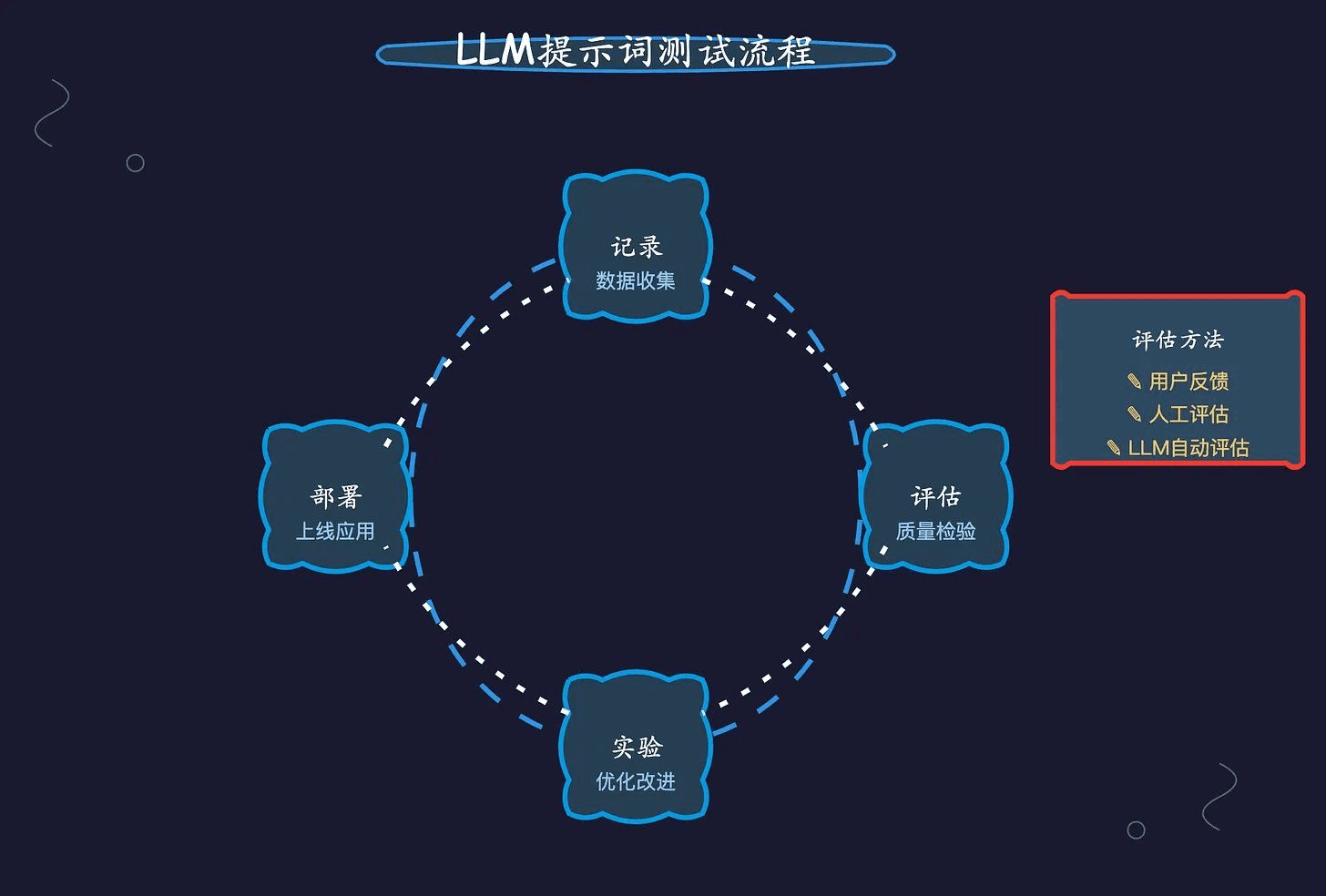
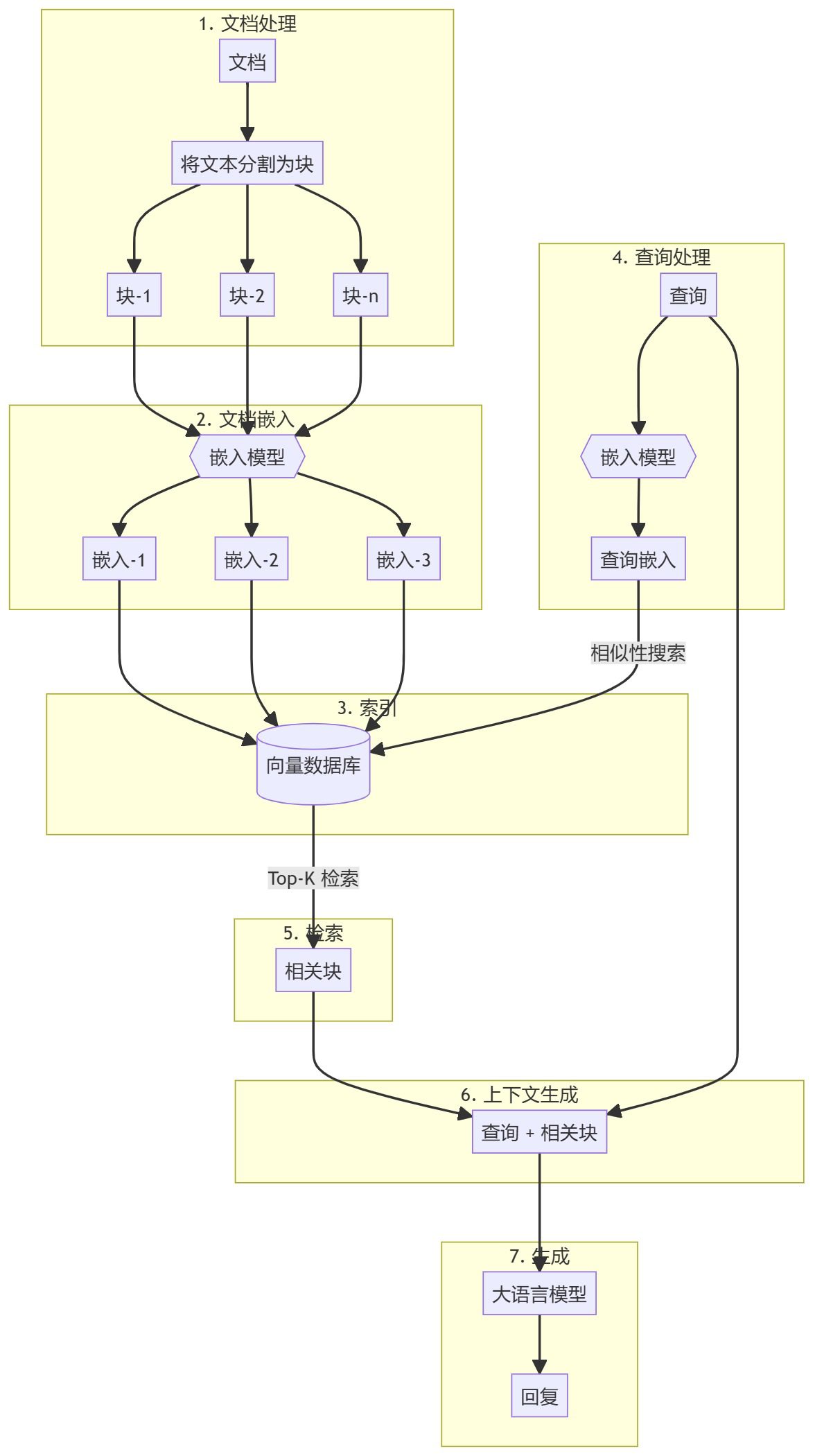
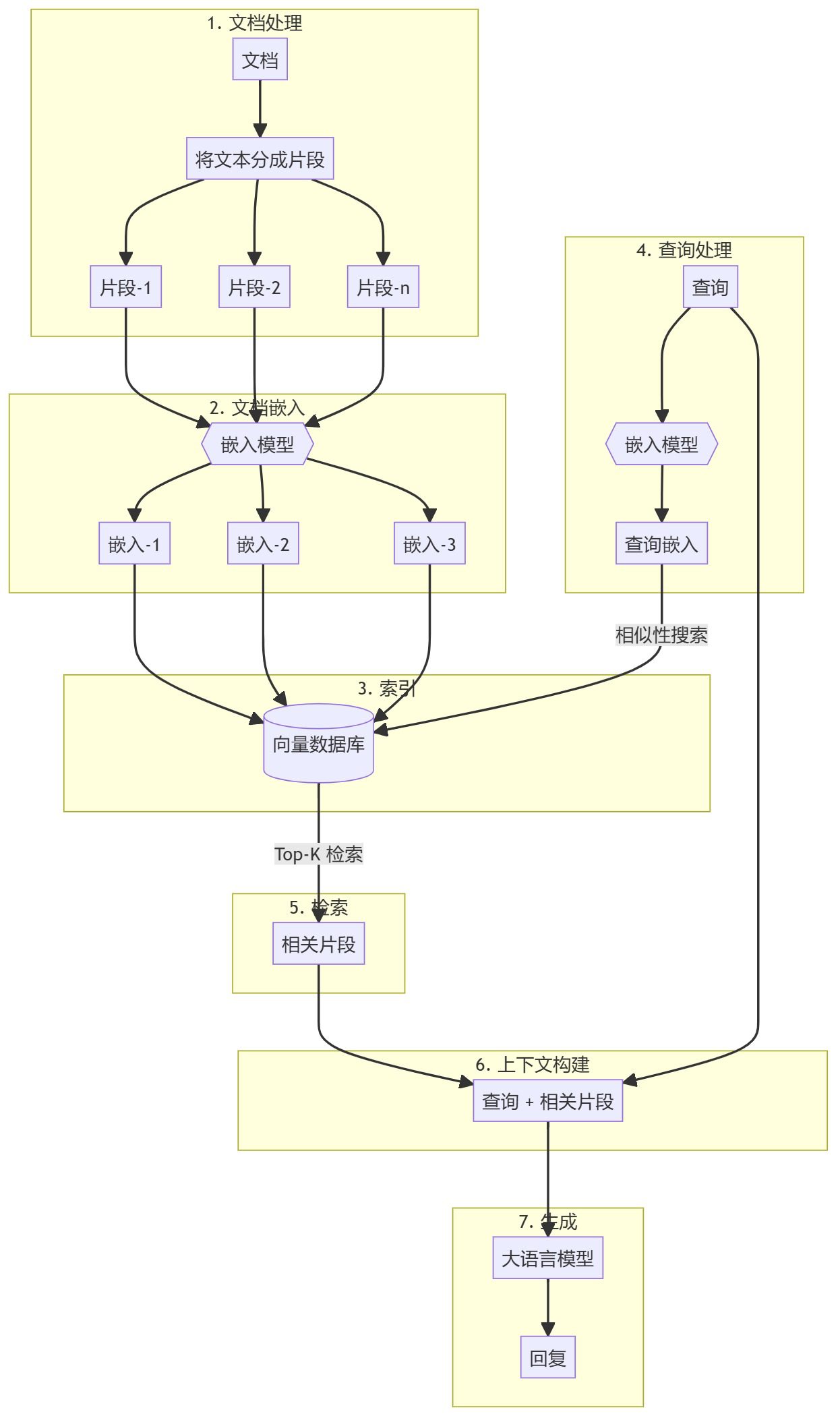
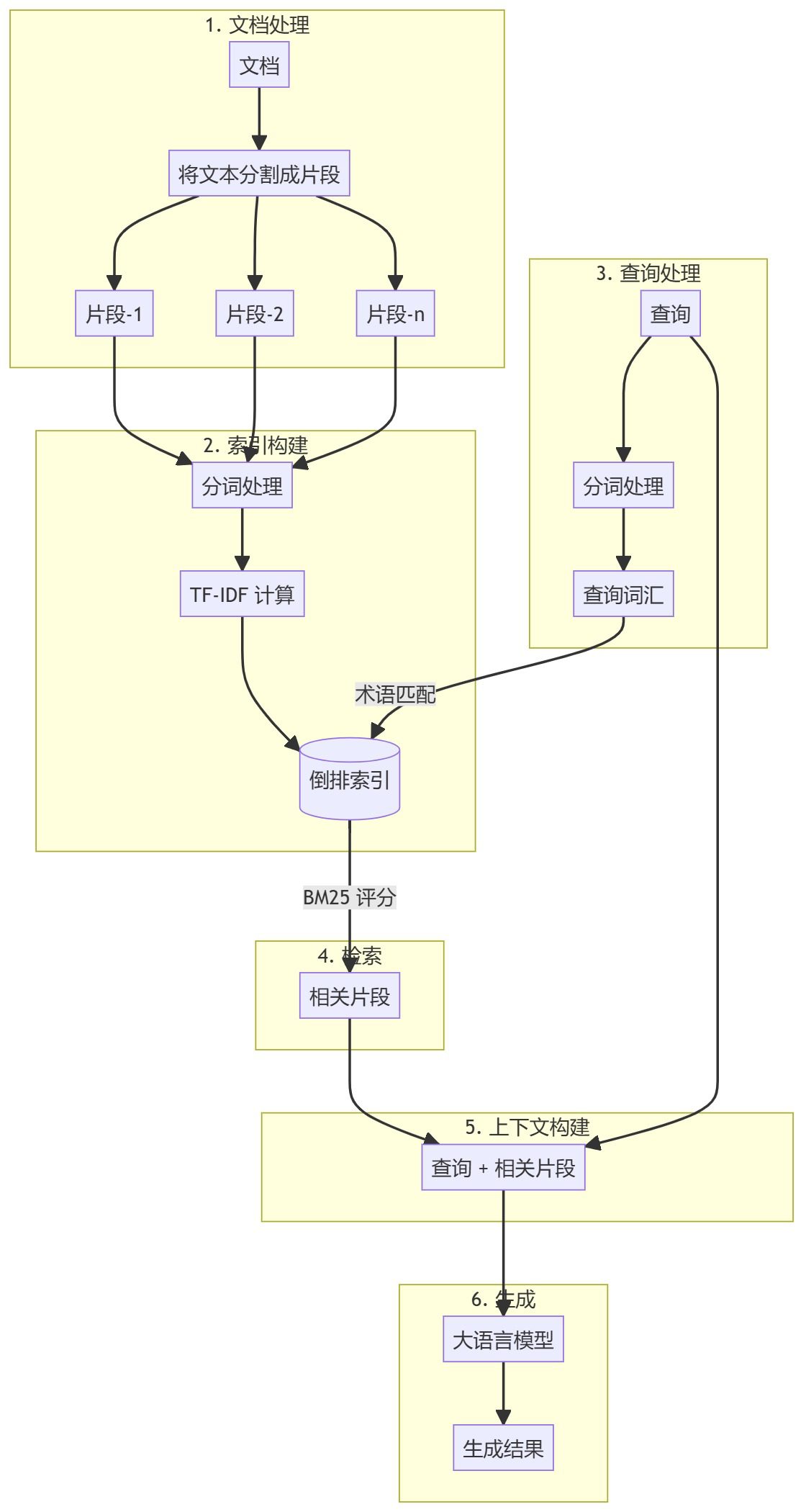
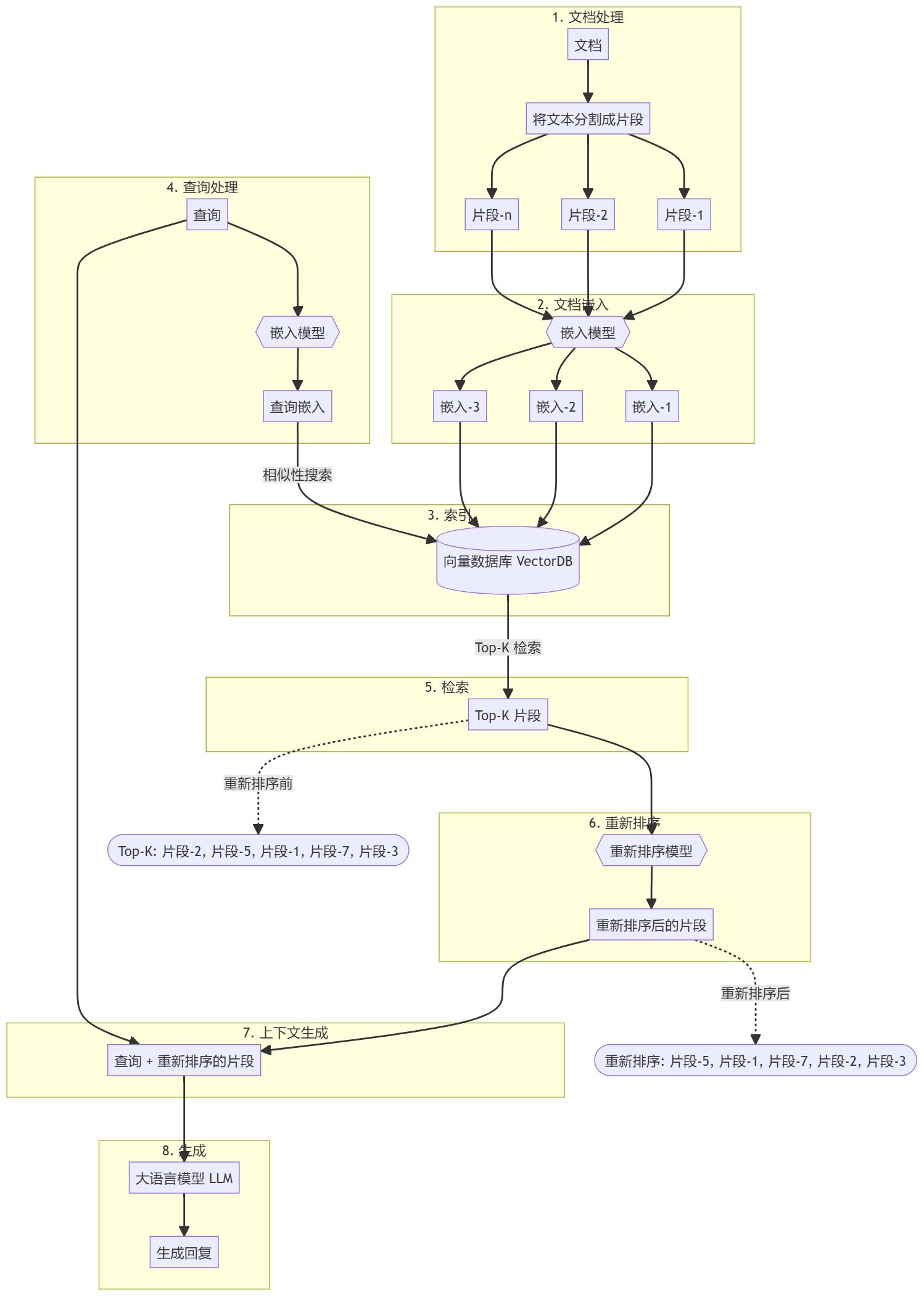
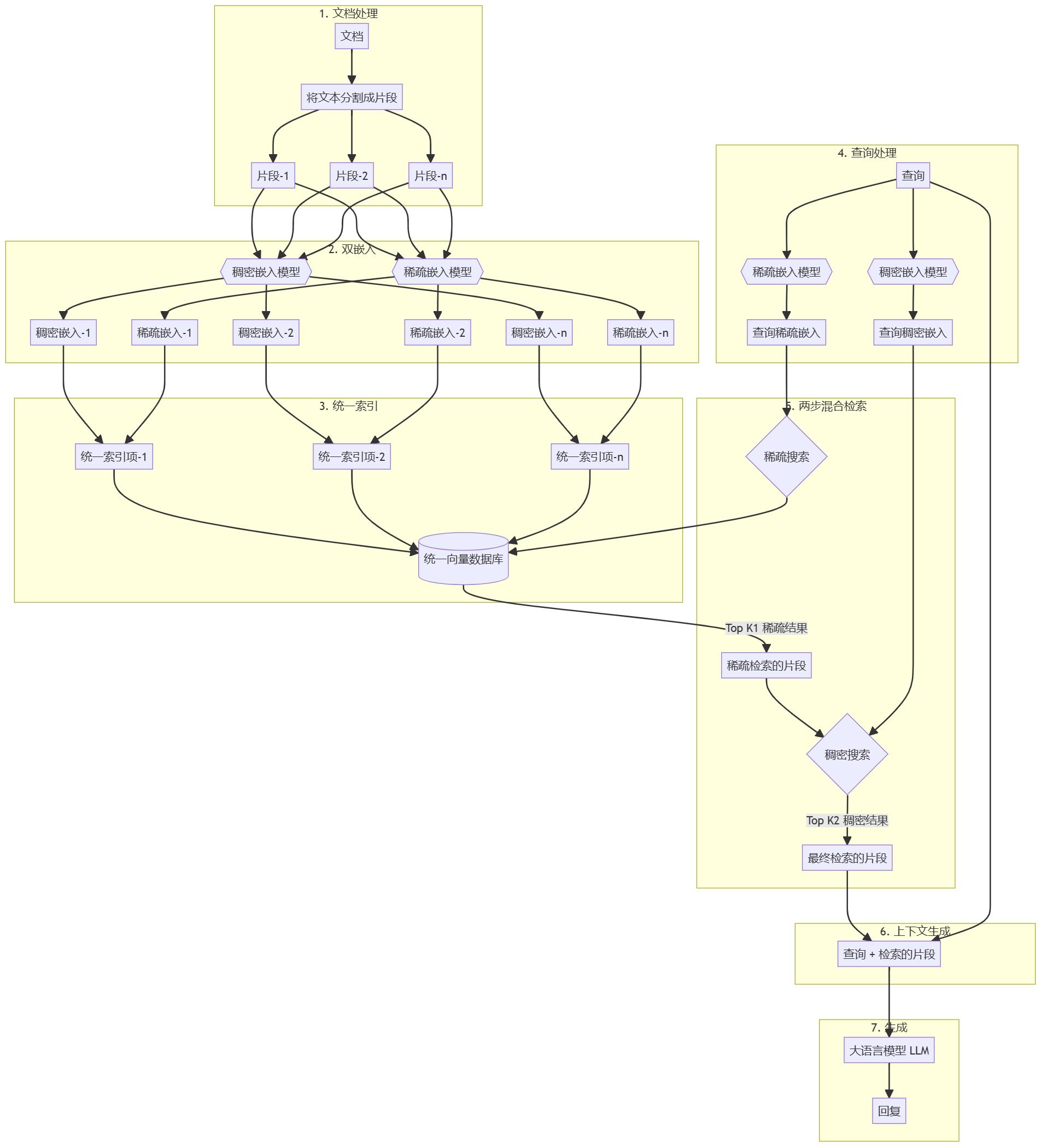
Visão geral Este guia o orientará na criação de um sistema RAG (Retrieval Augmented Generation) simples usando Python puro. Usaremos um modelo de incorporação e um modelo de linguagem grande (LLM) para recuperar documentos relevantes e gerar respostas com base nas consultas do usuário. https...
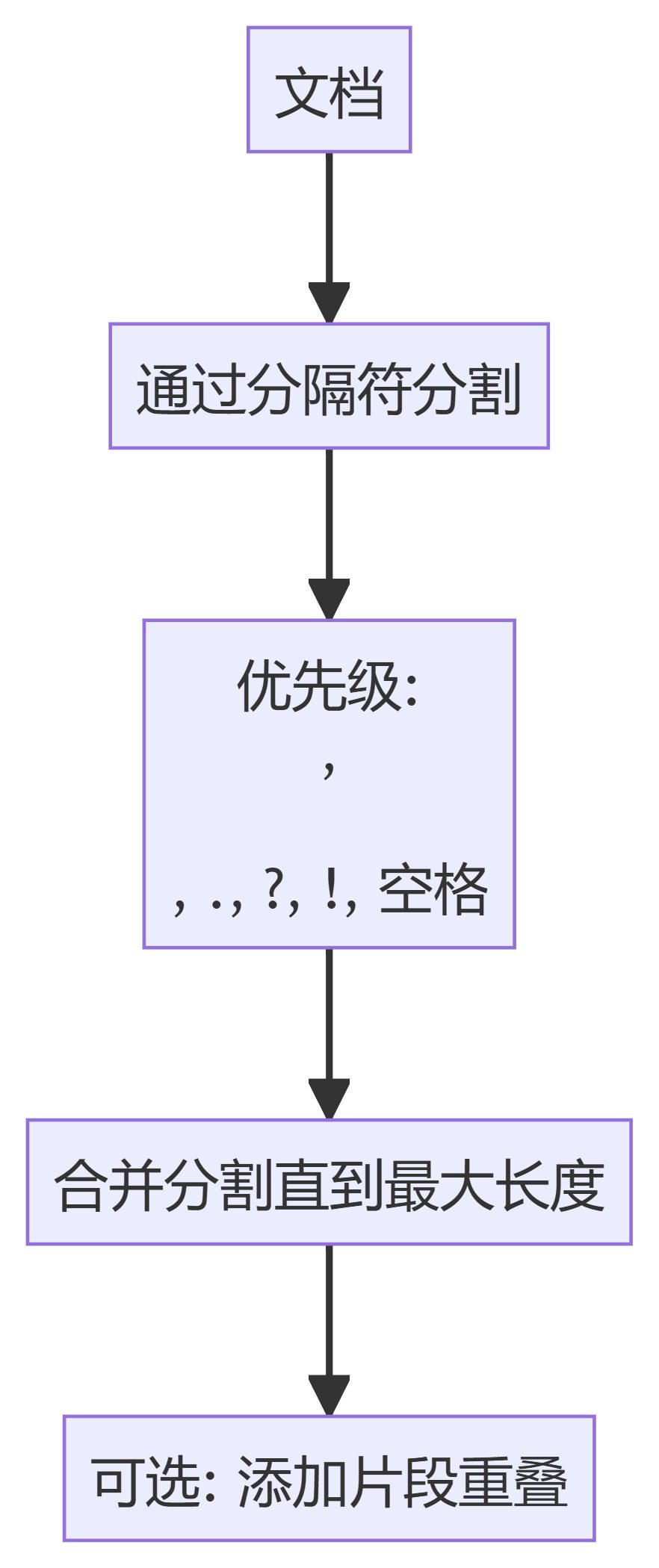
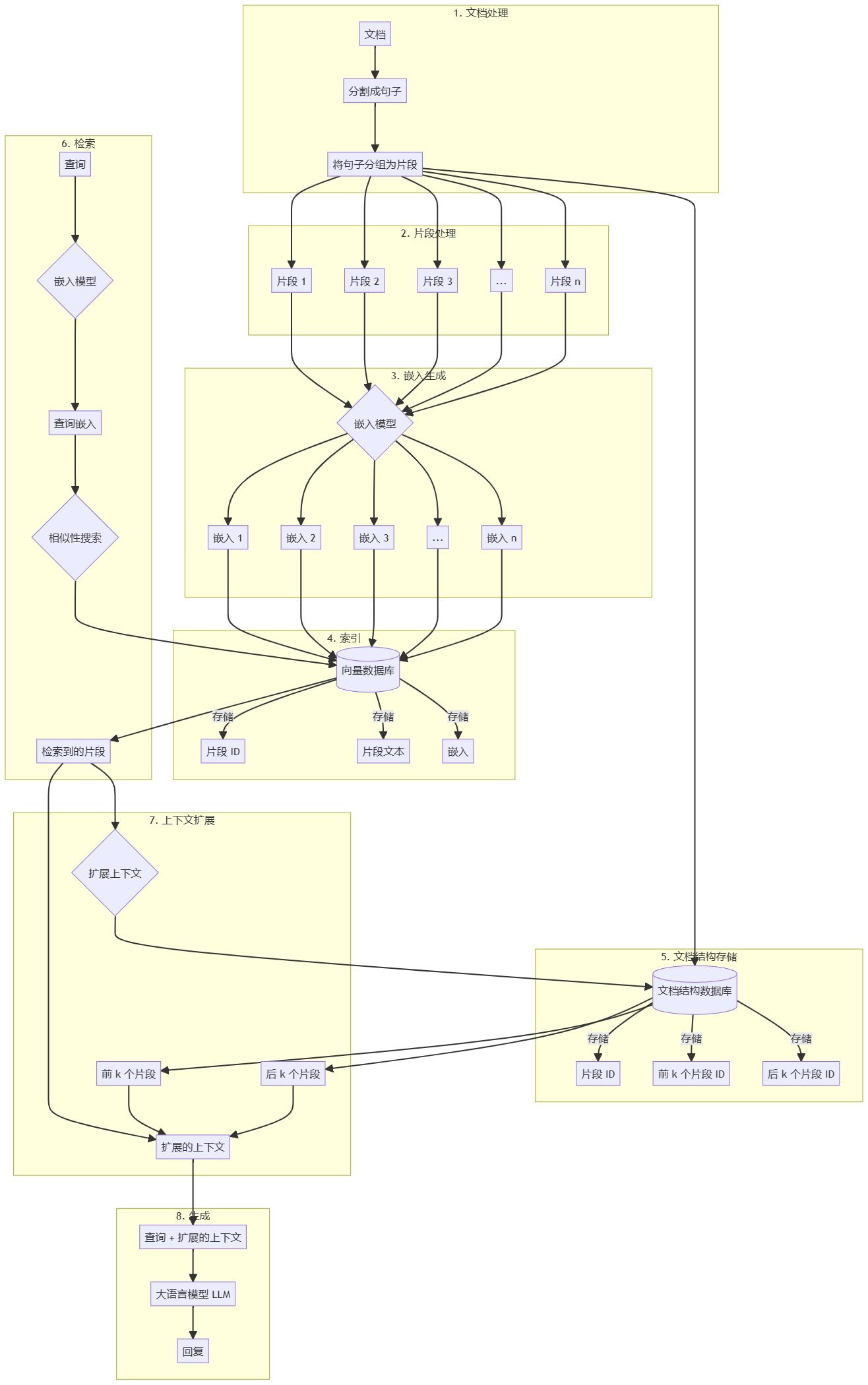
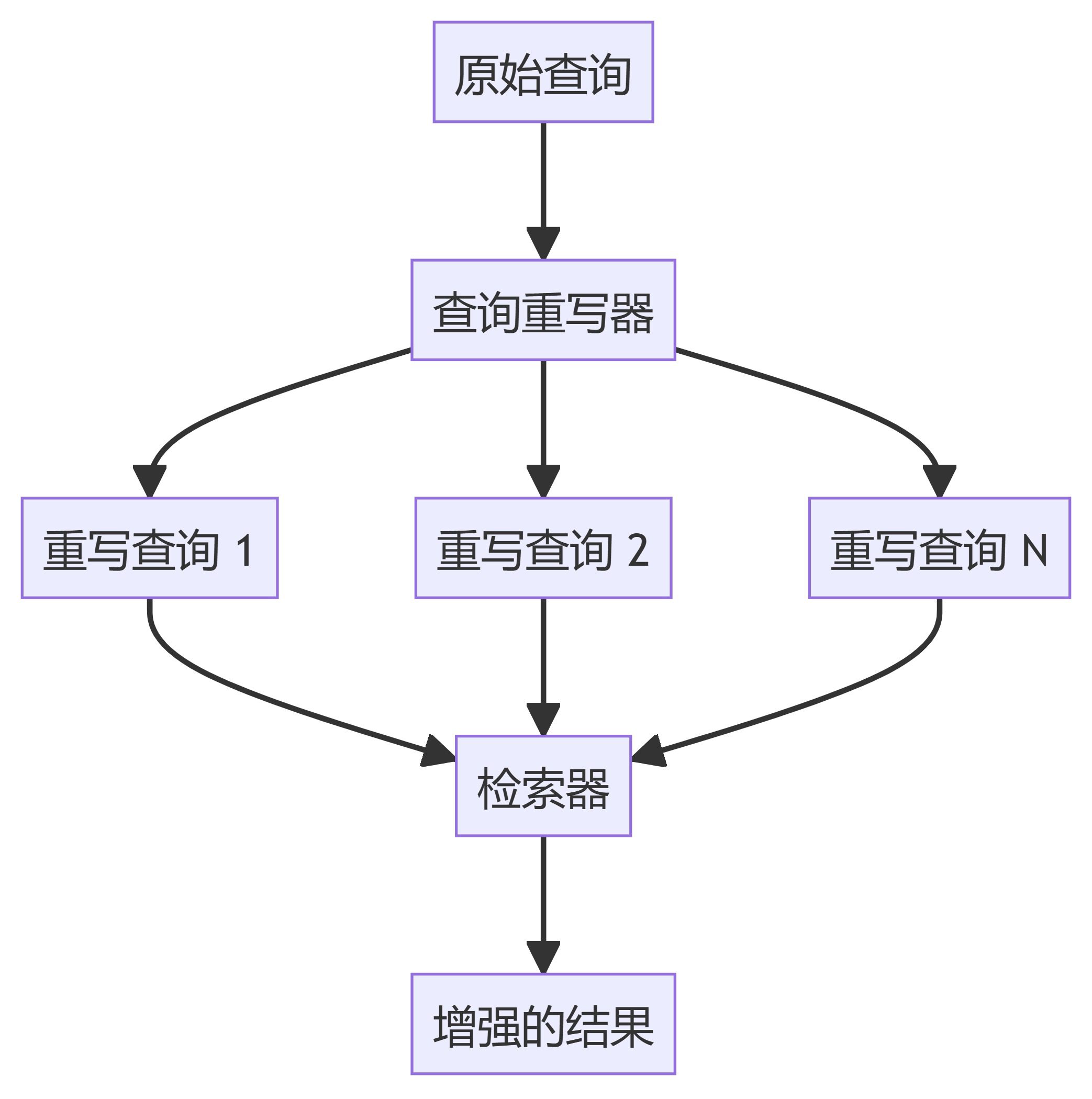
Introdução A fragmentação de dados é uma etapa fundamental dos sistemas RAG (Retrieval Augmented Generation). Ele divide documentos grandes em partes menores e gerenciáveis para indexação, recuperação e processamento eficientes. Este LEIAME apresenta uma visão geral dos vários métodos de fragmentação disponíveis no pipeline do RAG. https...
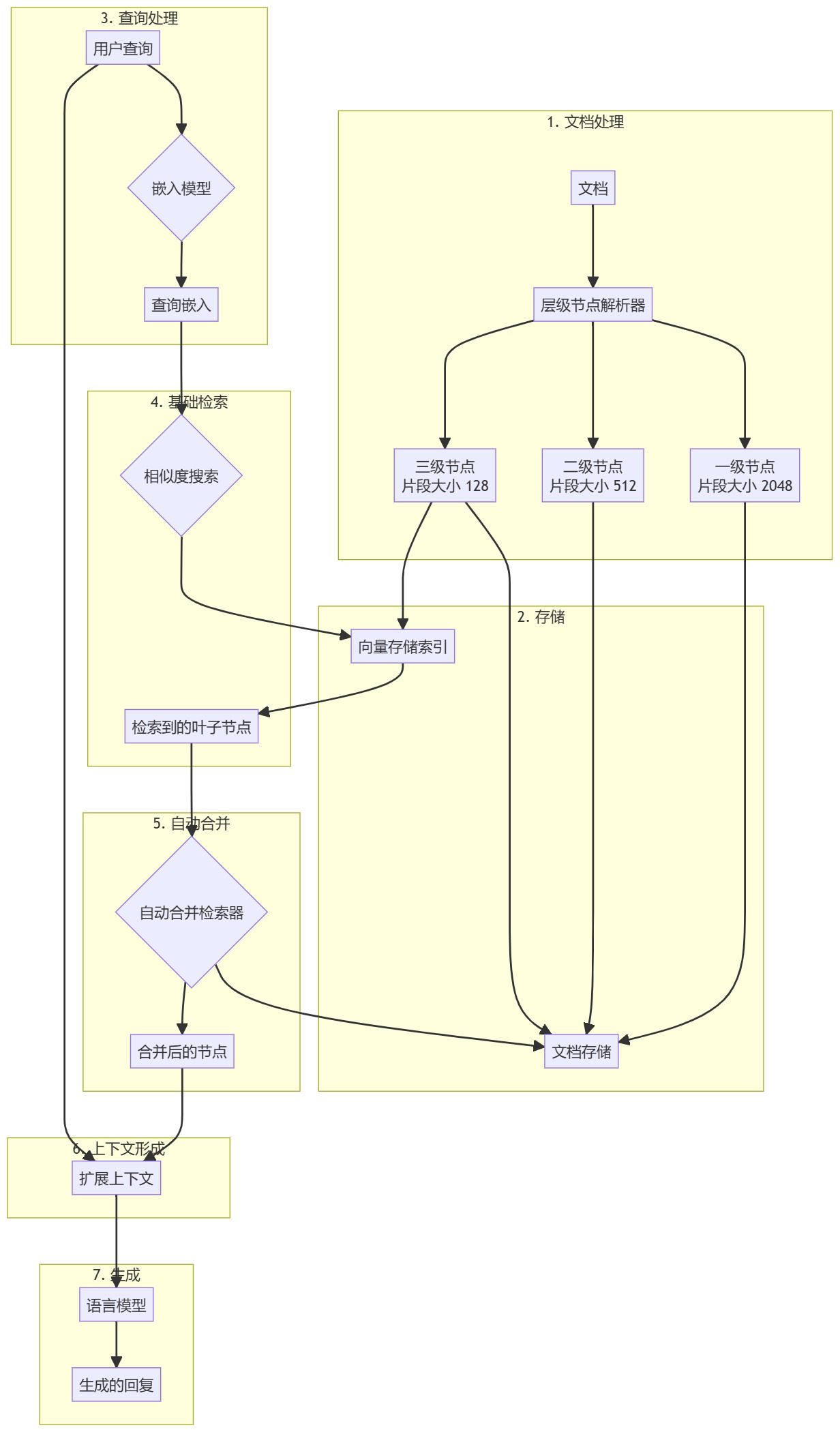
Bem-vindo a este notebook, onde exploraremos como configurar e observar o pipeline Retrieval Augmented Generation (RAG) usando o Llama Index. https://github.com/adithya-s-k/AI-Engineeri...
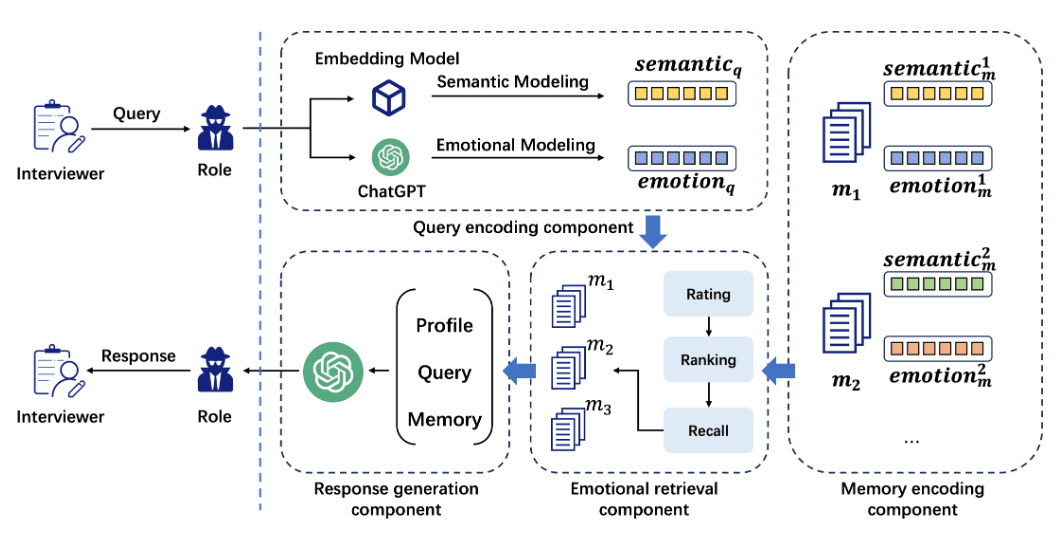
Resumo O campo de pesquisa de interpretação de papéis para gerar respostas semelhantes às humanas tem atraído cada vez mais atenção, pois os modelos de linguagem grande (LLMs) têm demonstrado um alto grau de recursos semelhantes aos humanos. Isso facilitou a exploração de agentes de interpretação de papéis em uma variedade de aplicações, como chatbots que podem se envolver em diálogos naturais com os usuários e aqueles que podem fornecer ...
O modelo de reordenação melhorará os resultados da classificação semântica ao reordenar a lista de documentos candidatos com base na correspondência semântica com a pergunta do usuário. Comumente usado o bge-reranker-v2-m3 ou o cohere
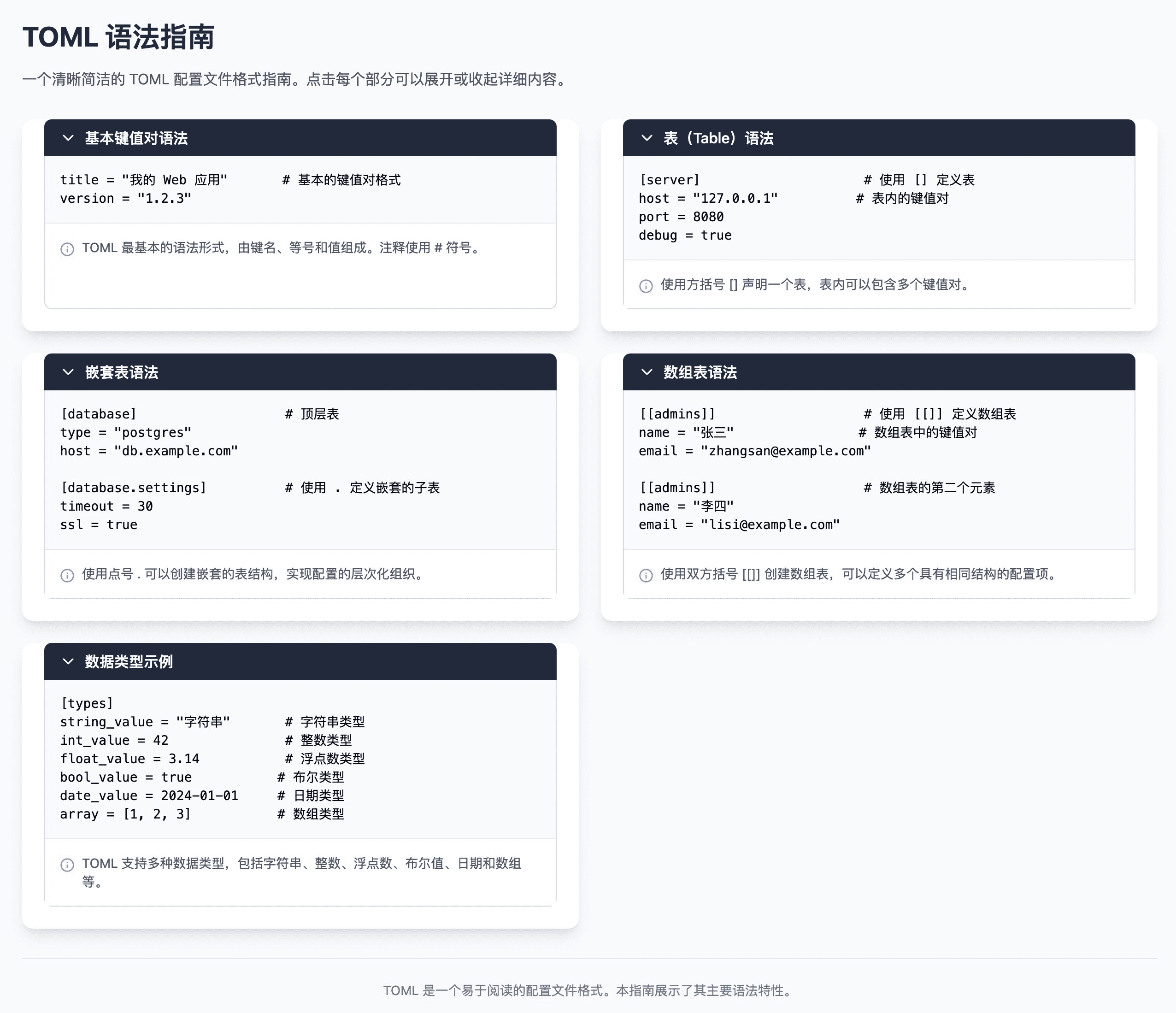
O TOML é um formato de arquivo de configuração simples e limpo 📄 projetado para ser mais legível e gravável por humanos ✨. ✅ Mais fácil de escrever: as configurações são representadas como pares de valores-chave sem regras complexas de indentação e sintaxe, reduzindo a taxa de erros. Mais claro: suporta agrupamento [grupo] e estrutura de aninhamento, camada...