
대형 모델의 매개 변수 수를 계산하는 방법과 7B, 13B 및 65B는 무엇을 의미하나요?

최근 대규모 모델 훈련 및 추론에 종사하는 많은 사람들이 모델 파라미터의 수와 모델 크기 사이의 관계에 대해 논의하고 있습니다. 예를 들어, 유명한 대형 모델인 알파카(alpaca) 시리즈에는 파라미터 크기가 서로 다른 네 가지 버전, 즉 LLaMA-7B, LLaMA-13B, LLaMA-33B 및 LLaMA-65B가 있습니다.
여기서 "B"는 10억을 의미하는 "Billion"의 약자입니다. 따라서 가장 작은 LLaMA-7B 모델에는 약 70억 개의 파라미터가 포함되며, 가장 큰 LLaMA-65B 모델에는 약 650억 개의 파라미터가 포함됩니다.
그렇다면 이러한 파라미터 수는 어떻게 계산되나요? 또한 100GB 모델 파일에 해당하는 대용량 모델 파라미터 수의 대략적인 수준은 어느 정도일까요? 수십억, 수백억, 수천억 또는 수조? 이 백서에서는 이러한 질문에 대한 심층적인 답변을 제공합니다.
I. 대규모 모델 파라미터 수량 계산 방법
빅 모델의 인프라인 트랜스포머를 예로 들어 파라미터 카운팅 과정을 자세히 분석해 보겠습니다.
표준 트랜스포머 이 모델은 서로 겹쳐진 L개의 동일한 레이어로 구성되며, 각 레이어에는 자기 주의 레이어(SAL)와 피드 포워드 신경망 레이어(MLP)라는 두 가지 주요 부분이 있습니다.
1. 자기 주의
셀프 어텐션 메커니즘은 트랜스포머의 핵심입니다. 셀프 어텐션이든 멀티 헤드 셀프 어텐션(MHA)이든 핵심 파라미터 수량을 계산하는 방식은 동일합니다.
자기 주의 계층에서 입력 시퀀스는 먼저 쿼리 벡터(쿼리, Q), 키 벡터(키, K), 값 벡터(값, V)의 세 가지 벡터로 매핑됩니다. MHA에서는 이 세 개의 벡터가 다시 여러 개의 헤드로 분할되며, 각 헤드는 입력 시퀀스의 다른 부분에 집중하는 역할을 담당합니다.

- 싱글 헤드 셀프 어텐션. Q, K, V는 각각 [h, h] 형태의 가중치 행렬로 선형적으로 변환되며, 여기서 h는 숨겨진 레이어 차원입니다. 따라서 Q, K, V의 총 파라미터 수는 3h²입니다. 또한 동일한 가중치 행렬 모양 [h, h]의 출력에 대한 선형 변환 레이어가 있습니다. 따라서 단일 헤드 자기 주의에 대한 총 파라미터 수는 다음과 같습니다. 4h² (편향 용어 무시).
- 멀티헤드 주의(MHA). 각각 치수가 h_head = h / n_head인 n개의 헤드가 있다고 가정합니다. 각 헤드에는 [h, h_head] 형식의 별도의 Q, K, V 가중치 행렬이 있습니다. 따라서 각 헤드에 대한 Q, K, V 가중치 행렬의 파라메트릭 양은 3 * h * h_head = 3h²/n_head입니다. n_head 헤드의 총 파라메트릭 양은 n_head * (3h²/n_head) = 3h²입니다. 마지막으로 출력 레이어에 대한 선형 변환 가중치 행렬의 모양은 [h, h]입니다. 따라서 MHA의 총 파라미터 수는 다음과 같습니다. 4h² (편향 용어 무시).
따라서 셀프 어텐션 레이어의 매개변수 수는 단일 및 다중 헤드 모두에 대해 4h²로 근사화할 수 있습니다.
2. 피드 포워드 신경망 계층(MLP)
MLP 레이어는 두 개의 선형 레이어로 구성됩니다. 첫 번째 선형 레이어는 숨겨진 레이어 치수 h를 4h로 확장하고, 두 번째 선형 레이어는 다시 4h에서 h로 치수를 줄입니다.

- 첫 번째 선형 레이어의 가중치 행렬은 [h, 4h] 모양을 가지며 매개변수 수는 4h²입니다.
- 두 번째 선형 레이어는 4h²의 동일한 파라메트릭 수량을 가진 [4h, h] 모양의 가중치 행렬을 갖습니다.
따라서 MLP 레이어의 총 파라미터 수는 8h²(바이어스 항 무시)입니다.
3. 레이어 정규화
각 셀프 어텐션 및 MLP 레이어와 트랜스포머 출력의 마지막 레이어 뒤에는 일반적으로 레이어 노멀라이제이션 작업이 있습니다. 각 레이어 노멀라이제이션 레이어에는 두 개의 학습 가능한 파라미터가 포함됩니다:
- 스케일링 매개변수(감마): 모양은 [h]입니다.
- 번역 매개변수(베타): 모양은 [h]입니다.
각 트랜스포머 레이어에는 2개의 레이어 노멀라이제이션(각각 셀프 어텐션과 MLP 이후)과 출력 레이어 뒤에 1개의 레이어 노멀라이제이션이 있으므로, L 레이어 트랜스포머의 총 레이어 노멀라이제이션 파라미터 수는 (2L + 1) * 2h가 됩니다.
4. 퍼가기
입력 텍스트는 먼저 단어 임베딩 레이어를 통해 단어 벡터로 변환되어야 합니다. 단어 목록의 크기가 V이고 단어 벡터의 차원이 h라고 가정하면 단어 임베딩 레이어의 매개변수 수는 Vh가 됩니다.
5. 출력 레이어
출력 계층의 가중치 행렬은 일반적으로 단어 임베딩 계층과 공유(가중치 묶기)되어 매개변수 수를 줄이고 잠재적으로 성능을 개선합니다. 따라서 가중치 공유를 사용하면 일반적으로 출력 레이어에 파라미터 수가 추가되지 않습니다. 공유하지 않는 경우 매개변수 수는 Vh입니다.
6. 위치 인코딩
위치 인코딩은 입력 시퀀스에서 단어의 위치에 대한 정보를 모델에 제공하는 데 사용됩니다.
- 훈련 가능한 위치 코드. 학습 가능한 위치 인코딩을 사용하는 경우 매개변수의 수는 N * h이며, 여기서 N은 최대 시퀀스 길이입니다. 예를 들어 ChatGPT의 최대 시퀀스 길이는 4k입니다.
- 상대 위치 코드(예: RoPE 또는 ALiBi). 이러한 방법은 학습 가능한 매개 변수를 도입하지 않습니다.
위치 인코딩된 파라미터의 수가 상대적으로 적기 때문에 일반적으로 총 파라미터 수를 계산할 때 무시할 수 있는 수준입니다.
7. 총 참가자 수 계산
요약하면, L 레이어 트랜스포머 모델의 총 파라미터 수는 다음과 같습니다:
총 파라미터 개수 = L * (Self-Attention 파라미터 + MLP 파라미터 + LayerNorm 파라미터 * 2) + 임베딩 파라미터 + 출력 레이어 파라미터 + LayerNorm 파라미터(출력 레이어 이후)
총 파라미터 수 ≈ L * (4h² + 8h² + 4h) + Vh + (옵션 Vh) + 2h
총 파라미터 수 ≈ L * (12h² + 4h) + Vh + 2h(출력 레이어가 워드 임베딩 레이어와 가중치를 공유한다고 가정)
숨겨진 차원 h가 크면 기본 항 4h와 2h는 무시할 수 있으며 모델 파라미터의 수는 다음과 같이 더 근사화할 수 있습니다:
총 참가자 수 ≈ 12Lh² + Vh
8. 예상 LLaMA 참가자 수
다음 표는 다양한 버전의 LLaMA의 주요 파라미터와 그 파라미터 수의 추정치를 보여줍니다:
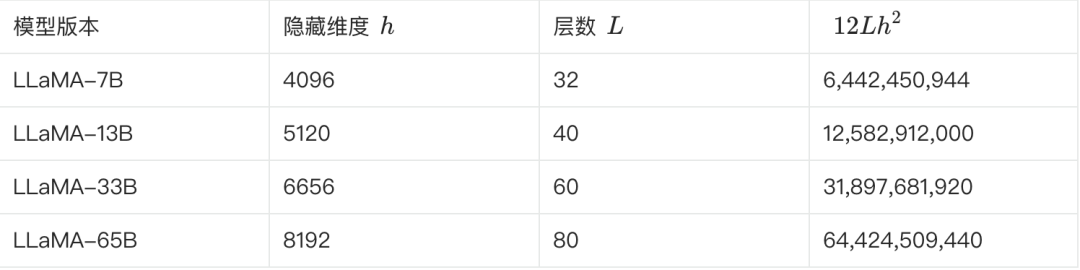
**위의 공식에 따라 이를 확인할 수 있습니다. LLaMA-7B를 예로 들면, 표에 따르면 L=32, h=4096, V=32000.**입니다.
예상 매개변수 수 ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6.55B
이 추정치는 67억 달러에 가깝습니다. 다른 여러 버전도 이러한 방식으로 추정하고 검증할 수 있습니다.
II. 대용량 모델 파라미터 수량을 모델 크기로 변환하기
파라미터 수가 어떻게 계산되는지 이해했으니 이제 파라미터 수와 모델 크기가 어떻게 변환되는지 살펴봅시다.
저희는 여전히 약 70억 명의 참여자를 보유한 LLaMA-7B를 예로 사용합니다.
- 이론적 계산. 각 파라미터가 FP32(4바이트를 차지하는 32비트 부동 소수점 숫자) 형식으로 저장되는 경우, LLaMA-7B의 이론적 크기는 7B * 4바이트 = 28GB입니다.
- 물리적 스토리지. 저장 공간을 절약하고 계산 효율성을 높이기 위해 모델 가중치는 일반적으로 FP16(2바이트를 차지하는 16비트 부동 소수점 숫자) 또는 BF16과 같은 저정밀 형식으로 저장됩니다. FP16 스토리지를 사용하는 경우 LLaMA-7B의 크기는 이론적으로 7B * 2바이트 = 14GB입니다.
- 기타 요인. 모델 파일에는 가중치 매개변수 외에도 최적화 프로그램 상태(예: 아담 최적화 프로그램의 모멘텀 및 분산), 단어 목록, 모델 구성 등에 대한 정보가 포함될 수 있으며, 이는 추가 저장 공간을 차지할 수 있습니다. 또한 일부 파라미터(예: 레이어 정규화를 위한 감마 및 베타)는 FP32 형식으로 저장될 수 있습니다.
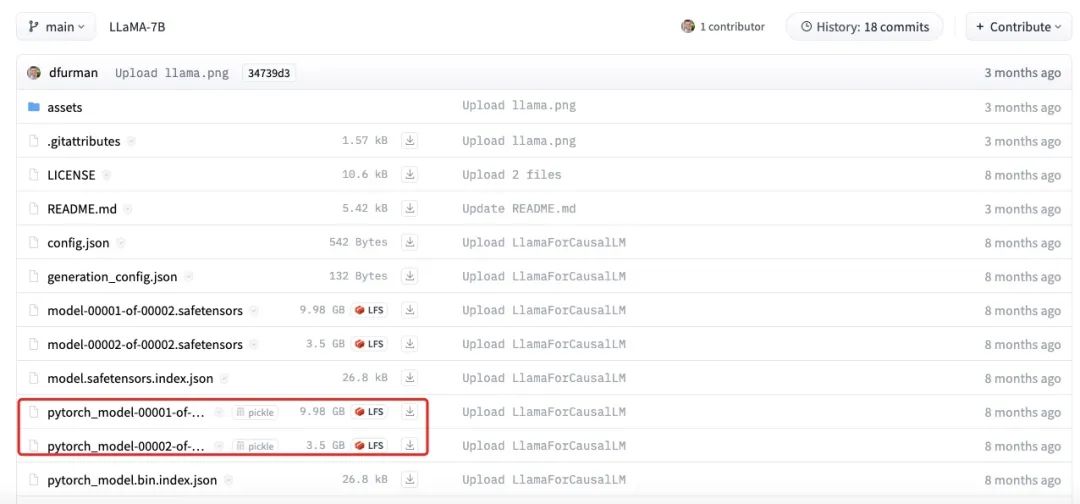
위 그림은 LLaMA-7B 모델 파일의 실제 크기를 보여줍니다. 각 부분의 총 크기가 약 13.5GB로, 예상치인 14GB에 근접한 것을 알 수 있습니다. 작은 차이는 반올림 오류, 바이어스 파라미터 또는 일부 파라미터가 여전히 FP32를 사용하여 저장되어 있기 때문에 발생할 수 있습니다.
© 저작권 정책
이 글은 저작권이 있으며 무단으로 복제해서는 안 됩니다.

관련 문서




댓글 없음...