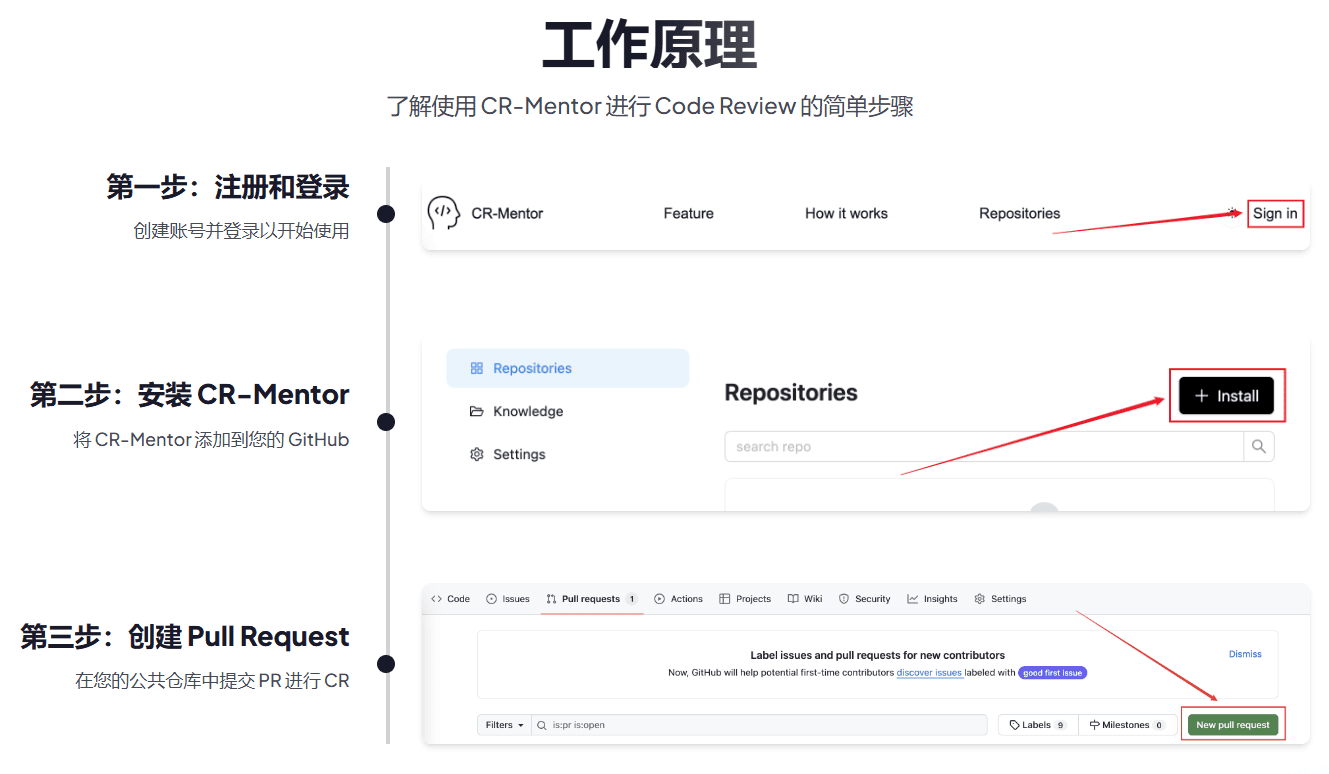
Markdownify MCP Server: converte vários conteúdos no formato Markdown com base no protocolo MCP.

Introdução geral
Markdownify MCP Server é uma ferramenta de código aberto baseada no Model Context Protocol, hospedada no GitHub e criada pelo desenvolvedor Zach Caceres. Seu foco é converter rapidamente uma ampla variedade de tipos de arquivos (por exemplo, PDFs, imagens, áudio, documentos de escritório etc.), bem como conteúdo da Web em um formato Markdown limpo. Essa ferramenta é especialmente adequada para usuários que precisam organizar informações complexas, gerar documentos ou extrair conteúdo, como desenvolvedores, criadores de conteúdo ou analistas de dados. Com etapas simples de configuração e execução, os usuários podem unificar informações díspares em arquivos Markdown fáceis de ler, aumentando a produtividade. O projeto aceita contribuições da comunidade, e o código é transparente e facilmente extensível para personalização adicional por entusiastas da tecnologia.

Lista de funções
- Conversão de tipo de documentoConverta PDF, Word, Excel e outros documentos de escritório em Markdown.
- Extração de texto de imagemExtrai texto de imagens e o converte em Markdown usando a tecnologia OCR.
- transcrição de áudioTranscrição de arquivos de áudio para texto e saída para o formato Markdown.
- Extração de conteúdo da WebMarkdown: captura o texto de uma página da Web a partir de um URL especificado e o converte em Markdown.
- Suporte a vários formatosCompatível com a conversão de tabelas, slides (PPT) e muitos outros formatos complexos.
- operação de linha de comandoInterface de linha de comando: fornece uma interface de linha de comando simples para processamento de arquivos em lote.
- escalabilidadeBaseado no protocolo MCP, ele oferece suporte a ferramentas e funções definidas pelo usuário.
Usando a Ajuda
Processo de instalação
Para usar o Markdownify MCP Server, você precisa configurar o ambiente localmente. Veja a seguir as etapas detalhadas de instalação:
- armazém de clones
- Abra um terminal e digite o seguinte comando para clonar o projeto localmente:
git clone https://github.com/zcaceres/markdownify-mcp.git - Vá para o catálogo de projetos:
cd markdownify-mcp
- Abra um terminal e digite o seguinte comando para clonar o projeto localmente:
- Instalação de dependências
- O projeto é baseado no desenvolvimento do Node.js, portanto, você precisa ter certeza de que o Node.js está instalado localmente (a versão recomendada é a LTS).
- Execute-o no diretório do projeto:
npm install - Isso instalará todos os pacotes de dependência necessários, como
uv(para processamento genérico), etc. Se for solicitada uma ferramenta específica ausente (por exemplouv), você precisa instalar e configurar manualmente a variável de ambienteUV_PATHPor exemplo:export UV_PATH="/path/to/uv"
- Construir e executar
- Construir projeto:
npm run build - Inicie o servidor:
npm start - Ou simplesmente execute-o com o comando completo (de acordo com o arquivo de configuração):
node dist/index.js - Uma vez iniciado, o servidor escuta na porta local e aguarda a entrada de um arquivo ou URL.
- Construir projeto:
Como usar os principais recursos
1. converter arquivos locais em Markdown
- procedimento::
- Prepare os arquivos a serem convertidos (por exemplo
example.pdfeimage.jpgtalvezaudio.mp3) no diretório do projeto ou em um caminho especificado. - Execute o seguinte comando em um terminal (supondo que o nome do arquivo seja
example.pdf):node dist/index.js --file example.pdf --output result.md - Aguarde a conclusão do processamento e produza o arquivo
result.mdserá gerado no diretório especificado.
- Prepare os arquivos a serem convertidos (por exemplo
- advertência::
- Para arquivos de imagem, certifique-se de que uma ferramenta de OCR (como o Tesseract) esteja instalada em seu sistema.
- Para arquivos de áudio, pode ser necessário configurar adicionalmente um serviço de transcrição de voz.
2. converta o conteúdo da Web em Markdown
- procedimento::
- Obter o URL da página de destino, por exemplo
https://example.com. - Digite-o no terminal:
node dist/index.js --url https://example.com --output webpage.md - Após a conclusão do processamento, o
webpage.mdO arquivo conterá o conteúdo do texto principal da página no formato Markdown.
- Obter o URL da página de destino, por exemplo
- Funções em destaque::
- Suporte à extração da descrição ou legenda do vídeo do YouTube (é necessário trabalhar com a API relacionada).
- Lida com páginas com tabelas aninhadas ou layouts complexos.
3. processamento em lote de vários documentos
- procedimento::
- Colocar vários arquivos em uma pasta (por exemplo
input_files). - Execute o comando de processamento em lote:
node dist/index.js --dir input_files --output-dir output_files - Um arquivo Markdown separado será gerado para cada arquivo e salvo no diretório
output_filespasta.
- Colocar vários arquivos em uma pasta (por exemplo
- de ponta::
- Ideal para organizar grandes quantidades de documentos ou informações e economizar tempo em operações manuais.
4. extensões de ferramentas personalizadas
- procedimento::
- Edite o arquivo
dist/index.jsou o arquivo de configuração relevante. - Adicionar novas ferramentas com base no protocolo MCP, como modelos personalizados de OCR ou regras específicas de análise da Web.
- Reconstrua e execute:
npm run build && npm start
- Edite o arquivo
- Cenários aplicáveis::
- Se a funcionalidade padrão não atender aos requisitos, ela poderá ser ampliada programaticamente.
Detalhes do processo de operação
- Processo de conversão de documentos::
- O usuário insere o caminho do arquivo ou o URL.
- O servidor chama o módulo apropriado (OCR, transcrição ou rastreamento da Web) para processar os dados.
- O resultado é formatado em Markdown e enviado para o arquivo especificado.
- Tratamento de erros::
- Se for encontrada uma dependência ausente, o terminal exibirá uma mensagem de erro, como
uv not foundNecessidade de verificaçãoUV_PATHSe está ou não configurado corretamente. - Problemas de rede podem fazer com que a página não seja rastreada, portanto, é recomendável verificar se o URL é válido.
- Se for encontrada uma dependência ausente, o terminal exibirá uma mensagem de erro, como
- Recomendações de otimização::
- Para arquivos grandes, recomenda-se o chunking para evitar o estouro de memória.
- Atualize regularmente o código do repositório para garantir que os recursos e as correções mais recentes sejam usados.
Com as etapas acima, os usuários podem começar a usar facilmente o Markdownify MCP Server para organizar documentos desordenados ou conteúdo da Web em um formato Markdown unificado, adequado para gerenciamento de documentos, organização do conhecimento ou criação de conteúdo.
© declaração de direitos autorais
O artigo é protegido por direitos autorais e não deve ser reproduzido sem permissão.

Publicações relacionadas


Nenhum comentário...