索、翻译、贴图...最新のAIツール# OCR9ヶ月前01.4K