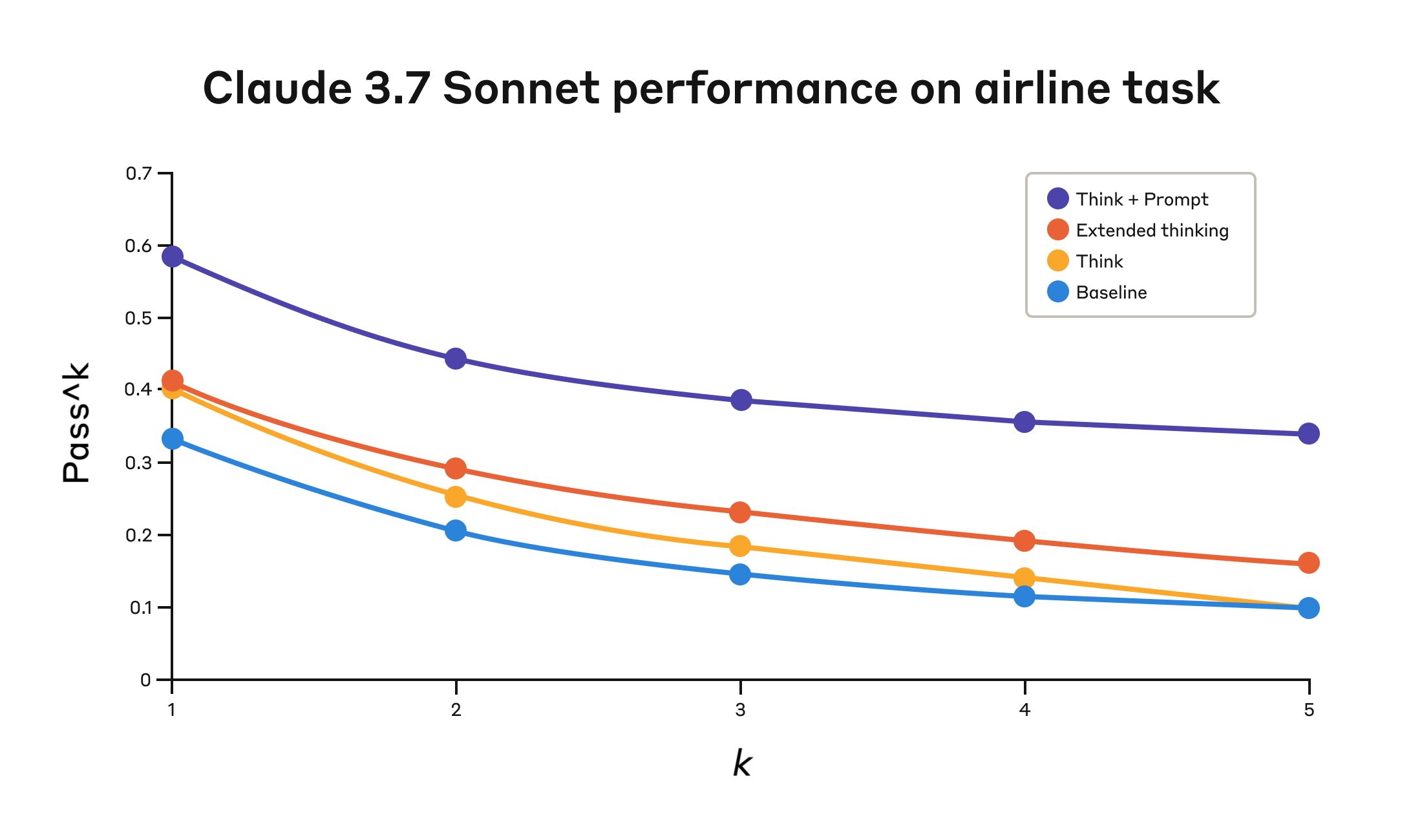
Récemment, Anthropic a introduit un nouvel outil appelé "think", qui est conçu pour améliorer les capacités du modèle Claude pour la résolution de problèmes complexes. Dans cet article, nous examinerons de plus près la philosophie de conception de l'outil "think", ses performances et les applications pratiques des...
Gemma 3 Résumé des informations clés I. Paramètres clés Paramètres Détails Taille du modèle 100 millions à 27 milliards de paramètres en quatre versions : 1B, 4B, 12B, 27B Architecture Architecture spécifique du décodeur à base de transformateurs héritée de Gem...
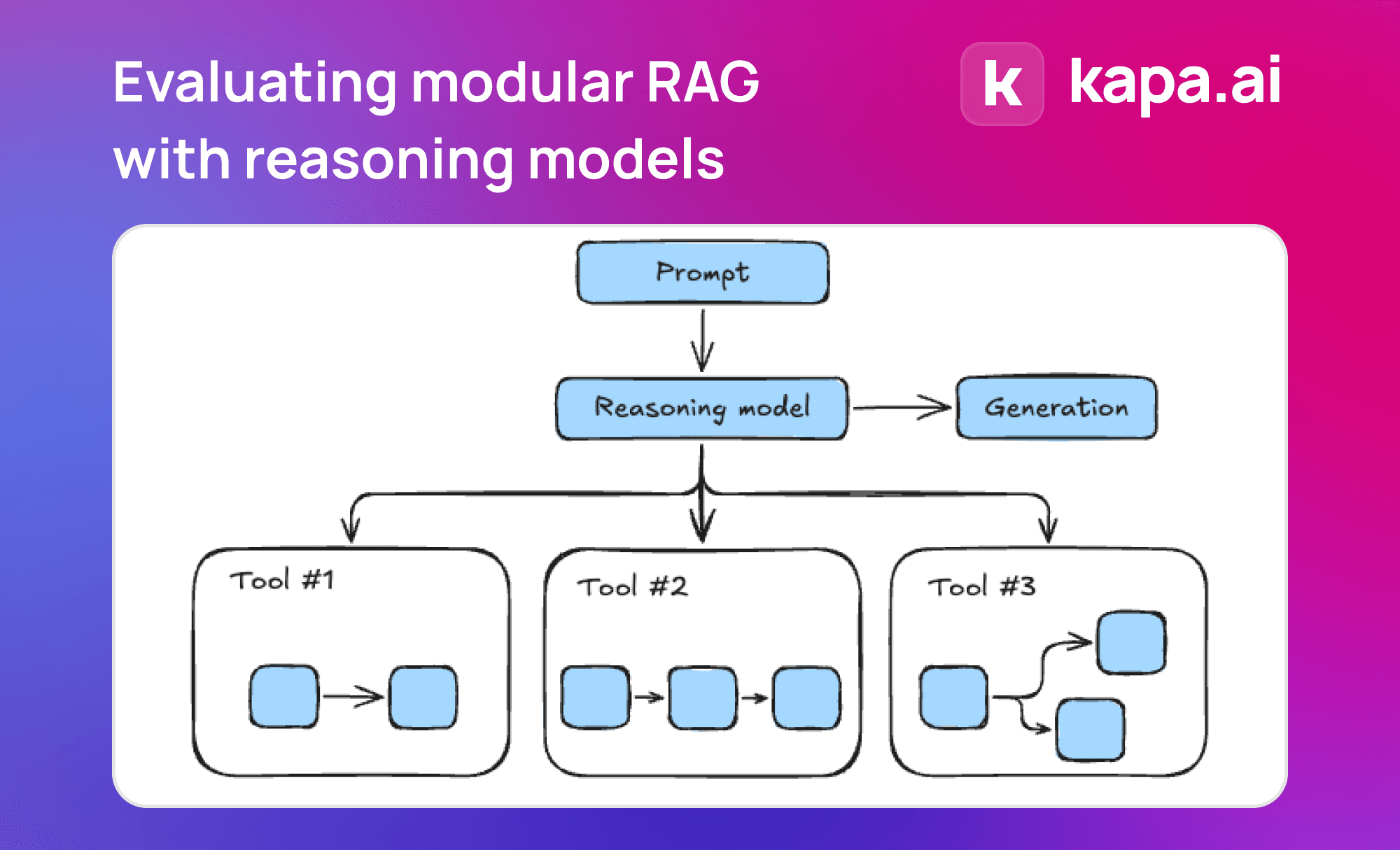
Les grands modèles de langage (LLM) évoluent rapidement et leur capacité de raisonnement est devenue un indicateur clé de leur niveau d'intelligence. En particulier, les modèles dotés de longues capacités de raisonnement, tels que o1 d'OpenAI, DeepSeek-R1, QwQ-32B et Kimi K1.5 ...
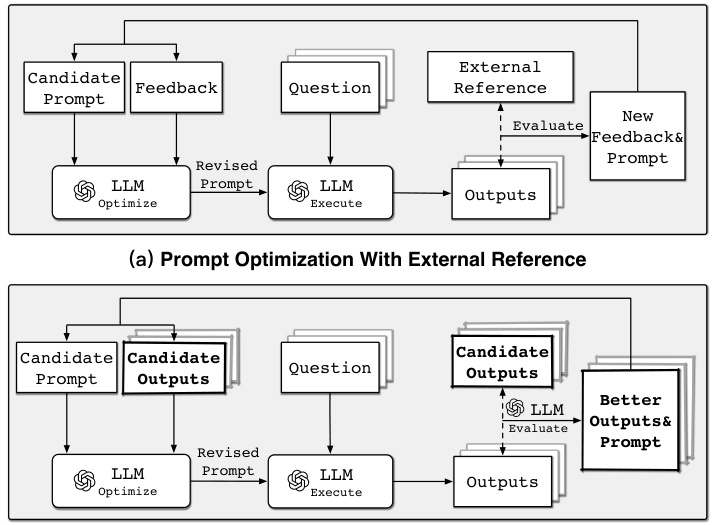
INTRODUCTION Ces dernières années, les grands modèles de langage (LLM) ont fait des progrès impressionnants dans le domaine de l'intelligence artificielle, et leurs puissantes capacités de compréhension et de génération de langage ont conduit à un large éventail d'applications dans plusieurs domaines. Cependant, les LLMs sont encore confrontés à de nombreux défis lorsqu'ils traitent des tâches complexes qui nécessitent l'invocation d'outils externes...
Les grands modèles linguistiques (LLM) comme Claude ne sont pas créés par des humains qui écrivent un code de programmation direct, ils sont formés sur d'énormes quantités de données. Au cours de ce processus, les modèles apprennent leurs propres stratégies de résolution de problèmes. Ces stratégies sont cachées dans les milliards de fois où le modèle génère chaque mot...
Résumé Les systèmes de recherche d'information sont essentiels pour un accès efficace à de grandes collections de documents. Les approches récentes utilisent de grands modèles de langage (LLM) pour améliorer les performances de recherche grâce à l'augmentation des requêtes, mais reposent généralement sur des techniques coûteuses d'apprentissage supervisé ou de distillation qui nécessitent des ressources informatiques importantes et des données étiquetées manuellement ...
Le projet GraphRAG vise à étendre la gamme de questions auxquelles les systèmes d'intelligence artificielle peuvent répondre sur des ensembles de données privées en exploitant les relations implicites dans les textes non structurés. L'un des principaux avantages de GraphRAG par rapport à la recherche vectorielle traditionnelle (ou "recherche sémantique") est sa capacité à répondre à des questions...
INTRODUCTION Ces dernières années, les systèmes multi-intelligents (SMI) ont suscité beaucoup d'intérêt dans le domaine de l'intelligence artificielle. Ces systèmes tentent de résoudre des tâches complexes à plusieurs étapes grâce à la collaboration de plusieurs intelligences de type Large Language Model (LLM). Cependant, malgré les attentes élevées à l'égard des SMA, leur performance dans les applications pratiques...






![[转载]QwQ-32B 的工具调用能力及 Agentic RAG 应用](https://oss.sharenet.ai/wp-content/uploads/2025/03/b04be76812d1a15.jpg)




