함정 피하기 가이드: 타오바오 딥시크릿 R1 설치 패키지 유료 상향 판매? 로컬 배포를 무료로 알려드립니다(원클릭 설치 프로그램 포함).

近期, 淘宝平台上 DeepSeek 安装包的倒卖现象引发了广泛关注。这款免费开源的 AI 模型,竟让部分商家从中牟取暴利,着实令人惊讶。这也侧面反映出,DeepSeek 模型所引发的本地部署热潮正席卷而来。

在淘宝和拼多多等电商平台搜索 “DeepSeek”,可以发现许多商家正在销售原本可以免费获得的资源,包括安装包、提示词包、教程等。 甚至一些卖家将 DeepSeek 相关教程也进行标价出售, 但实际上,用户只需通过搜索引擎即可轻松找到大量免费下载链接。

那么,这些资源的售价如何呢? 据观察, “安装包 + 教程 + 提示词” 的打包价格通常在 10 元至 30 元不等, 且多数商家还提供一定的客服支持。 其中,不少商品已售出数百份,少数热门商品甚至 достигают 千人付款的规模。 更令人诧异的是, 一款定价 100 元的软件包和教程, 也有 22 人选择购买。

信息差带来的商业机会,由此可见一斑。
本文将指导读者如何在本地设备上部署 DeepSeek 模型,且完全无需任何费用。 在此之前, 先简要分析本地部署的必要性。
为何选择本地部署 DeepSeek-R1?
DeepSeek-R1 模型, 尽管可能并非当前性能最顶尖的推理模型, 但无疑是市场上备受瞩目的选择。 然而, 若直接使用官方或第三方托管平台的服务, 用户经常会遇到服务器拥堵的问题。
本地部署模型能够有效规避此类问题。 简而言之, 本地部署指的是在用户自身的设备上安装 AI 模型, 而非依赖云端 API 或在线服务。 常见的本地部署方式主要包括以下几种:
- 轻量级本地推理: 在个人电脑或移动设备上运行,例如 Llama.cpp、Whisper、GGUF 格式模型。
- 服务器/工作站部署: 利用高性能 GPU 或 TPU 运行大型模型, 如 NVIDIA RTX 4090、A100 等。
- 私有云/内网服务器: 在企业内部服务器上进行部署, 例如使用 TensorRT、ONNX Runtime、vLLM 等工具。
- 边缘设备部署: 在嵌入式系统或 IoT 设备上运行 AI 模型, 例如 Jetson Nano、树莓派等。
不同的部署方式适用于不同的应用场景。 本地部署技术在多个领域都展现出其独特的价值, 例如:
- 企业内部 AI 应用: 构建私有聊天机器人、文档分析系统等。
- 科研计算: 应用于生物医药、物理仿真等领域的数据分析和模型训练。
- 离线 AI 功能: 在无网络环境下提供语音识别、OCR、图像处理等能力。
- 安全审计与监控: 辅助法律、金融等行业的合规性分析。
本文将重点关注轻量级本地推理, 这也是最贴合广大个人用户需求的部署方案。
本地部署的优势
除了从根本上解决 “服务器繁忙” 的问题, 本地部署还具备诸多优势:
- 数据隐私与安全: 本地部署 AI 模型无需将敏感数据上传至云端, 有效防止数据泄露风险。 这对于金融、医疗、法律等对数据安全性要求极高的行业至关重要。 此外, 本地部署也有助于企业或机构满足数据合规性要求, 例如中国的《数据安全法》、欧盟的 GDPR 等。
- 低延迟与实时性能: 由于所有计算均在本地执行, 无需网络请求, 推理速度完全取决于本地设备的计算性能。 因此, 只要设备性能足够, 用户便可获得极佳的实时响应, 这使得本地部署非常适合对实时性有严格要求的应用场景, 如语音识别、自动驾驶、工业检测等。
- 长期成本效益: 本地部署免去了 API 订阅费用, 实现一次部署,长期使用。 对于性能要求不高的应用, 还可以通过部署轻量化模型(如 INT 8 或 4-bit 量化模型)来降低硬件成本。
- 离线可用性: 即使在没有网络连接的情况下, 也能正常使用 AI 模型, 适用于边缘计算、离线办公、远程环境等场景。 离线运行能力也保障了关键业务的连续性, 避免因断网导致业务中断。
- 高度定制化与可控性: 本地部署允许用户对模型进行微调和优化, 以更好地适应特定的业务需求。 例如, DeepSeek-R1 模型就衍生出众多微调和蒸馏版本, 包括无限制版本 deepseek-r1-abliterated 等。 此外, 本地部署不受第三方政策变动的影响, 具有更强的可控性, 避免了 API 价格调整或访问限制等潜在风险。
本地部署的局限性
本地部署优势显著, 但其局限性亦不可忽视, 其中最主要的挑战便是大型模型对算力的需求。
- 硬件成本投入: 个人用户的本地设备往往难以流畅运行参数规模庞大的模型, 而参数较小的模型在性能上又可能有所妥协。 因此, 用户需要在硬件成本和模型性能之间进行权衡。 若要追求高性能模型, 则不可避免地需要增加硬件投入。
- 大规模任务处理能力: 面对需要大规模数据处理的任务时, 往往需要服务器级别的硬件支持才能有效完成。 个人设备在处理能力上存在天然瓶颈。
- 技术门槛: 相较于便捷的云服务——只需访问网页或配置 API 即可使用, 本地部署存在一定的技术门槛。 如果用户有进一步的模型微调需求, 部署难度将进一步提升。 但值得庆幸的是, 本地部署的技术门槛正在逐步降低。
- 维护成本: 模型和相关工具的升级迭代可能引发环境配置问题, 用户需要投入时间和精力进行维护和问题解决。
因此, 选择本地部署还是在线模型, 需要用户根据自身的实际情况进行综合考量。 以下是本地部署适用和不适用场景的简要总结:
- 适合本地部署的场景: 高隐私需求、低延迟要求、长期使用(如企业 AI 助手、法律分析系统等)。
- 不适合本地部署的场景: 短期测试验证、高算力需求、依赖超大型模型(如 70B+ 参数级别)。
使用云端免费服务器私有化部署也是不错的方式,很早以前就推荐过,但需要一定技术基础:使用免费 GPU 算力在线部署 DeepSeek-R1 开源模型
DeepSeek-R1 本地部署实战
本地部署 DeepSeek-R1 的方法多样, 本文将介绍两种简易方案: 基于 Ollama 的部署方法以及使用 LM Studio 的零代码部署方案。
方案一: 基于 Ollama 部署 DeepSeek-R1
Ollama 是当前主流的本地语言模型部署与运行框架。 它以轻量化和高扩展性为特点, 自 Meta 发布 Llama 系列模型后迅速崛起。 尽管名称与 Llama 相似, 但 Ollama 项目由社区驱动, 与 Meta 及 Llama 系列模型的开发并无直接关联。

Ollama 项目发展迅猛, 其支持的模型种类和生态系统都在快速扩张。
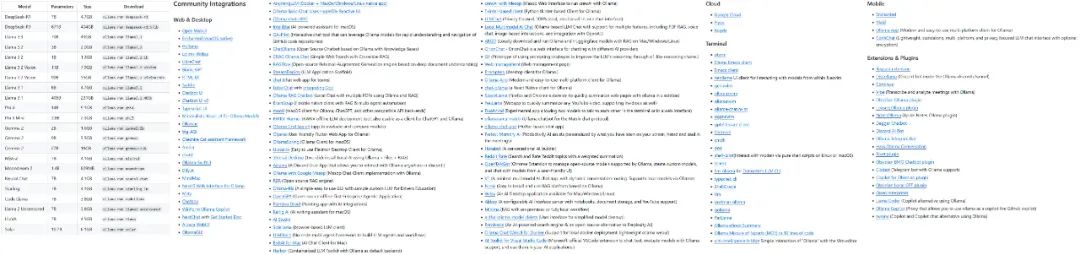
Ollama 支持的部分模型和生态
使用 Ollama 的首要步骤是下载并安装 Ollama 软件。 访问 Ollama 官网下载页面, 选择与操作系统相匹配的版本即可。
下载地址:https://ollama.com/download
安装 Ollama 后, 还需要为设备配置 AI 模型。 以 DeepSeek-R1 为例进行演示。 访问 Ollama 官网的模型库, 浏览其支持的模型及版本信息:
https://ollama.com/search
DeepSeek-R1 在 Ollama 模型库中提供了从 1.5B 到 67B 等多种规模共 29 个不同版本, 其中包括基于开源模型 Llama 和 Qwen 微调、蒸馏或量化后的版本。

选择哪个版本取决于用户的硬件配置。 dev.to 开发者社区的 Avnish 撰文总结了 DeepSeek-R1 不同规模版本的硬件需求, 可供参考:
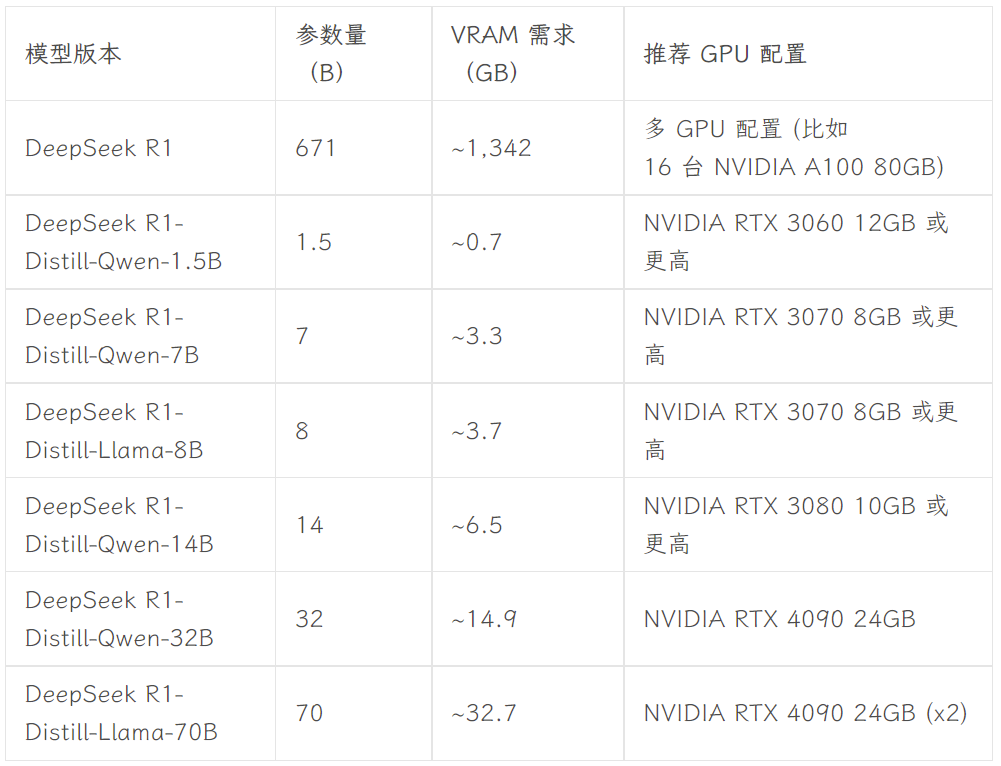
图片来源:https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
本文以 8B 版本为例进行演示。 打开设备终端, 运行以下命令:
ollama run deepseek-r1:8b
接下来, 只需等待模型下载完成。(Ollama 也支持直接从 Hugging Face 下载模型, 命令格式为 ollama run hf.co/{用户名}/{库}:{量化版本}, 例如 ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0。)
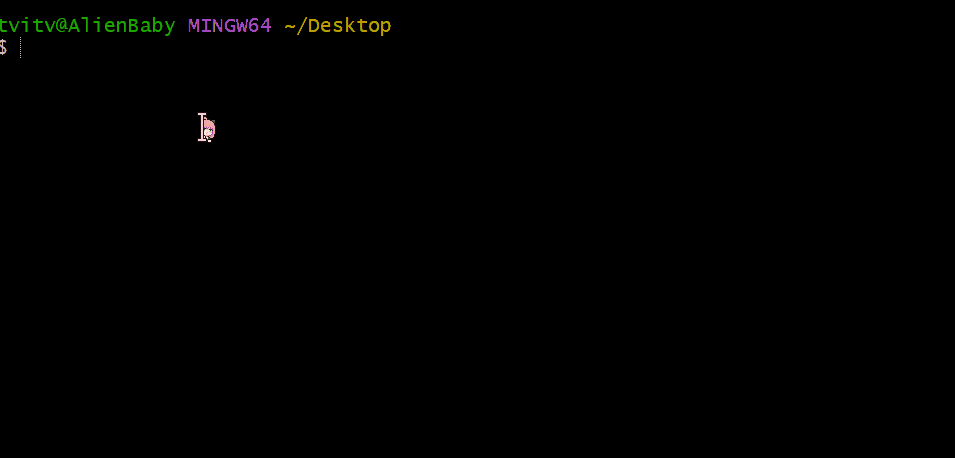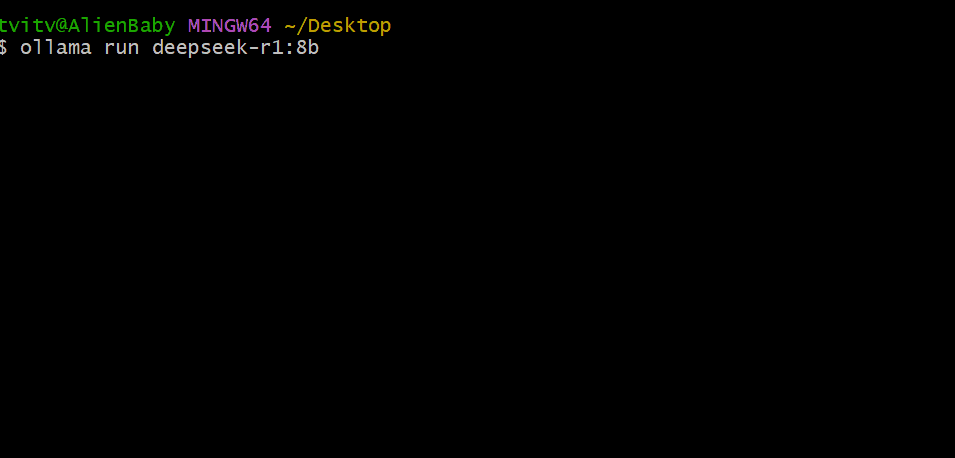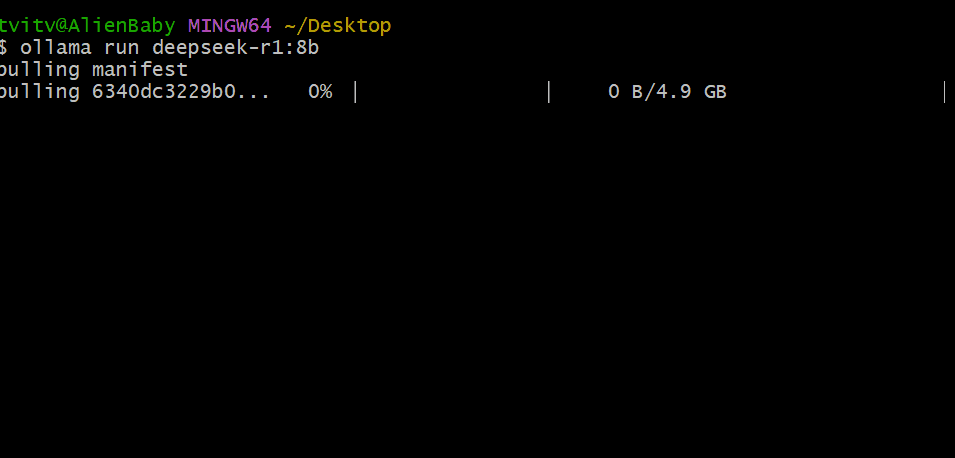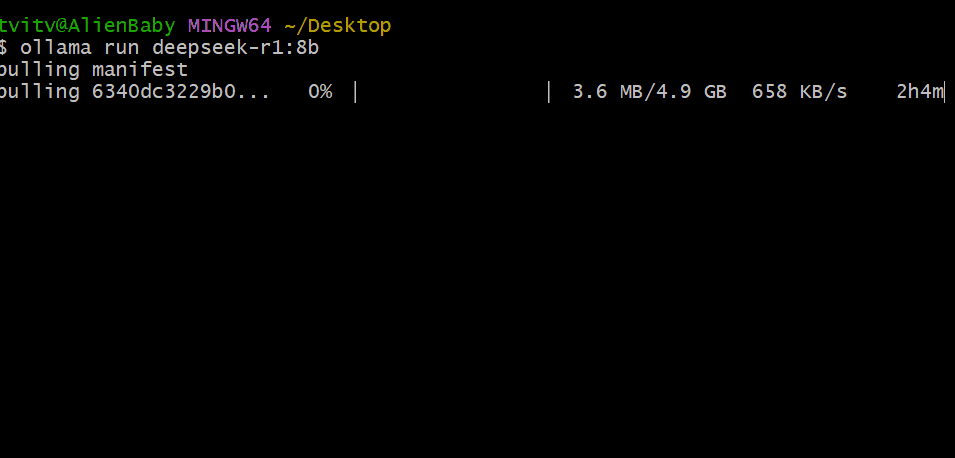
模型下载完成后, 即可在终端中与 8B 版本的 DeepSeek-R1 进行对话。

然而, 对于普通用户而言, 这种终端对话方式并不直观, 操作也不够便捷。 因此, 还需要配置用户友好的图形界面前端。 前端选择非常丰富, 例如, 可以使用 WebUI 열기 在浏览器中获得类似 ChatGPT 的交互体验, 也可以选择 Chatbox 等桌面应用程序。 更多前端选择可参考 Ollama 官方文档:
https://github.com/ollama/ollama
- WebUI 열기
若选择 Open WebUI, 只需在终端中依次运行以下两行代码即可:
安装 Open WebUI:
pip install open-webui
运行 Open WebUI 服务:
open-webui serve
之后, 在浏览器中访问 http://localhost:8080, 即可体验类似 ChatGPT 的 Web 界面。 在 Open WebUI 的模型列表中, 可以看到本地 Ollama 已配置的多个模型, 包括 DeepSeek-R1 7B 和 8B 版本, 以及 Llama 3.1 8B、 Llama 3.2 3B、 Phi 4、 Qwen 2.5 Coder 等其他模型。 选择 DeepSeek-R1 8B 模型进行测试:

- Chatbox
如果用户更倾向于使用独立的桌面应用程序, 可以考虑 Chatbox 等工具。 配置步骤同样简单, 首先下载并安装 Chatbox 应用程序:
https://chatboxai.app/zh
启动 Chatbox 后, 进入 “设置” 界面, 在 “模型提供方” 中选择 OLLAMA API, 然后在 “模型” 栏选择希望使用的模型, 并根据需要设置上下文消息数量上限和 Temperature 等参数(也可保持默认设置)。

完成配置后, 即可在 Chatbox 中与本地部署的 DeepSeek-R1 模型进行流畅对话。 但测试结果显示, DeepSeek-R1 7B 模型在处理复杂指令时表现略有不足。 这也印证了前文的观点, 即个人用户在本地设备上通常只能运行性能相对有限的模型。 然而, 可以预见的是, 随着硬件技术的持续发展, 未来个人用户本地使用大参数量模型的门槛将进一步降低—— 并且这一天或许不会太遥远。

**无论是 Open WebUI 还是 Chatbox, 都支持通过 API 接入 DeepSeek 的各类模型以及 ChatGPT、 Claude、 쌍둥이자리 等商业模型。 用户可以将它们作为日常使用 AI 工具的前端界面。 此外, 还可以将 Ollama 中配置的模型集成到其他工具中, 例如 Obsidian 和思源笔记等笔记应用。
方案二: 使用 LM Studio 零代码部署 DeepSeek-R1
对于不熟悉命令行操作或代码的用户, 可以使用 LM Studio 实现 DeepSeek-R1 的零代码部署。 首先, 访问 LM Studio 官网下载页面, 下载与操作系统匹配的程序:
https://lmstudio.ai
安装完成后启动 LM Studio。 在 “My Models” 选项卡中, 为模型设置本地存储文件夹:
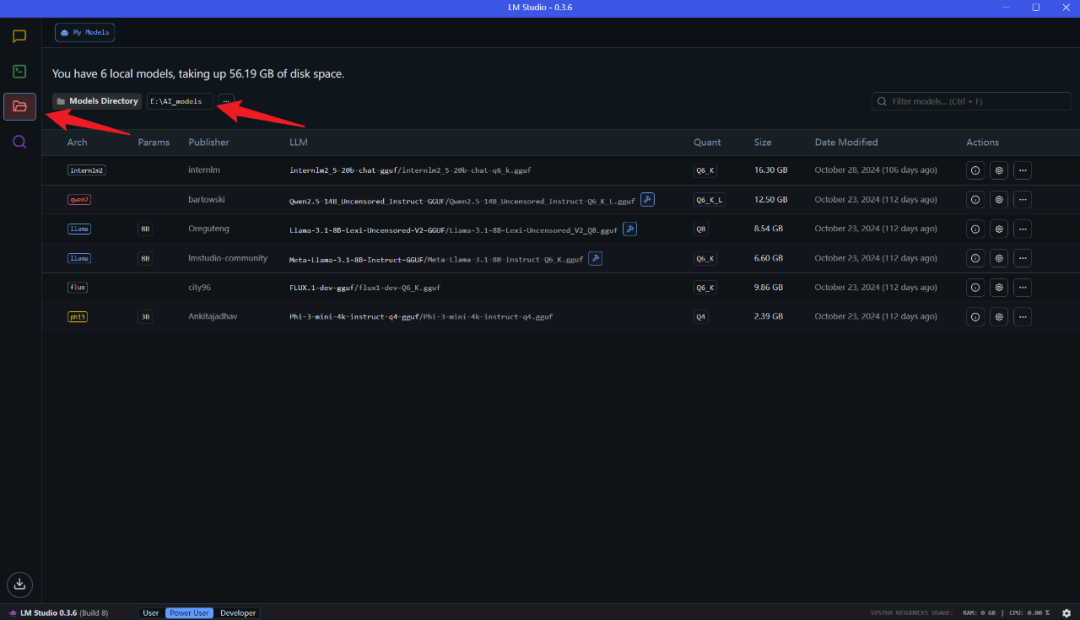
接下来, 从 Hugging Face 下载所需的语言模型文件, 并按照指定的目录结构放置到上述文件夹中(LM Studio 内置模型搜索功能, 但实测效果欠佳)。 注意, 这里需要下载 .gguf 格式的模型文件。 例如, Unsloth 组织提供的 DeepSeek-R1 模型集合:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
考虑到硬件配置, 本文选择基于 Qwen 模型微调的 DeepSeek-R1 蒸馏版(14B 参数量), 并选用 4-bit 量化版本: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf。
下载完成后, 按照以下目录结构将模型文件放入之前设定的文件夹:
模型文件夹 /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
最后, 打开 LM Studio, 在应用界面上方选择要加载的模型, 即可与本地模型进行对话。

LM Studio 的最大优势在于完全零代码操作, 无需使用终端或编写任何代码—— 只需完成软件安装和文件夹配置即可, 对用户非常友好。
요약
本文提供的教程仅在基础层面实现了 DeepSeek-R1 的本地部署。 若要将这一热门模型更深入地融入本地工作流程, 还需要进行更细致的配置, 例如设置系统提示词, 以及更高级的模型微调、 RAG 集成、 搜索功能、 多模态能力和工具调用能力等。 同时, 随着 AI 专用硬件和小模型技术的不断发展, 相信未来本地部署大型模型的门槛将持续降低。 阅读本文后, 读者是否愿意尝试自行部署 DeepSeek-R1 模型呢?
附 DeepSeek R1+OpenwebUI一键安装包
剑27提供的一键安装包,特别为 DeepSeek 集成了 WebUI 열기
DeepSeek 本地部署一键运行,解压即可使用 支持1.5b 7b 8b 14b 32b,最低支持2G显卡
설치 프로세스
1.AI环境下载:https://pan.quark.cn/s/1b1ad88c7244
2.安装包下载:https://pan.quark.cn/s/7ec8d85b2f95
原文中获取帮助:https://www.jian27.com/html/1396.html
© 저작권 정책
이 글은 저작권이 있으며 무단으로 복제해서는 안 됩니다.

관련 문서



댓글 없음...