2024년 중국 대형 모델 벤치마킹 보고서(SuperCLUE)

컨텍스트
2023년부터 AI 빅 모델은 전 세계적으로 역대 최대 규모의 AI 물결을 일으키고 있습니다. 2024년에 접어들면서 글로벌 빅 모델의 경쟁 역학 관계는 더욱 치열해지고 있습니다.2024년에는 소라, GPT-4o, o1이 출시되면서 국내 대형 모델들의 대형 모델 추격전이 벌어졌습니다.

중국 빅모델 평가 벤치마크 SuperCLUE는 국내외 빅모델의 발전 추세와 종합적인 효과를 실시간으로 지속적으로 추적하여 공식적으로 발표하고 있습니다.중국 대형 모델 벤치마킹 2024 연례 보고서.
전체 보고서는 89페이지로 구성되어 있으며, 이 글에서는 보고서의 주요 내용, 전체 보고서 온라인 주소(다운로드 가능)만 소개합니다:
www.cluebenchmarks.com/superclue_2024
슈퍼클루 리더보드 주소:
www.superclueai.com
보고서의 주요 요소
주요 구성 요소 1: 2024년에 가장 주목할 만한 대형 모델 파노라마

핵심 구성 요소 2: 연간 종합 순위 및 모델링 쿼드런트
평가 소개
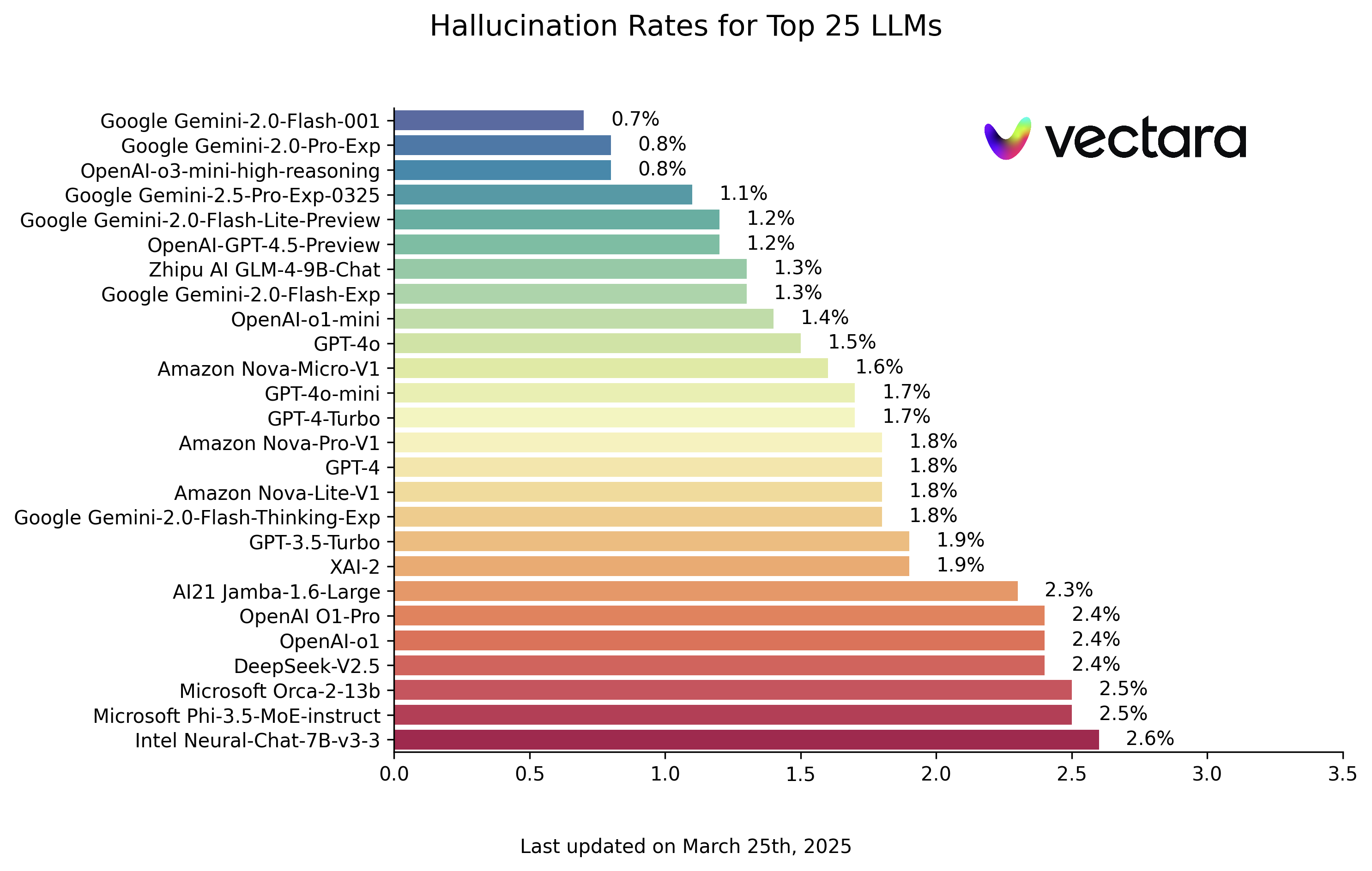
이 연례 보고서는 과학, 예술, 경도의 세 가지 차원으로 구성된 일반 역량 평가에 중점을 두고 있습니다.질문은 모두 독창적인 새로운 질문입니다.총 1,325개의 다라운드 단답형 문제로 구성되어 있습니다.
[과학 과제]는 컴퓨팅, 논리적 추론, 코드 평가 세트로, [예술 과제]는 언어 이해, 창의적 창작, 보안 평가 세트로, [어려운 과제]는 지시 사항 따르기, 심층 추론, 에이전트 평가 세트로 나뉩니다.

이번 평가의 데이터는 슈퍼클루 12월 평가 결과 중 국내외 대표 42개 대형 모델 중 12월 버전의 모델을 선정한 것입니다.

리그 테이블

연간 모델 쿼드런트

핵심 요소 3: 가성비 영역의 가치 분배

국내 대형 모델은 가성비(가격+효과) 측면에서 큰 장점이 있습니다.
DeepSeek-V3, Qwen2.5-72B-Instruct 및 Qwen2.5-32B-Instruct와 같은 국내 대형 모델은 가격 대비 성능 비율 측면에서 큰 경쟁력을 보여줍니다. 상대적으로 높은 수준의 기능을 기반으로 친숙한 사용성을 보여주기 위해 착륙 응용 프로그램에서 매우 낮은 응용 프로그램 비용을 유지할 수 있습니다.
대부분의 모델이 중간 가격대의 가성비를 자랑합니다.
대부분의 모델은 높은 수준의 기능을 유지하기 위해 여전히 높은 가격대를 유지하고 있습니다. 예를 들어 GLM-4-Plus, Qwen-Max 최신 버전, Claude 3.5 Sonnet, Grok-2-1212의 가격은 모두 백만 토큰당 30달러 이상입니다.
O1 및 기타 추론 모델 비용 효율성은 여전히 최적화할 여지가 많습니다.
o1과 o1-preview는 높은 수준의 기능을 제공하지만 가격 면에서 다른 모델보다 몇 배 더 비쌉니다. 추론 모델이 널리 사용되기 위해서는 비용을 절감하는 방법이 전제 조건이 될 수 있습니다.
핵심 구성 요소 4: 효율성 구간 분포에 대한 추론

일부 국내 모델은 전반적인 효율성 측면에서 경쟁력이 있습니다.
국내 모델 중 DeepSeek-V3와 Qwen2.5-32B-Instruct는 문제당 평균 추론 시간이 10초 이내로 추론 속도가 우수하며, 동시에 벤치마크 점수가 60점 이상으로 '고성능 영역'에 속하며 매우 강력한 적용 효과를 보여줍니다.
대형 모델 애플리케이션 성능에서 세계를 선도하는 Gemini-2.0-Flash-Exp
해외 모델인 Gemini-2.0-Flash-Exp, Claude 3.5 Sonnet(20241022), Grok-2-1212, GPT-4o-mini가 '고성능 영역'에 해당하며, 추론 시간과 벤치마크 점수를 합산한 효율 측면에서 Gemini-2.0-Flash-Exp가 가장 우수한 성능을 발휘했습니다. 추론 속도 측면에서는 GPT-4o-mini가 가장 우수한 성능을 보였습니다.
추론 모델성능 측면에서 최적화할 수 있는 여지가 많습니다.
o1-preview로 대표되는 추론 모델은 벤치마크 점수에서는 좋은 성능을 보이지만 문제당 평균 추론 시간이 약 40초로 전체 성능은 '저성능 영역'에 속합니다. 추론 모델은 다양한 적용 시나리오를 갖추기 위해 추론 속도를 개선하는 데 집중해야 합니다.
핵심 구성 요소 5: 국내외 대규모 모델링 격차 및 동향, 2024년

일반적인 추세는 중국 도메인에서 국내외 대형 모델 1단계의 일반 기능 간 격차가 벌어지고 있다는 것입니다.
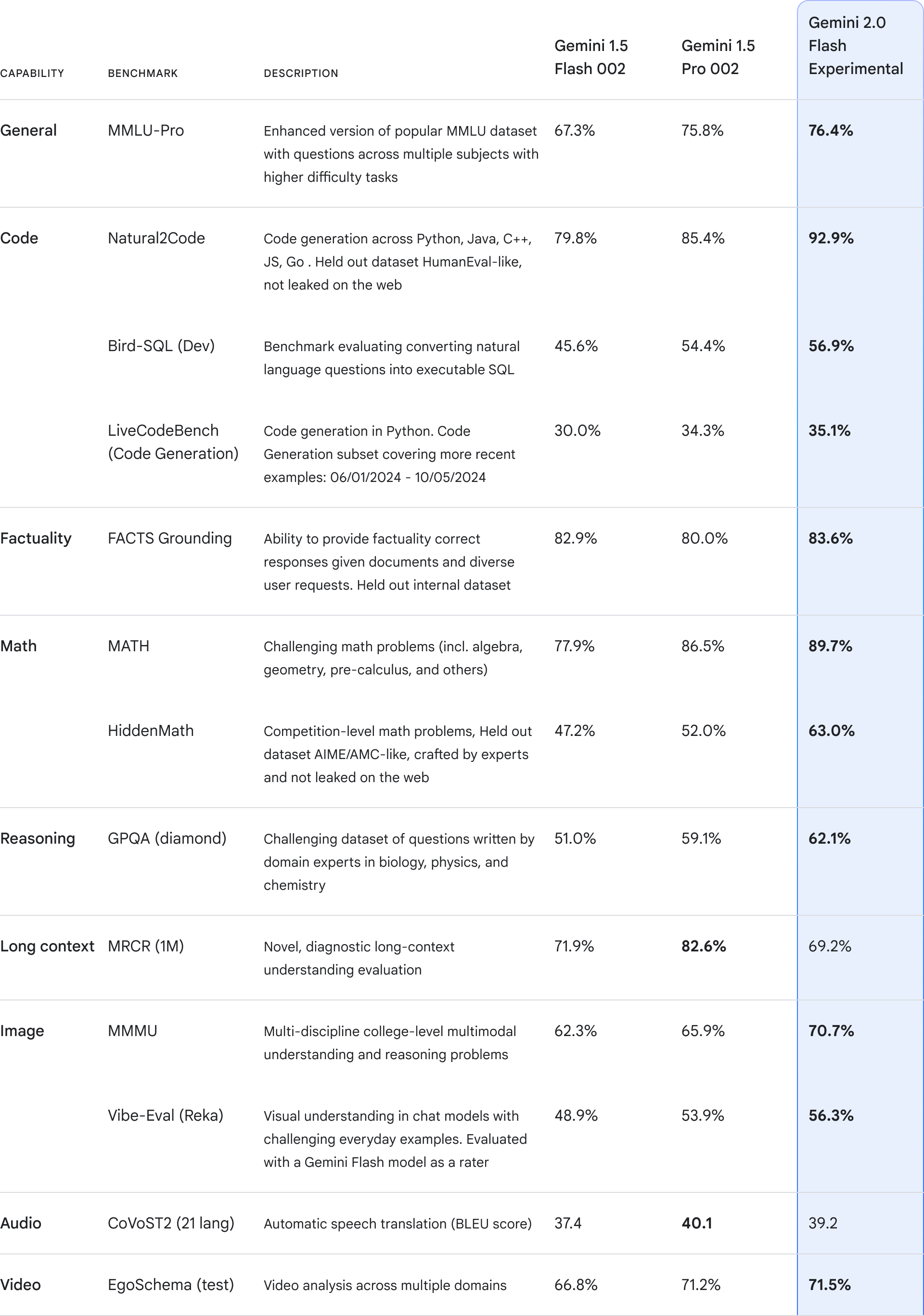
2023년 5월부터 현재까지 국내외 대형 모델 역량은 지속적으로 발전해 왔습니다. 그 중 GPT 시리즈 모델로 대표되는 해외 최고의 모델은 GPT3 . 5, GPT4, GPT4 - Turbo, GPT4o, o1까지 여러 버전의 반복적인 업그레이드를 거쳤습니다.
국내 모델도 1년 8개월의 반복 주기를 거치며 2024년 5월 0.121 TP3T에서 2024년 8월 1.291 TP3T로 격차가 좁혀졌지만, O1이 출시되면서 다시 15.051 TP3T로 격차가 벌어졌습니다.

딥시큐어-V3로 대표되는 국내 모델은 GPT-4o 최신 버전에 매우 근접하고 있습니다.
지난 2 년 동안 국내 대표 모델은 여러 버전으로 반복되어 왔으며 DeepSeek-V3, Doubao-pro, GLM-4-Plus 및 Qwen2.5는 중국 작업에서 GPT-4o에 근접했으며 그중 DeepSeek-V3는 12월 평가에서 Claude 3.5 Sonnet의 성능을 능가하는 좋은 성과를 거두었습니다.
o1 강화학습이라는 새로운 패러다임에 기반한 추론 모델, 80점을 돌파하며 국내외 상위 모델과의 격차 확대
12월 슈퍼클루 평가에서 슈퍼클루 벤치마크 점수의 국내외 주요 헤드 빅모델은 60~70점에 집중되어 있으며, 새로운 패러다임의 강화학습 추론 모델에 기반한 o1과 o1-preview는 70점대 병목현상 돌파를 대표하는 중요한 기술이 되었고 특히 o1 정식 버전은 80점대를 돌파하며 큰 선두 우위를 보이고 있습니다.
핵심 요소 6: 기타 하위 차원 목록
하드 리스트

과학 과목 목록

교양 목록

각 차원별 중국 내 상위 3위

오픈 소스 모델 목록

최대 10B 모델 목록

최대 5B의 엔드사이드 모델 목록

보조 세분화된 점수 목록

지면 제약으로 인해 이 백서에서는 보고서의 일부만 소개합니다. 전체 내용에는 평가 방법론, 평가 예시, 하위 작업 목록, 멀티모달리티, 애플리케이션 및 추론 벤치마크 소개가 포함되어 있습니다.
© 저작권 정책
이 글은 저작권이 있으며 무단으로 복제해서는 안 됩니다.

관련 문서


댓글 없음...