
O mini modelo de código aberto de 1,6 B "Little Fox" supera os modelos similares Qwen e Gemma


desde (uma época) Chatgpt Desde sua criação, o número de parâmetros de LLM (Large Language Models) parece ser uma corrida para o fundo do poço para cada empresa. A contagem de parâmetros do GPT-1 era de 117 milhões (117M), e sua quarta geração, a contagem de parâmetros do GPT-4, foi atualizada para 1,8 trilhão (1800B).
Assim como outros modelos LLM, como o Bloom (176 bilhões, 176B) e o Chinchilla (70 bilhões, 70B), o número de parâmetros também está aumentando. O número de parâmetros afeta diretamente o desempenho e a capacidade do modelo, com mais parâmetros significando que o modelo é capaz de lidar com padrões de linguagem mais complexos, entender informações contextuais mais ricas e exibir níveis mais altos de inteligência em uma ampla gama de tarefas.
No entanto, esses parâmetros enormes também afetam diretamente o custo de treinamento e o ambiente de desenvolvimento dos LLMs e limitam a exploração dos LLMs pela maioria das empresas de pesquisa em geral, o que faz com que os modelos de linguagem grandes se tornem gradualmente uma corrida armamentista entre as grandes empresas.
Recentemente, a TensorOpera, empresa emergente de IA, lançou oModelos de idiomas pequenos de código aberto FOXprovando ao setor que os Small Language Models (SLMs) também podem mostrar força suficiente no campo da inteligência.

A FOX é umaModelos de linguagem pequena projetados para computação em nuvem e de borda. Ao contrário dos grandes modelos de linguagem com dezenas de bilhões de parâmetros, o FOX Apenas 1,6 bilhão de parâmetrosÉ uma ótima maneira de obter o máximo de seu computador, mas também é uma ótima maneira de mostrar um desempenho incrível em várias tarefas.
Título da tese:
RELATÓRIO TÉCNICO FOX-1
Link para o artigo:
https://arxiv.org/abs/2411.05281

Quem é a TensorOpera?
A TensorOpera é uma empresa inovadora de inteligência artificial sediada no Vale do Silício, Califórnia. Anteriormente, a empresa desenvolveu o ecossistema de IA generativa TensorOpera® AI Platform e a plataforma de análise e aprendizado federal TensorOpera® FedML. O nome da empresa, TensorOpera, é uma combinação de tecnologia e arte, simbolizando o eventual desenvolvimento da GenAI de sistemas de IA compostos multimodais e multimodais.

O Dr. Jared Kaplan, cofundador e CEO da TensorOpera, disse: "O modelo FOX foi originalmente projetado para reduzir significativamente os requisitos de recursos de computação, mantendo o alto desempenho. Isso não apenas torna a tecnologia de IA mais acessível, mas também reduz a barreira de uso para as empresas."
Como funciona o modelo da Fox?
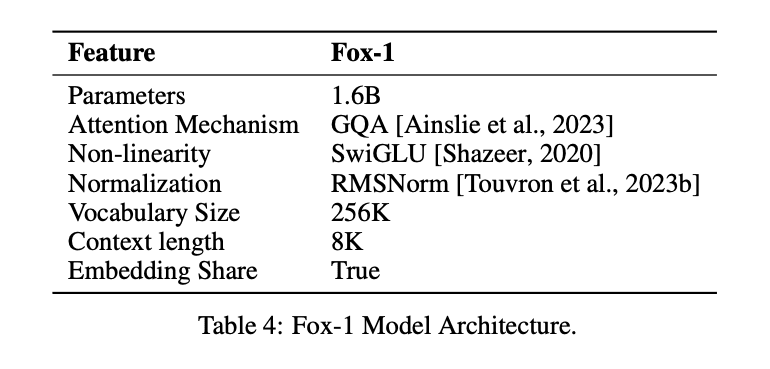
Para obter o mesmo efeito que o LLM com um número menor de parâmetros, o modelo Fox-1Somente decodificadore apresenta vários aprimoramentos e redesenhos para melhorar o desempenho. Isso inclui
① camada de redeNo projeto de arquiteturas de modelos, as redes neurais mais largas e mais rasas têm melhores recursos de memória, enquanto as redes mais profundas e mais enxutas apresentam recursos de inferência mais fortes. Seguindo esse princípio, o Fox-1 usa uma arquitetura mais profunda do que a maioria dos SLMs modernos. Especificamente, o Fox-1 consiste em 32 camadas autoatentivas, o que é 781 TP3T mais profundo que o Gemma-2B (18 camadas) e 331 TP3T mais profundo que o StableLM-2-1.6B (24 camadas) e o Qwen1.5-1.8B (24 camadas).
② Incorporação compartilhadaFox-1 usa 2.048 dimensões ocultas para criar um total de 256.000 vocabulários com cerca de 500 milhões de parâmetros. Modelos maiores geralmente usam camadas de incorporação separadas para a camada de entrada (vocabulário para expressões incorporadas) e a camada de saída (expressões incorporadas para vocabulário). Para o Fox-1, somente a camada de incorporação requer 1 bilhão de parâmetros. Para reduzir o número total de parâmetros, o compartilhamento das camadas de incorporação de entrada e saída maximiza a utilização do peso.
(iii) pré-normalizaçãoFox-1 usa o RMSNorm para normalizar as entradas de cada camada de transformação; o RMSNorm é a opção preferida para pré-normalização em modelos modernos de linguagem em grande escala e apresenta melhor eficiência do que o LayerNorm.
④ Codificação de posição rotativa (RoPE)Fox-1 aceita tokens de entrada de até 8K de comprimento por padrão e, para melhorar o desempenho em janelas de contexto mais longas, o Fox-1 usa codificação posicional rotacionada, em que θ é definido como 10.000 para codificação token Dependência posicional relativa entre
⑤ Atenção à consulta em grupo (GQA)O Fox-1 é equipado com 4 cabeças de valor-chave e 16 cabeças de atenção para aumentar a velocidade de treinamento e inferência e reduzir o uso da memória.
Além de modelar melhorias estruturais.O FOX-1 também melhora a tokenização e o treinamento..
a parte do discurso (na gramática chinesa)O Fox-1 usa o classificador Gemma baseado em SentencePiece, que fornece um tamanho de vocabulário de 256K. O aumento do tamanho do vocabulário tem pelo menos duas vantagens principais. Primeiro, o comprimento das informações ocultas no contexto é ampliado porque cada token codifica informações mais densas. Por exemplo, um vocabulário de tamanho 26 pode codificar apenas um caractere em [a-z], mas um vocabulário de tamanho 262 pode codificar duas letras ao mesmo tempo, possibilitando a representação de cadeias mais longas em um token de comprimento fixo. Em segundo lugar, um vocabulário maior reduz a probabilidade de palavras ou frases desconhecidas, o que leva a um melhor desempenho da tarefa downstream na prática. O vocabulário grande usado pelo Fox-1 produz menos tokens para um determinado corpus de texto, o que gera um melhor desempenho de inferência.
Fox-1Dados de pré-treinamentoObtido dos conjuntos de dados Redpajama, SlimPajama, Dolma, Pile e Falcon, totalizando 3 trilhões de dados de texto. Para aliviar a ineficiência do pré-treinamento de sequências longas devido ao seu mecanismo de atenção, o Fox-1 introduz na fase de pré-treinamento umUma estratégia de aprendizado de currículo em três fasesO Fox-1 é um pipeline de pré-treinamento de curso de três fases, no qual o comprimento do bloco das amostras de treinamento é gradualmente aumentado de 2K para 8K para garantir recursos contextuais longos a um custo pequeno. Para ser consistente com o pipeline de pré-treinamento de curso de três fases, o Fox-1 reorganiza os dados brutos em três conjuntos diferentes, incluindo conjuntos de dados não supervisionados e de ajuste de instruções, bem como dados de diferentes domínios, como código, conteúdo da Web, documentos matemáticos e científicos.
O treinamento do Fox-1 pode ser dividido em três etapas.
- A primeira fase consiste em cerca de 39% de amostras de dados totais em todo o processo de pré-treinamento, em que o conjunto de dados de 1,05 trilhão de tokens é particionado em amostras de 2.000 de comprimento, com um tamanho de lote de 2 M. Um aquecimento linear de 2.000epoch é usado nessa fase.
- A segunda fase inclui cerca de 591 amostrasTP3T com 1,58 trilhão de tokens e aumenta o comprimento do bloco de 2K para 4K e 8K. O comprimento real do bloco varia de acordo com as diferentes fontes de dados. Considerando que a segunda fase é a mais demorada e envolve fontes diferentes de conjuntos de dados diferentes, o tamanho do lote também é aumentado para 4 milhões para melhorar a eficiência do treinamento.
- Por fim, na terceira fase, o modelo Fox é treinado usando 6,2 bilhões de tokens (cerca de 0,02% do total) de dados de alta qualidade, estabelecendo a base para diferentes recursos de tarefas posteriores, como seguir comandos, conversa fiada, perguntas e respostas específicas do domínio e assim por diante.
Qual foi o desempenho da Fox-1?
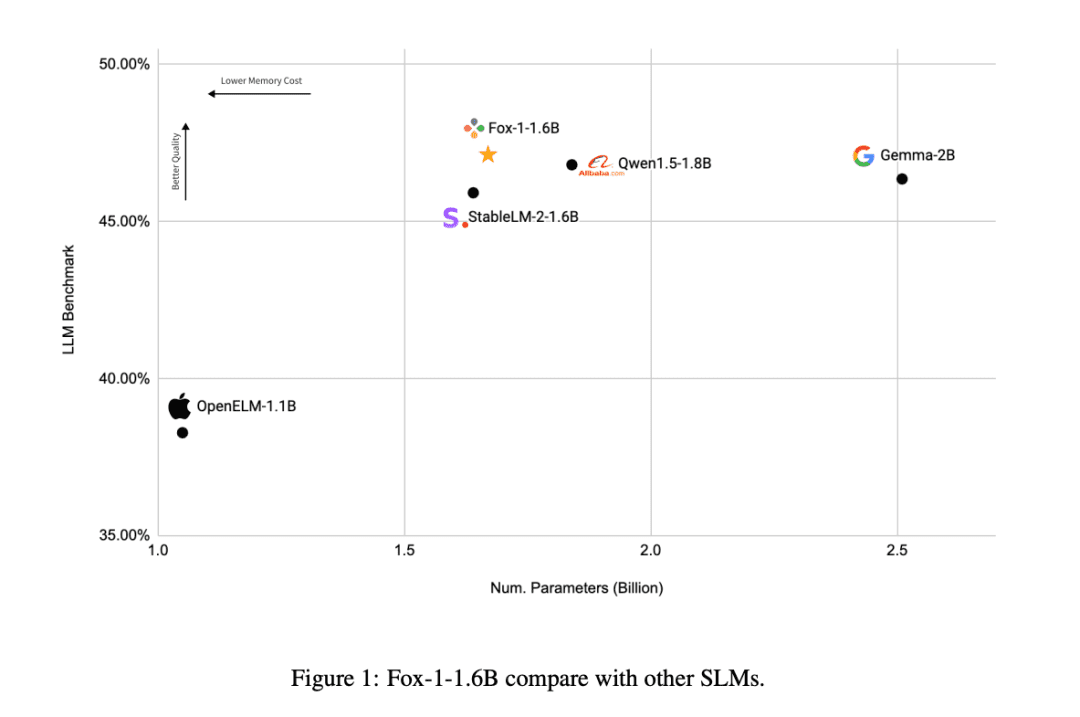
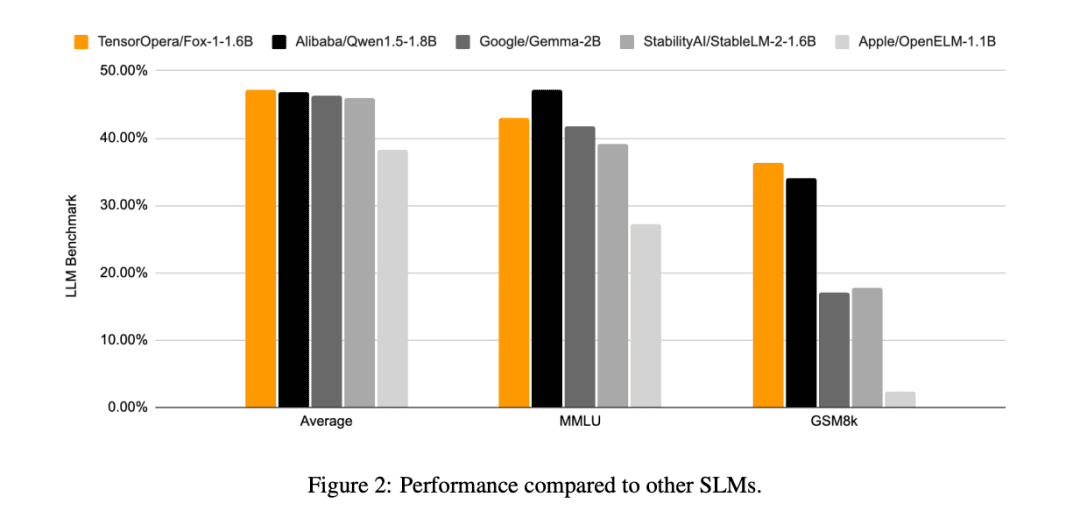
Em comparação com os outros modelos SLM (Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B e OpenELM1.1B), o FOX-1 é mais bem-sucedido no ARC Challenge (25 disparos), HellaSwag (10 disparos), TruthfulQA (0 disparos), MMLU (5 disparos), Winogrande (5 disparos), GSM8k (5 disparos), GSM8k (5 disparos), GSM8k (5 disparos) e GSM8k (5 disparos). MMLU (5 disparos), Winogrande (5 disparos), GSM8k (5 disparos)As pontuações médias do benchmark para as seis tarefas foram as mais altas e significativamente melhores no GSM8k.
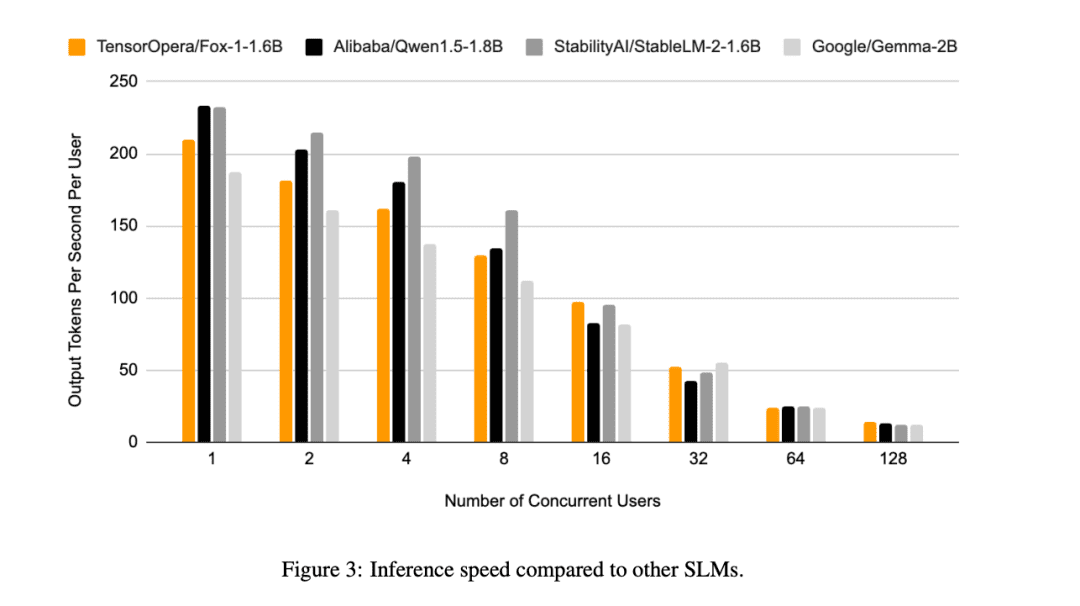
Além disso, o TensorOpera avaliou o Fox-1, o Qwen1.5-1.8B e o Gemma-2B usando o vLLM Eficiência de inferência de ponta a ponta com a plataforma de serviço TensorOpera em uma única NVIDIA H100.
O Fox-1 alcança uma taxa de transferência de mais de 200 tokens por segundo, superando o Gemma-2B e combinando com o Qwen1.5-1.8B no mesmo ambiente de implementação. Na precisão BF16, o Fox-1 requer apenas 3703 MiB de memória de GPU, enquanto o Qwen1.5-1.8B, o StableLM-2-1.6B e o Gemma-2B requerem 4739 MiB, 3852 MiB e 5379 MiB, respectivamente.
Parâmetros pequenos, mas ainda competitivos
Embora todas as empresas de IA estejam agora competindo em modelos de linguagem de grande porte, a TensorOpera adotou uma abordagem diferente, inovando no domínio do SLM, obtendo resultados semelhantes aos do LLM com apenas 1,6B e apresentando bom desempenho em vários benchmarks.
Mesmo com recursos de dados limitados, o TensorOpera pode pré-treinar modelos de linguagem com desempenho competitivo, oferecendo uma nova maneira de pensar para outras empresas de IA desenvolverem.
© declaração de direitos autorais
O artigo é protegido por direitos autorais e não deve ser reproduzido sem permissão.

Artigos relacionados



Nenhum comentário...