V-JEPA 2是什么
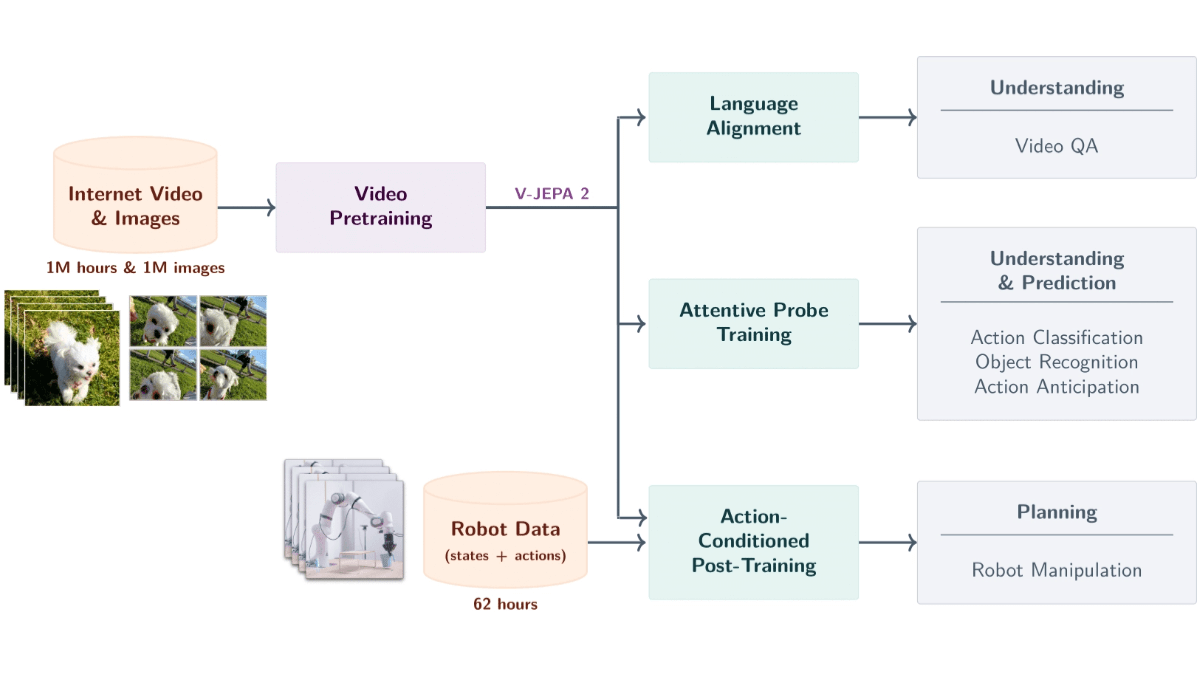
V-JEPA 2 是 Meta AI 推出的基于视频数据的世界大模型,拥有 12 亿参数。模型基于自监督学习从超过 100 万小时的视频和 100 万张图像中训练而成,能理解物理世界中的物体、动作和运动,预测未来状态。模型用编码器-预测器架构,结合动作条件预测,支持零样本机器人规划,让机器人在新环境中完成任务。模型具备视频问答能力,支持结合语言模型回答与视频内容相关的问题。V-JEPA 2 在动作识别、预测和视频问答等任务上表现出色,为机器人控制、智能监控、教育和医疗等领域提供强大的技术支持,是迈向高级机器智能的重要一步。
V-JEPA 2的主要功能
- 视频语义解析:从视频中识别物体、动作和运动,精准提取场景的语义信息。
- 未来事件预测:基于当前状态和动作,预测未来视频帧或动作结果,支持短期和长期预测。
- 机器人零样本规划:基于预测能力,在新环境中为机器人规划任务,如抓取和操作物体,无需额外训练数据。
- 视频问答交互:结合语言模型,回答与视频内容相关的问题,涵盖物理因果关系和场景理解。
- 跨场景泛化:在未见过的环境和物体上表现良好,支持新场景中的零样本学习和适应。
V-JEPA 2的官网地址
- 项目官网:https://ai.meta.com/blog/v-jepa-2
- GitHub仓库:https://github.com/facebookresearch/vjepa2
- 技术论文:https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
如何使用V-JEPA 2
- 获取模型资源:从 GitHub 仓库中下载预训练模型文件和相关代码。模型文件以 .pth 或 .ckpt格式提供。
- 设置开发环境:
- 安装Python:确保已安装Python(建议使用 Python 3.8 或更高版本)。
- 安装依赖库:使用pip安装项目所需的依赖库。通常,项目提供一个 requirements.txt 文件,基于以下命令安装依赖:
pip install -r requirements.txt- 安装深度学习框架:V-JEPA 2基于PyTorch开发,需要安装PyTorch。根据系统和GP 配置,从PyTorch官网 获取安装命令。
- 加载模型:
- 加载预训练模型:用PyTorch加载预训练模型文件。
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- 准备输入数据:
- 视频数据预处理:V-JEPA 2需要视频数据作为输入。将视频数据转换为模型所需的格式(通常是张量)。以下是一个简单的预处理示例:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- 用模型进行预测:
- 执行预测:将预处理后的视频数据输入模型,获取预测结果。以下是示例代码:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- 解析和应用预测结果:
- 解析预测结果:根据任务需求解析模型的输出。
- 应用到实际场景:将预测结果应用到实际任务中,例如机器人控制、视频问答或异常检测等。
V-JEPA 2的核心优势
- 强大的物理世界理解能力:V-JEPA 2能基于视频输入精准识别物体动作和运动,捕捉场景的语义信息,为复杂任务提供基础支持。
- 高效的未来状态预测:基于当前状态和动作,模型能预测未来视频帧或动作结果,支持短期和长期预测,助力机器人规划和智能监控等应用。
- 零样本学习与泛化能力:V-JEPA 2在未见过的环境和物体上表现良好,支持零样本学习和适应,无需额外训练数据即可完成新任务。
- 结合语言模型的视频问答能力:与语言模型结合后,V-JEPA 2能回答与视频内容相关的问题,涵盖物理因果关系和场景理解,拓展在教育和医疗等领域的应用。
- 基于自监督学习的高效训练:基于自监督学习从大规模视频数据中学习通用视觉表示,无需人工标注数据,降低成本提高泛化能力。
- 多阶段训练与动作条件预测:基于多阶段训练,V-JEPA 2先预训练编码器,再训练动作条件预测器,结合视觉和动作信息,支持精准的预测控制。
V-JEPA 2的适用人群
- 人工智能研究人员:用V-JEPA 2的前沿技术进行学术研究和技术创新,推动机器智能发展。
- 机器人工程师:借助模型零样本规划能力,开发适应新环境的机器人系统,完成复杂任务。
- 计算机视觉开发者:用V-JEPA 2提升视频分析效率,用在智能安防、工业自动化等领域。
- 自然语言处理专家:结合视觉和语言模型,开发智能交互系统,如虚拟助手和智能客服。
- 教育工作者:基于视频问答功能,开发沉浸式教育工具,提升教学效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...