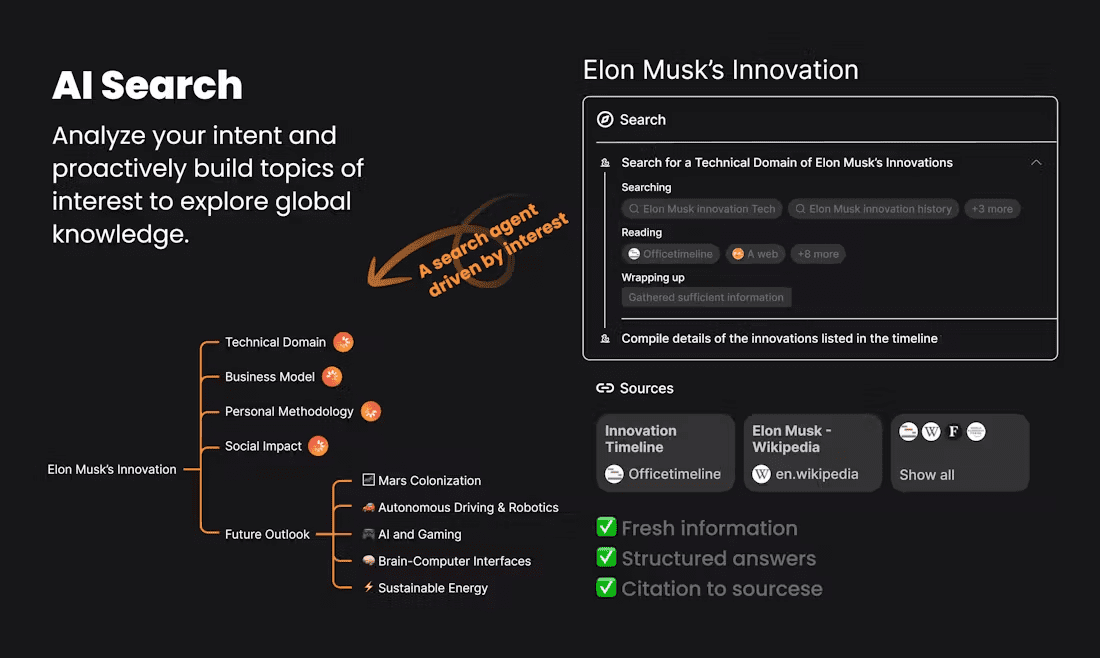
Aana SDK: uma ferramenta de código aberto para facilitar a implantação de modelos de IA multimodais

Introdução geral
O Aana SDK é uma estrutura de código aberto desenvolvida pela Mobius Labs, batizada com o nome da palavra malaiala "ആന" (elefante). Ele ajuda os desenvolvedores a implementar e gerenciar rapidamente modelos de IA multimodais que suportam o processamento de texto, imagens, áudio e vídeo, entre outros dados. O Aana SDK é baseado na estrutura de computação distribuída Ray e foi projetado para oferecer confiabilidade, escalabilidade e eficiência. Os desenvolvedores podem usá-lo para criar facilmente aplicativos, desde autônomos até agrupados, como transcrição de vídeo, descrição de imagens ou ferramentas de bate-papo inteligentes.

Lista de funções
- Suporte a dados multimodais: a capacidade de processar texto, imagens, áudio e vídeo simultaneamente.
- Implementação e dimensionamento de modelos: os modelos de aprendizado de máquina podem ser implementados em uma única máquina ou em um cluster.
- APIs geradas automaticamente: crie e valide automaticamente as APIs com base em pontos de extremidade definidos.
- Saída de streaming em tempo real: suporta resultados de streaming para aplicativos em tempo real e grandes modelos de linguagem.
- Tipos de dados predefinidos: suporte integrado para tipos de dados comuns, como imagem, vídeo, etc.
- Fila de tarefas em segundo plano: as tarefas de endpoint são executadas automaticamente em segundo plano sem configuração adicional.
- Integração de vários modelos: Whisper, vLLM, Hugging Face Transformers, etc. são suportados.
- Geração automática de documentação: gere automaticamente a documentação do aplicativo com base nos pontos de extremidade.
Usando a Ajuda
Processo de instalação
Há duas maneiras de instalar o SDK da Aana: PyPI e GitHub. Veja a seguir as etapas:
- Preparação do ambiente
- Requer Python 3.8 ou posterior.
- Recomenda-se instalar o PyTorch manualmente (>= 2.1), escolhendo a versão apropriada para seu sistema (consulte https://pytorch.org/get-started/locally/). Caso contrário, a instalação padrão poderá não tirar o máximo proveito da GPU.
- Se você estiver usando uma GPU, é recomendável instalar a biblioteca Flash Attention para melhorar o desempenho (consulte https://github.com/Dao-AILab/flash-attention).
- Instalação via PyPI
- Execute o seguinte comando para instalar as dependências do núcleo:
pip install aana - Para obter funcionalidade total, instale todas as dependências adicionais:
pip install aana[all] - Outras opções incluem
vllm(Modelagem de linguagem),asr(reconhecimento de fala),transformers(modelo de conversor), etc., conforme necessário.
- Execute o seguinte comando para instalar as dependências do núcleo:
- Instalação via GitHub
- Armazém de Clonagem:
git clone https://github.com/mobiusml/aana_sdk.git cd aana_sdk - Instale usando o Poetry (recomenda-se o Poetry >= 2.0, consulte https://python-poetry.org/docs/#installation):
poetry install --extras all - Os ambientes de desenvolvimento podem adicionar dependências de teste:
poetry install --extras all --with dev,tests
- Armazém de Clonagem:
- Verificar a instalação
- importação
python -c "import aana; print(aana.__version__)"Se o número da versão for retornado, ele será bem-sucedido.
- importação
Como usar
No centro do SDK da Aana estão as implantações e os pontos de extremidade. As implantações carregam o modelo e os pontos de extremidade definem a funcionalidade. A seguir, um exemplo de transcrição de vídeo:
- Criação de um novo aplicativo
- Nova pasta (por exemplo.
my_app), crieapp.py. - Modelos referenciáveis https://github.com/mobiusml/aana_app_template Início rápido.
- Nova pasta (por exemplo.
- Implementação da configuração
- existir
app.pyCarregamento Sussurro Modelos:from aana.sdk import AanaSDK from aana.deployments.whisper_deployment import WhisperDeployment, WhisperConfig, WhisperModelSize, WhisperComputeType app = AanaSDK(name="video_app") app.register_deployment( "whisper", WhisperDeployment.options( num_replicas=1, ray_actor_options={"num_gpus": 0.25}, # 若无GPU可删除此行 user_config=WhisperConfig( model_size=WhisperModelSize.MEDIUM, compute_type=WhisperComputeType.FLOAT16 ).model_dump(mode="json") ) )
- existir
- Definição de pontos de extremidade
- Adicionar pontos finais de transcrição:
from aana.core.models.video import VideoInput @app.aana_endpoint(name="transcribe_video") async def transcribe_video(self, video: VideoInput): audio = await self.download(video.url) # 下载并提取音频 transcription = await self.whisper.transcribe(audio) # 转录 return {"transcription": transcription}
- Adicionar pontos finais de transcrição:
- Executar o aplicativo
- É executado no terminal:
python app.py serve - ou com a CLI da Aana:
aana deploy app:app --host 127.0.0.1 --port 8000 - Quando o aplicativo é iniciado, o endereço padrão é
http://127.0.0.1:8000.
- É executado no terminal:
- função de teste
- Envia uma solicitação usando cURL:
curl -X POST http://127.0.0.1:8000/transcribe_video -F body='{"url":"https://www.youtube.com/watch?v=VhJFyyukAzA"}' - Ou visite a interface do usuário do Swagger (
http://127.0.0.1:8000/docs) Testes.
- Envia uma solicitação usando cURL:
Operação da função em destaque
- processamento multimodal
Além da transcrição da fala, os modelos de imagem (por exemplo, Blip2) podem ser integrados para gerar descrições:captions = await self.blip2.generate_captions(video.frames)
- saída de streaming
Oferece suporte ao retorno de resultados em tempo real, por exemplo:@app.aana_endpoint(name="chat", streaming=True) async def chat(self, question: str): async for chunk in self.llm.generate_stream(question): yield chunk - Extensão do cluster
Para implementar com um cluster Ray, modifique oapp.connect()Basta especificar o endereço do cluster.
Ferramentas adicionais
- Painel de controle do RayAcesso pós-corrida
http://127.0.0.1:8265Visualize o status e os registros do cluster. - Implementação do Docker: Consulte https://mobiusml.github.io/aana_sdk/pages/docker/.
cenário do aplicativo
- Agrupamento de conteúdo de vídeo
Gerar legendas e resumos para vídeos instrucionais para facilitar o arquivamento e a pesquisa. - Sistema inteligente de perguntas e respostas (Q&A)
O usuário faz upload de um vídeo e, em seguida, faz uma pergunta, e o sistema responde com base no conteúdo de áudio e vídeo. - Análise de dados corporativos
Extraia informações importantes de gravações de reuniões e vídeos para gerar relatórios.
QA
- Precisa de uma GPU?
Não é obrigatório; a CPU também pode executá-lo, mas a GPU (recomenda-se 40 GB de RAM) aumentará significativamente a eficiência. - Como faço para lidar com erros de instalação?
Verifique se há correspondências de versão e dependência do Python adicionando o parâmetro--log-level DEBUGVeja os registros detalhados. - Quais modelos de idioma são compatíveis?
vLLM, Whisper, etc. incorporados para maior integração do modelo Hugging Face por meio de Transformers.
© declaração de direitos autorais
O artigo é protegido por direitos autorais e não deve ser reproduzido sem permissão.

Publicações relacionadas


Nenhum comentário...