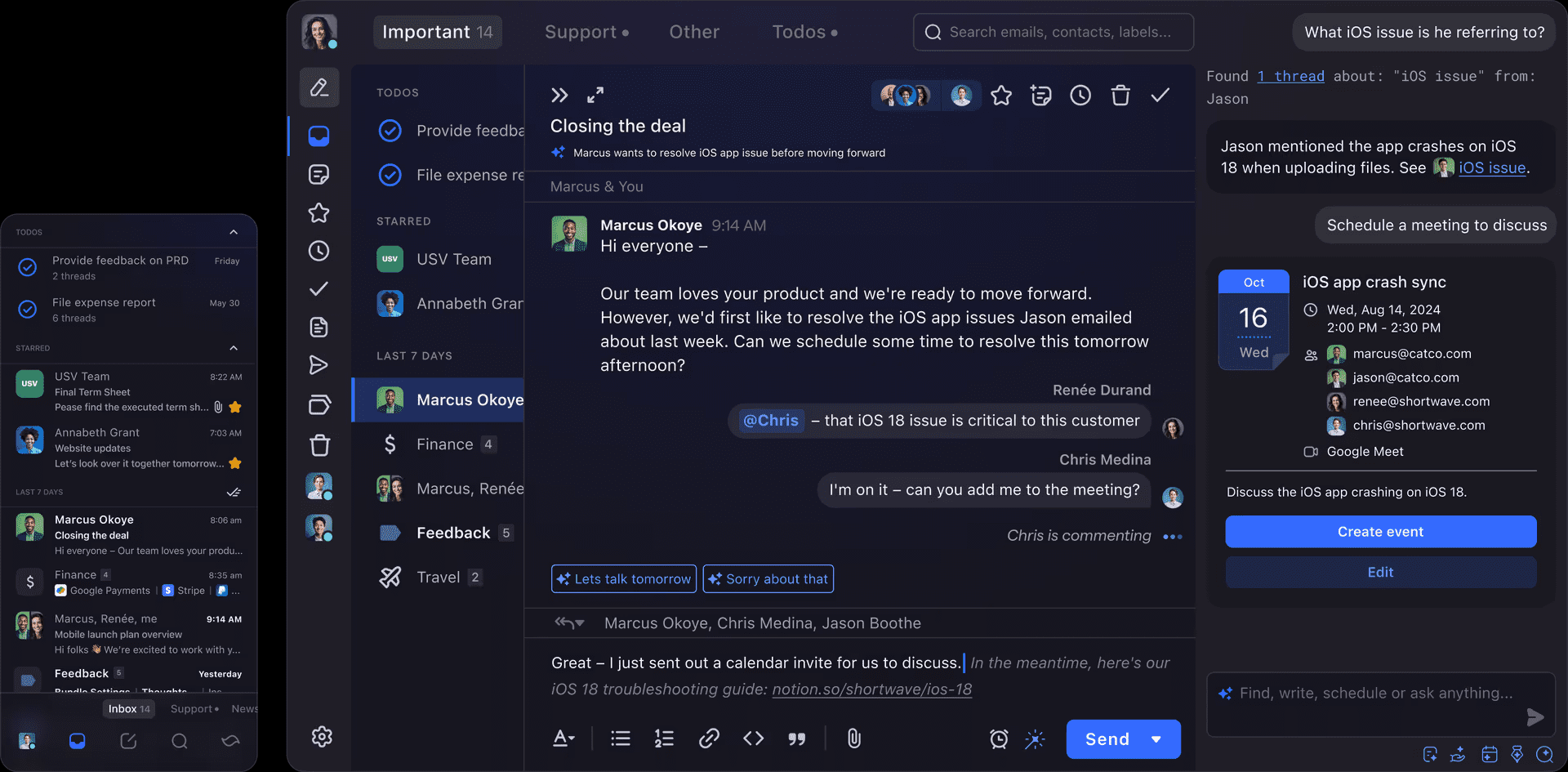
Surya: 전문 다국어 문서 OCR 도구, 오픈 소스 네이티브 배포

일반 소개
Surya는 90개 이상의 언어로 텍스트 인식을 지원하는 오픈 소스 다국어 문서 OCR 툴킷입니다. 줄 단위 텍스트 감지뿐만 아니라 레이아웃 분석, 읽기 순서 감지, 표 인식도 가능하며 PDF, 이미지, Word 문서, PPT 등 다양한 문서 유형에 대해 클라우드 기반 서비스에 필적하는 성능을 제공합니다. 이 툴킷은 사용자에게 종합적인 문서 구문 분석 솔루션을 제공하도록 설계되었습니다.
호스팅 API: https://www.datalab.to/
PDF, 이미지, Word 문서 및 PowerPoint의 경우

기능 목록
- OCR: 90개 이상의 언어 텍스트 인식
- 줄 단위 텍스트 감지: 문서에서 각 줄의 텍스트 위치를 자동으로 식별합니다.
- 레이아웃 분석: 문서의 표, 이미지, 제목 및 기타 요소 감지
- 읽기 순서 감지: 문서에서 읽기 순서 식별
- 표 인식: 표에서 행과 열 감지하기
도움말 사용
설치 프로세스
- Python 3.9+ 및 PyTorch가 설치되어 있는지 확인합니다.
- Mac 또는 GPU 머신을 사용하지 않는 경우, 먼저 CPU 버전의 토치를 설치해야 할 수 있습니다.
- 다음 명령을 사용하여 Surya를 설치합니다:
pip install surya-ocr - Surya를 처음 실행하면 모델 가중치가 자동으로 다운로드됩니다.
사용 프로세스
- 확인 및 구성
surya/settings.py환경 변수에 설정이 있는 경우 환경 변수로 모든 설정을 재정의할 수 있습니다. - Surya는 토치 장치를 자동으로 감지하지만 수동으로 재정의할 수 있습니다. 예시:
TORCH_DEVICE=cuda - 다음 명령을 사용하여 OCR 애플리케이션을 실행합니다:
python run_ocr_app.py - 문서를 처리할 때 텍스트 감지, 레이아웃 분석 등과 같은 다양한 기능 모듈 중에서 선택할 수 있습니다.
기능 작동 흐름
- OCR 기능::
- 문서(PDF, 이미지 등)를 로드합니다.
- 언어를 선택합니다(90개 이상의 언어가 지원됨).
- OCR 인식을 실행하여 텍스트 콘텐츠를 추출합니다.
- 줄 단위 텍스트 감지::
- 문서를 로드합니다.
- 줄 단위 텍스트 감지를 실행하여 각 텍스트 줄의 위치를 파악합니다.
- 테스트 결과 내보내기.
- 레이아웃 분석::
- 문서를 로드합니다.
- 레이아웃 분석을 실행하여 문서에서 표, 이미지, 제목 등의 요소를 감지합니다.
- 분석 결과를 내보냅니다.
- 읽기 시퀀스 테스트::
- 문서를 로드합니다.
- 읽기 순서 감지를 실행하여 문서에서 읽기 순서를 식별합니다.
- 테스트 결과 내보내기.
- 양식 인식::
- 문서를 로드합니다.
- 표 인식을 실행하여 표의 행과 열을 감지합니다.
- 인식 결과를 내보냅니다.
Surya는 다양한 문서 구문 분석 기능을 제공하며, 사용자는 필요에 따라 다양한 기능 모듈을 선택하여 사용할 수 있습니다. 자세한 작동 절차 및 설정 지침은 공식 문서와 샘플 코드를 참조하세요.
© 저작권 정책
이 글은 저작권이 있으며 무단으로 복제해서는 안 됩니다.

관련 문서



댓글 없음...