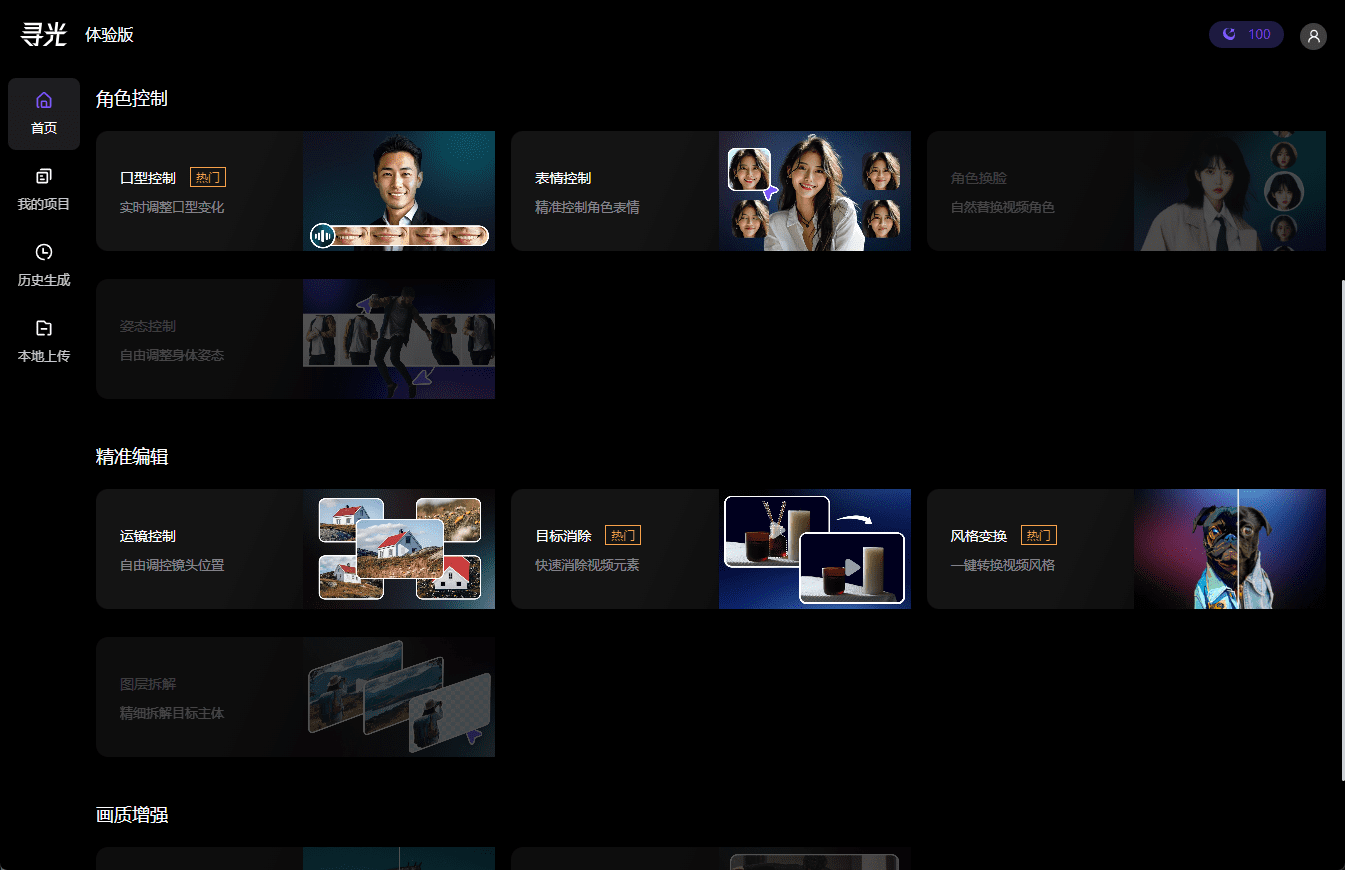
Hoje cedo, recebi uma notificação de que meu pedido de teste interno do "Searchlight" foi aprovado, portanto, publicarei uma breve análise antes de ir para a cama. A plataforma está posicionada como a "plataforma de aplicativos de capacidade de tecnologia visual" do Dharma Institute e, no momento, há menos aplicativos (em comparação com o lançamento), mas espero abrir gradualmente mais aplicativos visuais. A busca por luz é dividida em dois endereços: https...