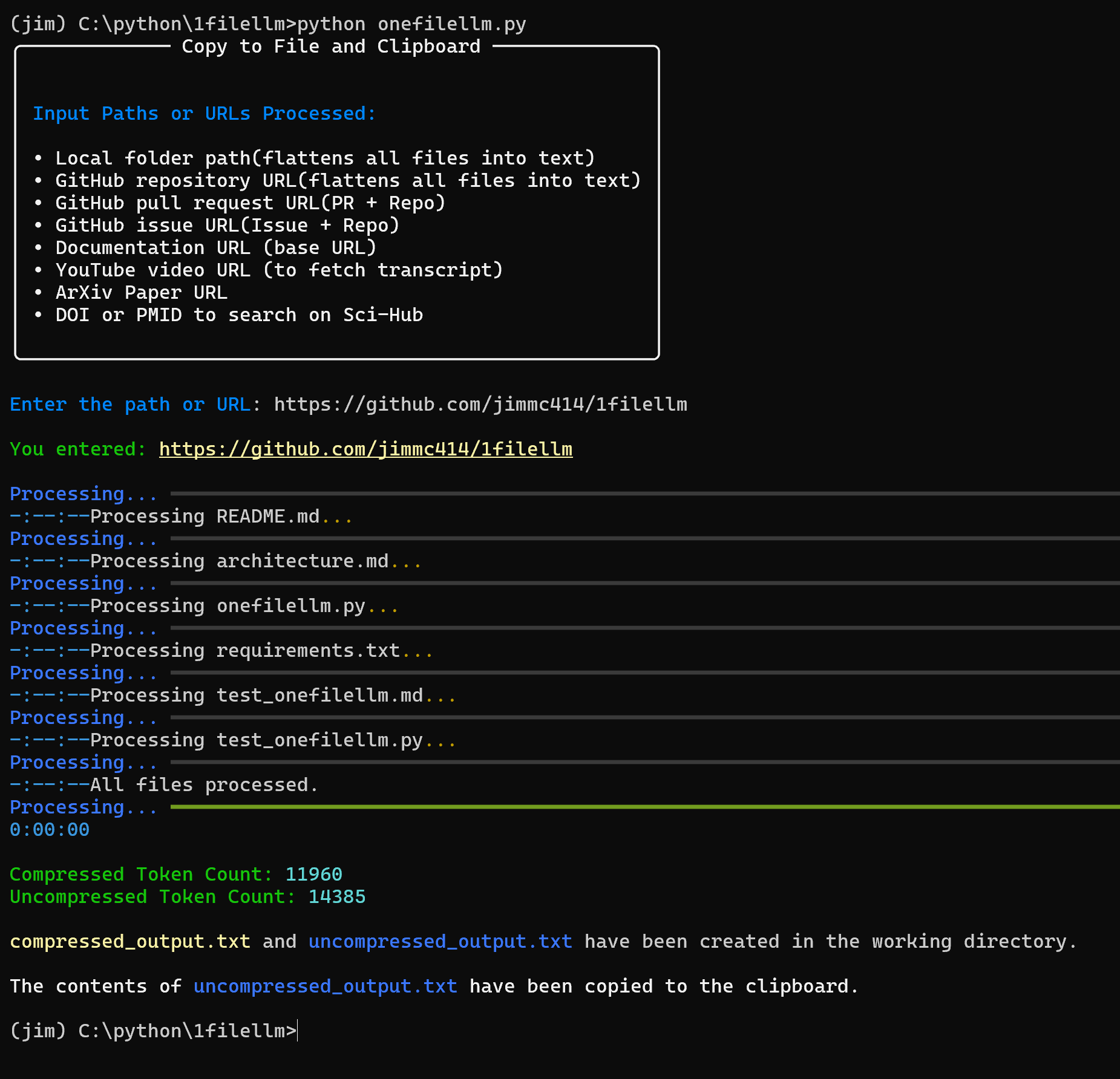
OneFileLLM:整合多种数据源为单一文本文件综合介绍 OneFileLLM 是一个开源命令行工具,旨在将多种数据源整合成单一文本文件,方便输入大语言模型(LLM)。它支持处理 GitHub 仓库、ArXiv 论文、YouTube 视频转录、网页...最新AI工具# AI开源项目# 文档提取与清洗3个月前0456
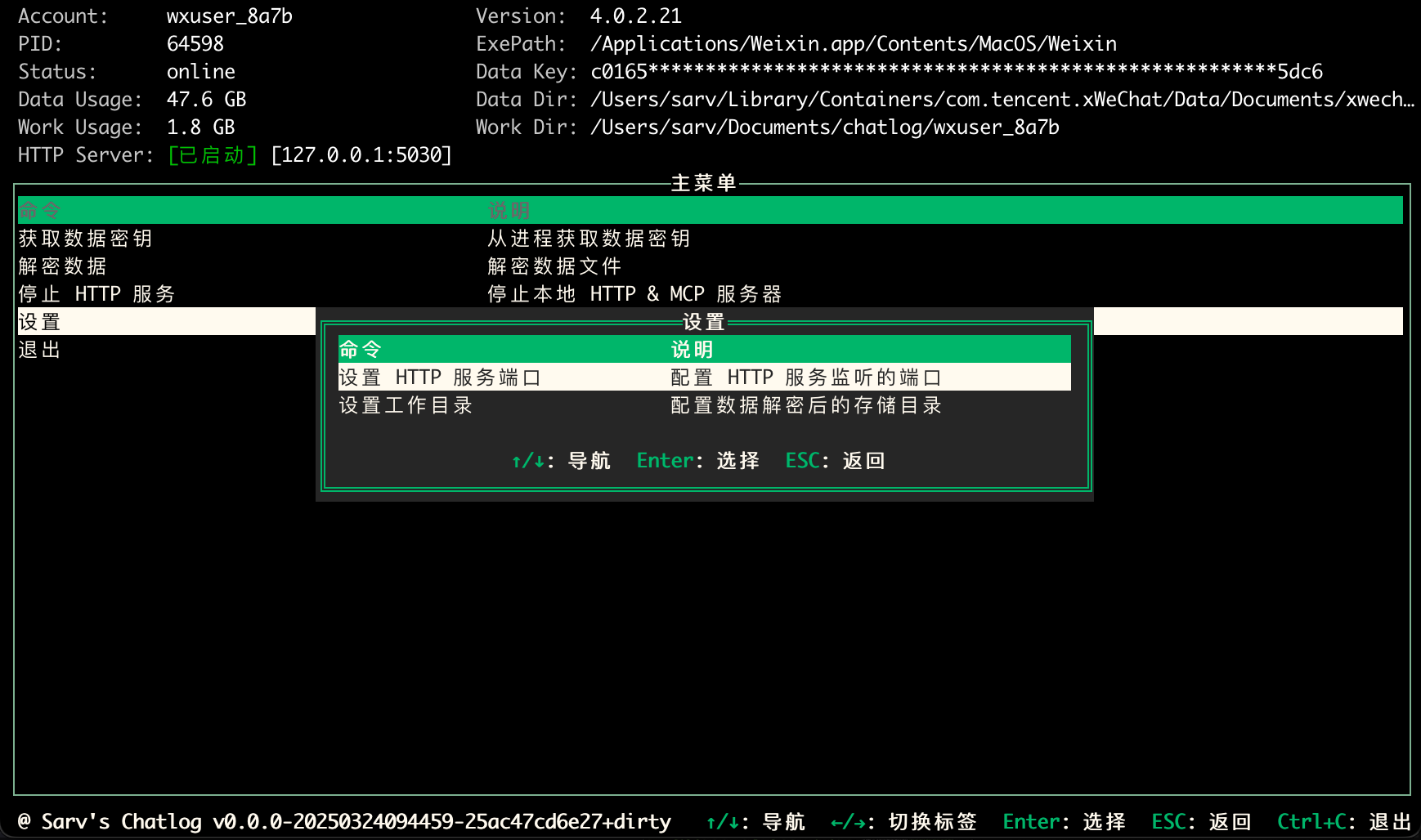
Chatlog:提取和查询微信聊天记录的开源工具综合介绍 Chatlog 是一个开源工具,专注于从微信本地数据库提取和查询聊天记录。它支持微信 3.x 和 4.0 版本,覆盖 Windows 和 macOS 系统。用户可以通过命令行、终端界面或 H...最新AI工具# AI开源项目# MCP服务# 文档提取与清洗3个月前0630
VOP:提取复杂图表与数学公式的OCR工具综合介绍 Versatile OCR Program 是一个开源的光学字符识别(OCR)工具,专门为处理复杂的学术和教育文档设计。它能从PDF、图像等文件中提取文本、表格、数学公式、图表和示意图,并生...最新AI工具# AI开源项目# OCR# 文档提取与清洗3个月前0561
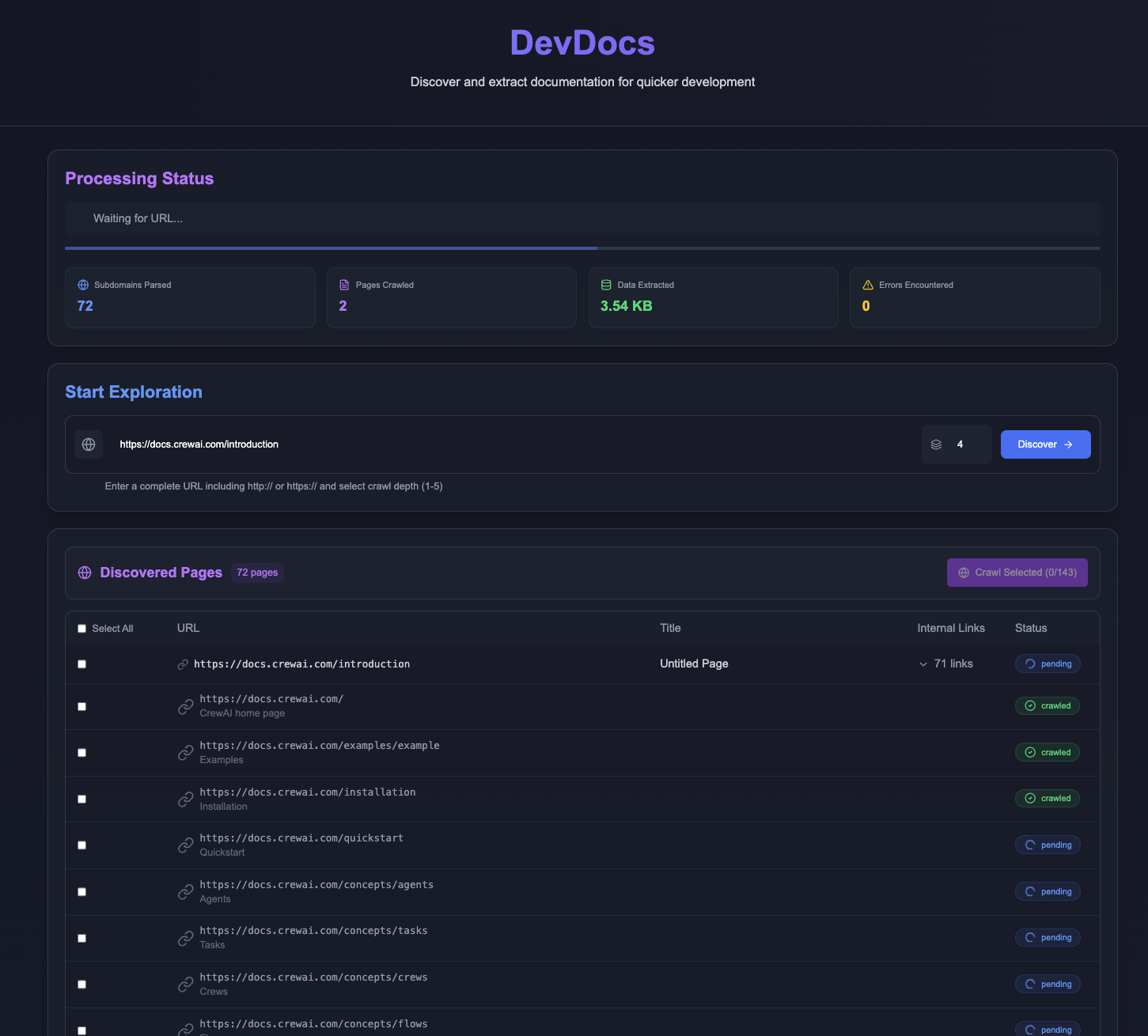
DevDocs:快速抓取并整理技术文档的MCP服务综合介绍 DevDocs 是一个完全免费的开源工具,由 CyberAGI 团队开发,托管在 GitHub 上。它专为程序员和软件开发者设计,能从技术文档的网址开始,自动爬取相关页面并整理成简洁的 Ma...最新AI工具# AI开源项目# MCP服务# 文档提取与清洗3个月前0574
自动解析PDF内容并提取文字与表格的开源服务综合介绍 它能自动分析PDF文档的布局,识别页面中的文字、标题、图片、表格、公式等元素,并判断它们的正确顺序。工具支持OCR功能,可以把扫描PDF转为可搜索文本。它基于Docker运行,提供两种模型...最新AI工具# AI开源项目# OCR# 文档提取与清洗3个月前0614
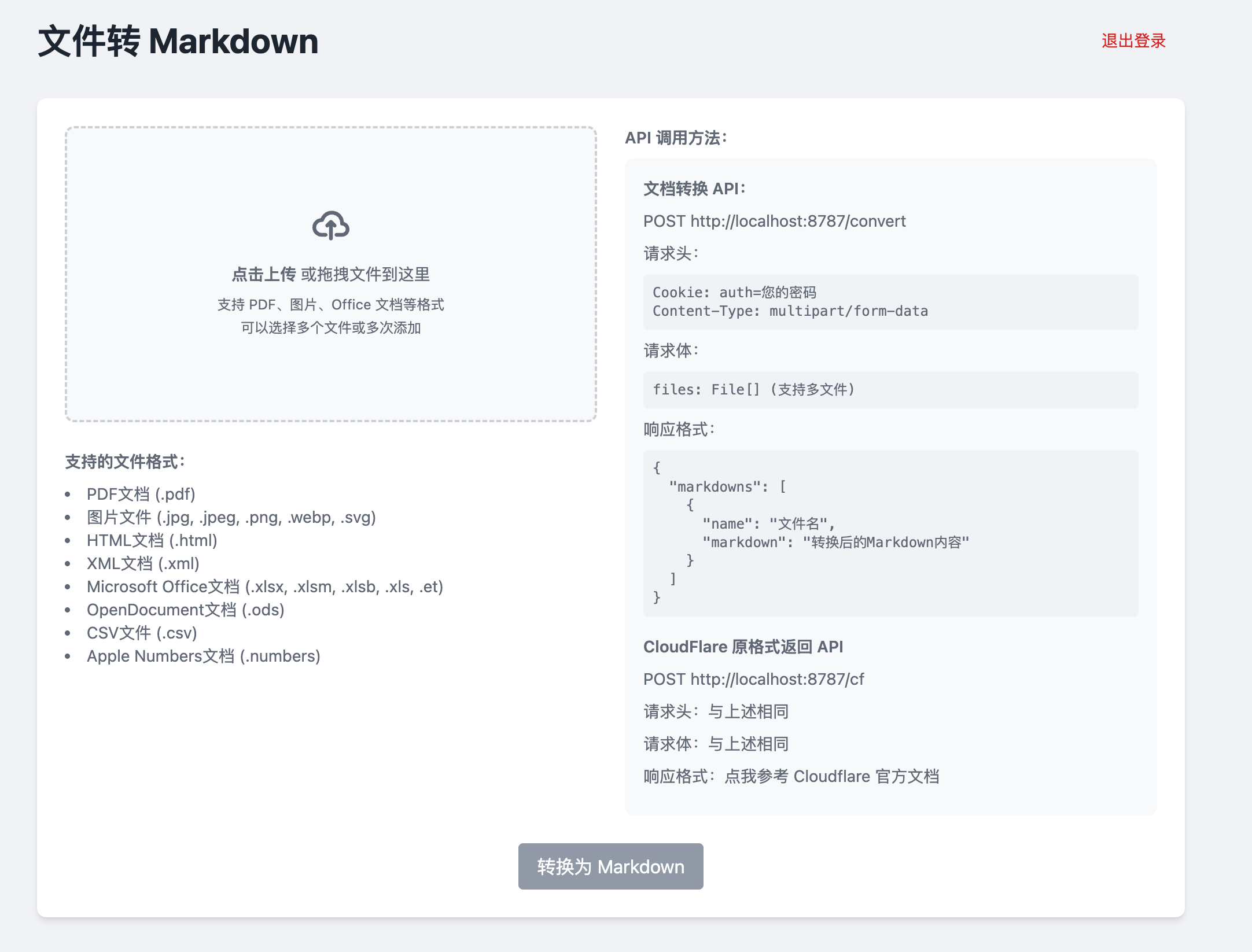
基于Workers AI免费将多种文件转为Markdown格式综合介绍 serverless-markdown-convertor 是一个免费的开源工具,基于 Cloudflare Worker 和 Workers AI 开发,能将多种文件转换为 Markdow...最新AI工具# AI开源项目# 文档提取与清洗4个月前0718
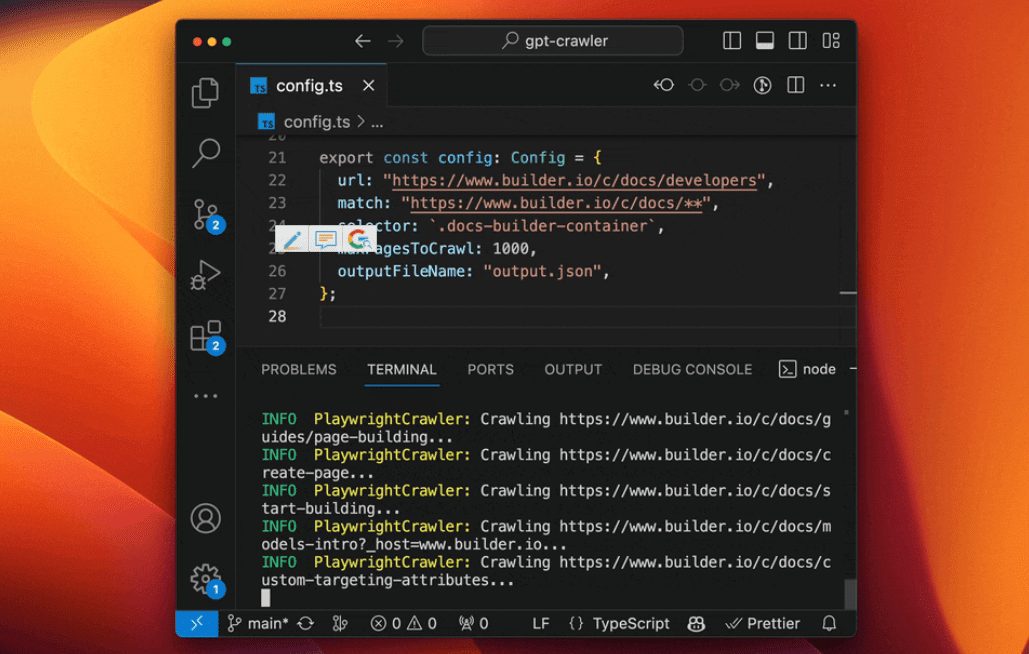
GPT-Crawler:自动爬取网站内容生成知识库文件综合介绍 GPT-Crawler 是由 BuilderIO 团队开发的一个开源工具,托管在 GitHub 上。它通过输入一个或多个网站 URL,爬取页面内容,生成结构化的知识文件(output.jso...最新AI工具# AI开源项目# 文档提取与清洗1个月前01.5K
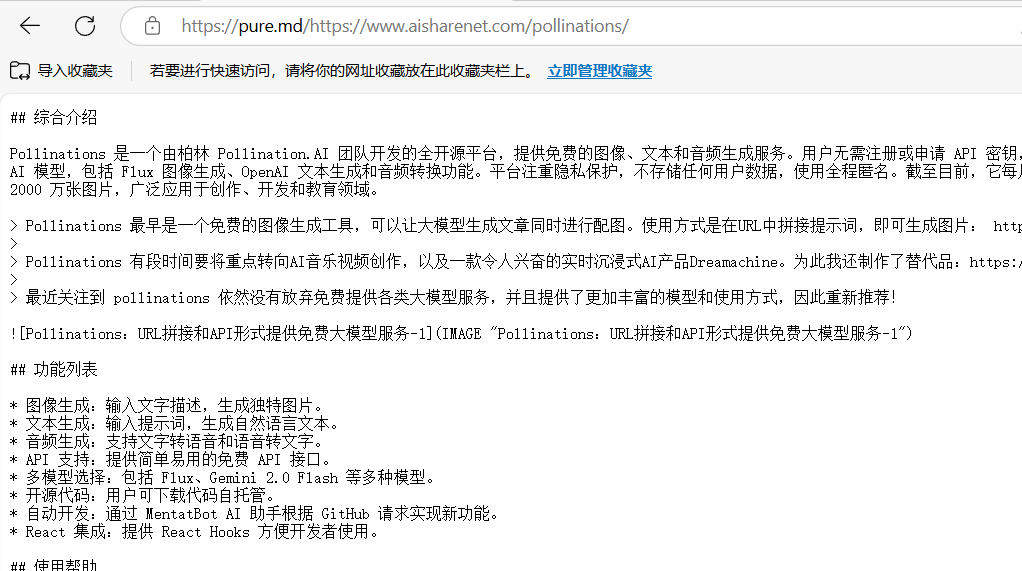
pure.md:网址前插入“pure.md/”即可提取干净的文本综合介绍 pure.md 是一个为 AI 代理和开发者设计的工具,主打快速将网页内容或文件转为 Markdown 格式。它通过代理服务绕过反爬虫限制,提取网页核心数据,并输出简洁的 Markdown ...最新AI工具# AI开放服务# 文档提取与清洗4个月前0705
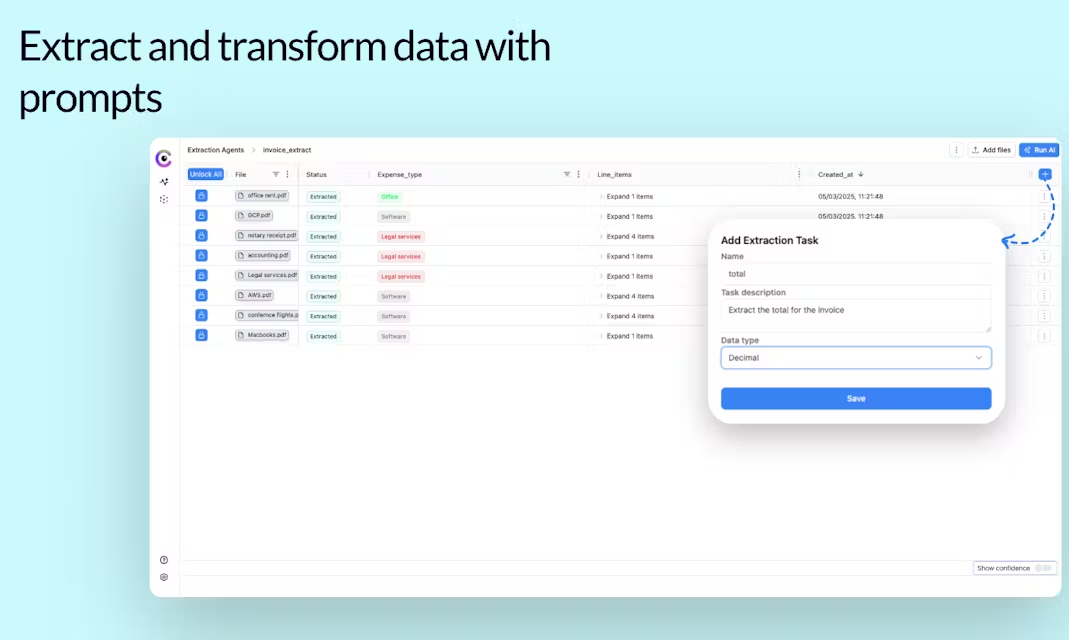
Cloudsquid:上传文档并描述要求智能提取结构化数据综合介绍 Cloudsquid 是一家 2023 年成立于德国柏林的公司,专注于用人工智能简化文件处理。它的核心产品是一个在线数据提取平台,用户只需上传 PDF、图片、音频、视频等文件,简单说明需要提...最新AI工具# 文档提取与清洗4个月前0685
PDF Craft:PDF扫描文件转Markdown的开源工具综合介绍 PDF Craft 是一个开源工具,专为扫描书籍的PDF设计,能将其转换为Markdown格式。它由 oomol-lab 开发,托管在 GitHub 上,适合喜欢整理电子书的用户。工具通过本...最新AI工具# AI开源项目# OCR# 文档提取与清洗4个月前0870
Supametas.AI:提取非结构化数据为LLM高可用数据综合介绍 Supametas.AI 是一个数据处理平台,专门把网页、文档、音视频等杂乱信息整理成AI能用的结构化数据。它支持从多个来源收集数据,包括网页链接、API、本地文件等,然后输出为 JSON ...最新AI工具# AI开放服务# 文档提取与清洗4个月前0687
MarkPDFDown:基于多模态模型将PDF转为Markdown文件综合介绍 MarkPDFDown 是一个开源工具。它利用多模态大语言模型,把 PDF 文件转为 Markdown 格式。开发者是 GitHub 用户 jorben。这个工具的目标很简单:让 PDF 文...最新AI工具# AI开源项目# 文档提取与清洗4个月前0890
SmolDocling:小体积高效处理文档的视觉语言模型综合介绍 SmolDocling 是由 ds4sd 团队与 IBM 合作开发的一个视觉语言模型(VLM),基于 SmolVLM-256M 打造,托管在 Hugging Face 平台。它体积小,只有 ...最新AI工具# AI开源项目# OCR# 文档提取与清洗4个月前0838
飞桨 PP-TableMagic:复杂表格结构化信息提取神器表格识别的目标是解析图片中的表格,准确识别表格结构和单元格位置,并将其还原为结构化的表格格式(例如 HTML)。在当今信息化时代,大量重要的表格数据仍以非结构化状态存在(如扫描文档中的信息统计表图片...最新AI工具# AI开源项目# 文档提取与清洗4个月前0843
Mistral OCR:94.89%总体精度,1000 页/30秒,只需1美元在人类文明的历史长河中,每一次信息获取和解析方式的飞跃,都深刻地推动着社会进步。从远古的象形文字,到便携的纸莎草,再到后来出现的印刷术以及当今的数字化浪潮,每一次技术革新都极大地拓展了人类知识的传播范...最新AI工具# AI开放服务# OCR# 文档提取与清洗4个月前0766
Firecrawl MCP Server:基于 Firecrawl 的网页爬虫 MCP 服务综合介绍 Firecrawl MCP Server 是由 MendableAI 开发的一款开源工具,基于 Model Context Protocol (MCP) 协议实现,与 Firecrawl A...最新AI工具# AI开源项目# MCP服务# 文档提取与清洗4个月前01.1K
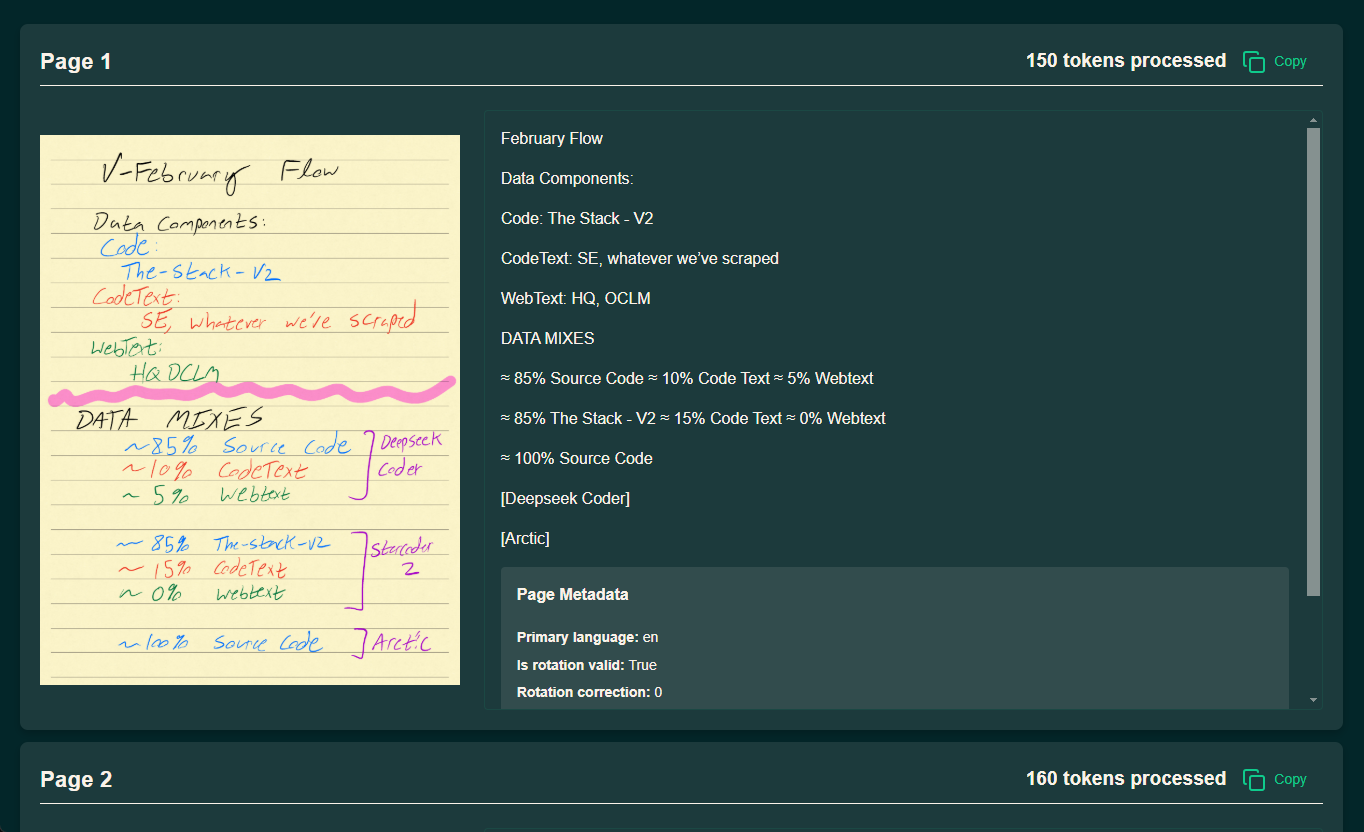
olmOCR:PDF文档转换为文本,支持表格、公式和手写内容的识别综合介绍 olmOCR 是由 Allen Institute for Artificial Intelligence (AI2) 的 AllenNLP 团队开发的一款开源工具,专注于将 PDF 文件转...最新AI工具# AI开源项目# 文档提取与清洗5个月前01.1K
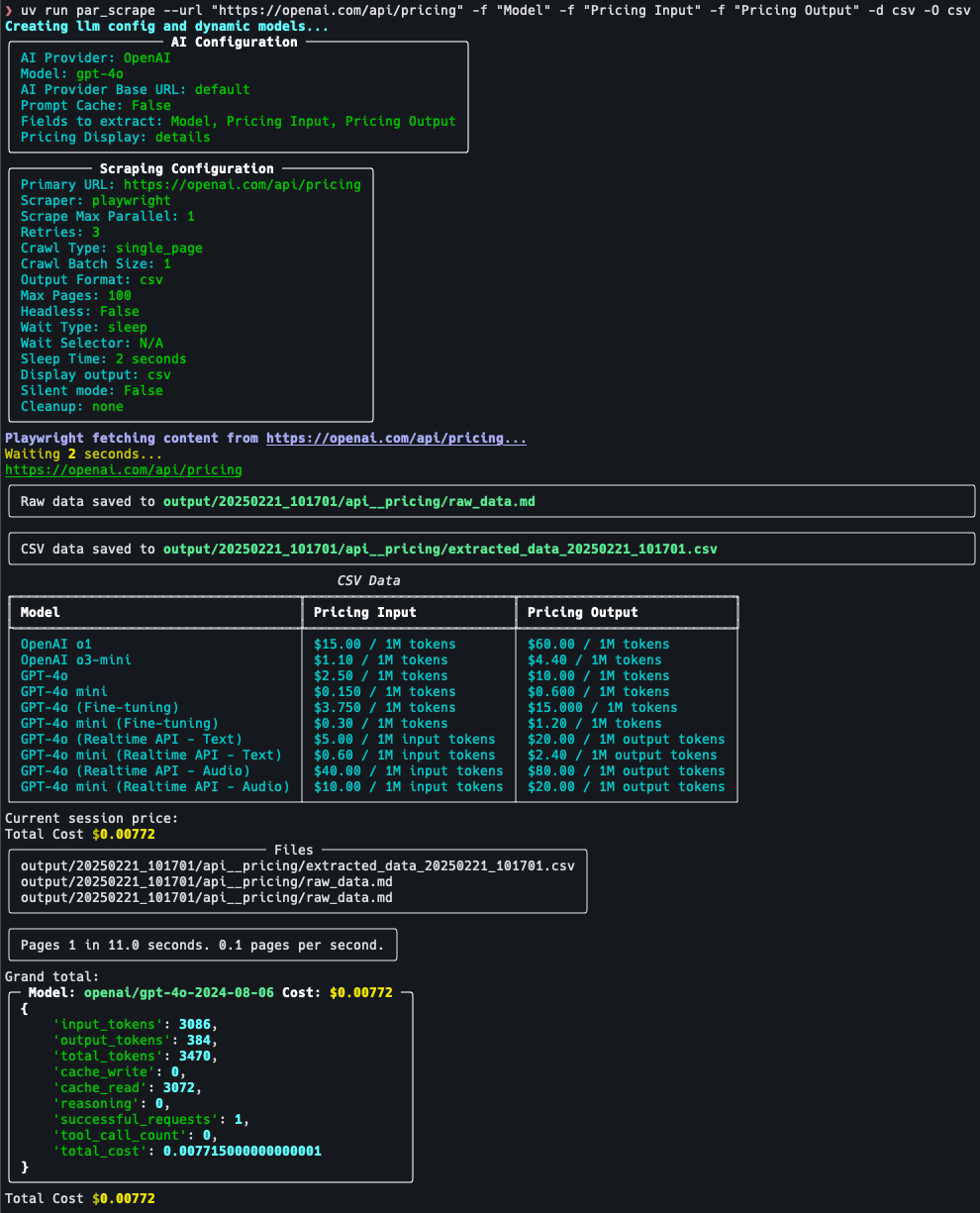
par_scrape:智能提取网页数据的爬虫工具综合介绍 par_scrape 是一个基于 Python 的开源网页爬虫工具,由开发者 Paul Robello 在 GitHub 上推出,旨在帮助用户从网页中智能提取数据。它整合了 Selenium...最新AI工具# AI开源项目# 文档提取与清洗5个月前0804
PDF-Extract-Kit:提取复杂结构PDF内容的开源工具综合介绍 PDF-Extract-Kit 是一个由 OpenDataLab 团队开发的开源项目,专注于从复杂多样的 PDF 文档中高效提取高质量内容。它集成了先进的文档解析技术,支持布局检测、公式识别...最新AI工具# AI开源项目# 文档提取与清洗5个月前0985