DeepSeek R1 in RAG: Eine Zusammenfassung der praktischen Erfahrungen
DeepSeek R1 hat in seiner ersten Version starke Inferenzfähigkeiten gezeigt. In diesem Blog-Beitrag teilen wir die Details der Verwendung von DeepSeek R1 zur Erstellung von Retrieval-Augmented Generatio...
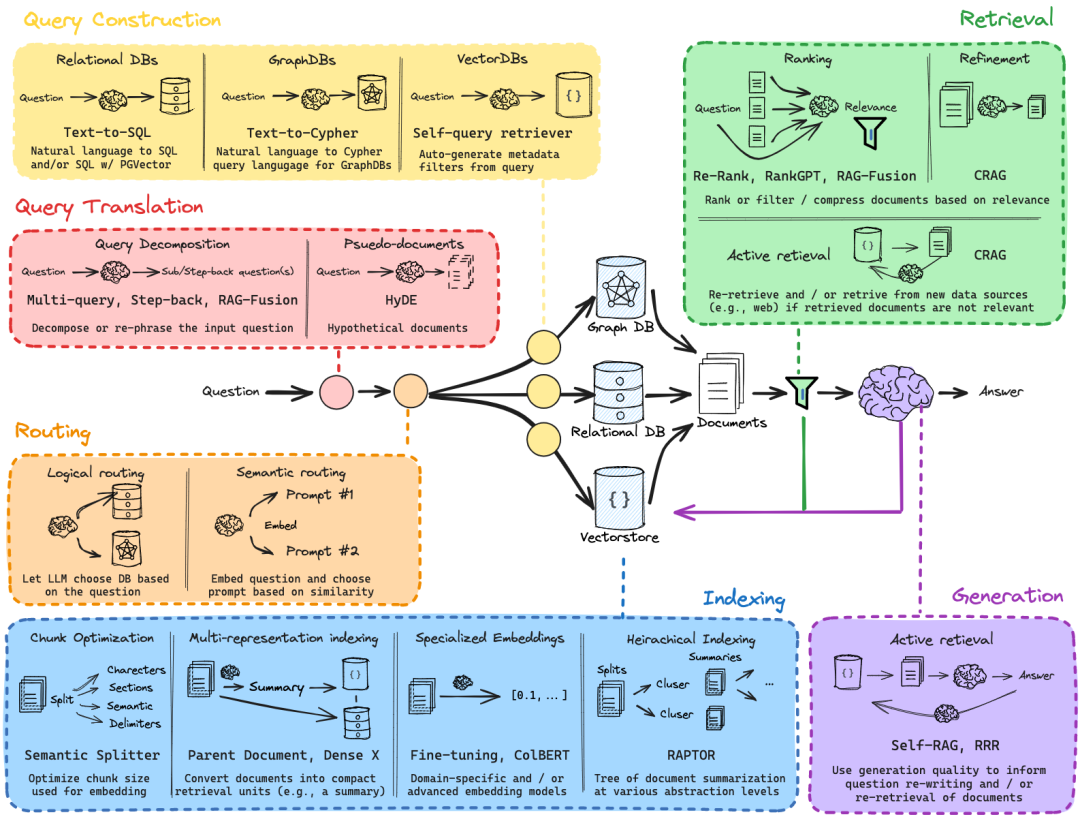






![[转载]QwQ-32B 的工具调用能力及 Agentic RAG 应用](https://oss.sharenet.ai/wp-content/uploads/2025/03/b04be76812d1a15.jpg)




