
MiMo-VL - 小米开源的多模态模型

MiMo-VL是什么
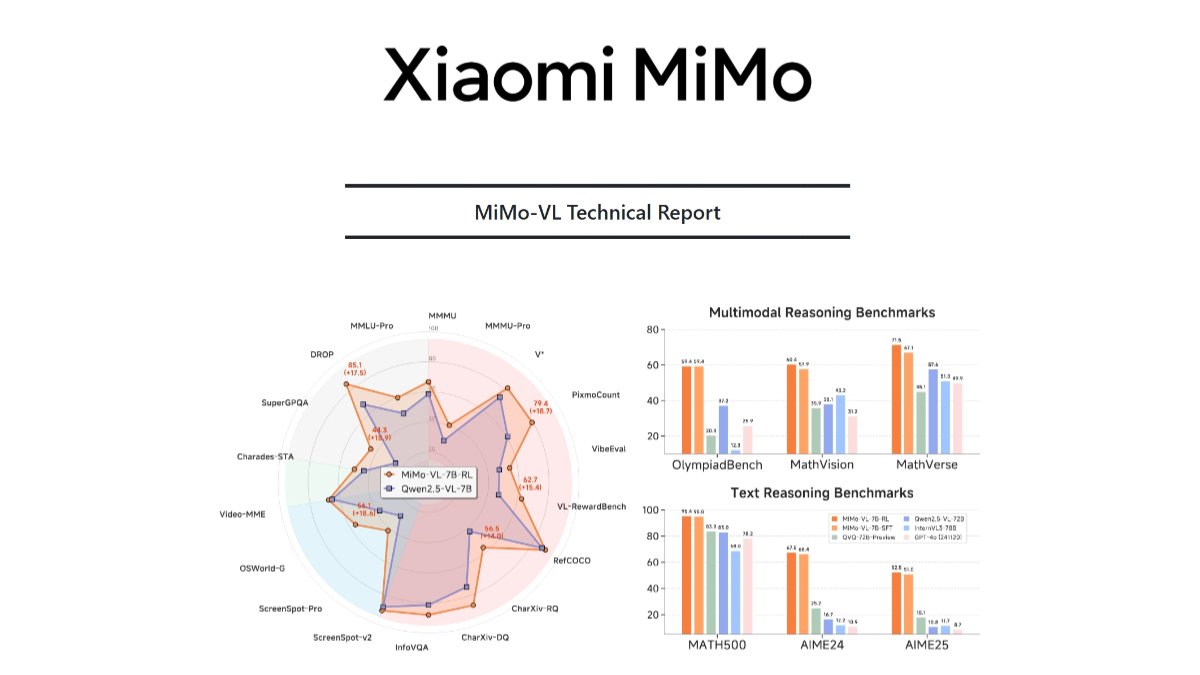
MiMo-VL是小米开源的多模态大模型,由视觉编码器、跨模态投影层和语言模型构成。视觉编码器基于Qwen2.5-ViT,支持原生分辨率输入,保留更多细节;语言模型是小米自研的MiMo-7B,专为复杂推理优化。模型基于多阶段预训练策略,用2.4T tokens的多模态数据进行训练,涵盖图片文本对、视频文本对、GUI操作序列等数据类型。基于混合在线强化学习(MORL)算法,全方位提升模型的推理、感知性能和用户体验。MiMo-VL在复杂图片推理、GUI交互、视频理解、长文档解析等任务上表现出色,例如在MMMU-val上达到66.7%,超越Gemma 3 27B;在OlympiadBench上达到59.4%,超越72B模型。
MiMo-VL的主要功能
- 复杂图片推理与问答:准确理解复杂图片内容给出合理解释和答案。
- GUI操作与交互:支持长达10多步的GUI操作,支持理解和执行复杂指令。
- 视频与语言理解:理解视频内容,结合语言进行推理和问答。
- 长文档解析与推理:处理长文档,进行复杂推理和信息提取。
- Otimização da experiência do usuário:基于混合在线强化学习,提升推理、感知性能和用户体验。
MiMo-VL的官网地址
- Github仓库::https://github.com/XiaomiMiMo/MiMo-VL
- Biblioteca do modelo HuggingFace::https://huggingface.co/collections/XiaomiMiMo/mimo-vl
- Documentos técnicos::https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report
如何使用MiMo-VL
- Hugging Face平台::
- 访问Hugging Face模型库:访问MiMo-VL的Hugging Face模型库Página.
- Modelos de carregamento:使用Hugging Face的Python库加载MiMo-VL模型。例如:
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("XiaomiMiMo/mimo-vl")
processor = AutoProcessor.from_pretrained("XiaomiMiMo/mimo-vl")- 处理输入数据:将图片、视频或文本等输入数据基于处理器进行预处理。
- Gerar saída:将处理后的数据输入模型,获取模型的输出结果。
- Repositório do GitHub::
- 克隆GitHub仓库: AcessoRepositório do GitHub,克隆仓库到本地。
git clone https://github.com/XiaomiMiMo/MiMo-VL.git- Instalação de dependências:根据仓库中的requirements.txt文件安装所需的Python依赖。
pip install -r requirements.txt- código de execução:按照仓库中的说明运行示例代码或开应用。
MiMo-VL的核心优势
- 多模态融合能力强:处理图像、视频和文本等多模态数据,理解复杂场景。
- 推理性能出色:在多个基准测试中表现优异,如在MMMU-val上达66.7%,在OlympiadBench上达59.4%。
- Otimização da experiência do usuário:基于混合在线强化学习(MORL),根据用户反馈动态调整模型行为,提升用户体验。
- Ampla gama de cenários de aplicação:适用智能客服、智能家居和科研等多个领域。
- Código aberto e suporte da comunidade:提供开源代码和社区支持,方便开发者研究和开发。
MiMo-VL的适用人群
- AI研究人员:专注于多模态融合、复杂推理、视觉与语言理解等领域的研究。
- 开发者和工程师:开发智能应用,如智能客服、智能家居、智能医疗等,需要集成多模态功能。
- 数据科学家:处理和分析多模态数据,提升模型性能和数据处理效率。
- Educadores e alunos:辅助教学和学习,如数学解题、编程学习等。
- 医疗专业人士:辅助医学图像分析和文本理解,提高诊断效率和准确性。
© declaração de direitos autorais
O artigo é protegido por direitos autorais e não deve ser reproduzido sem permissão.

Artigos relacionados


Nenhum comentário...