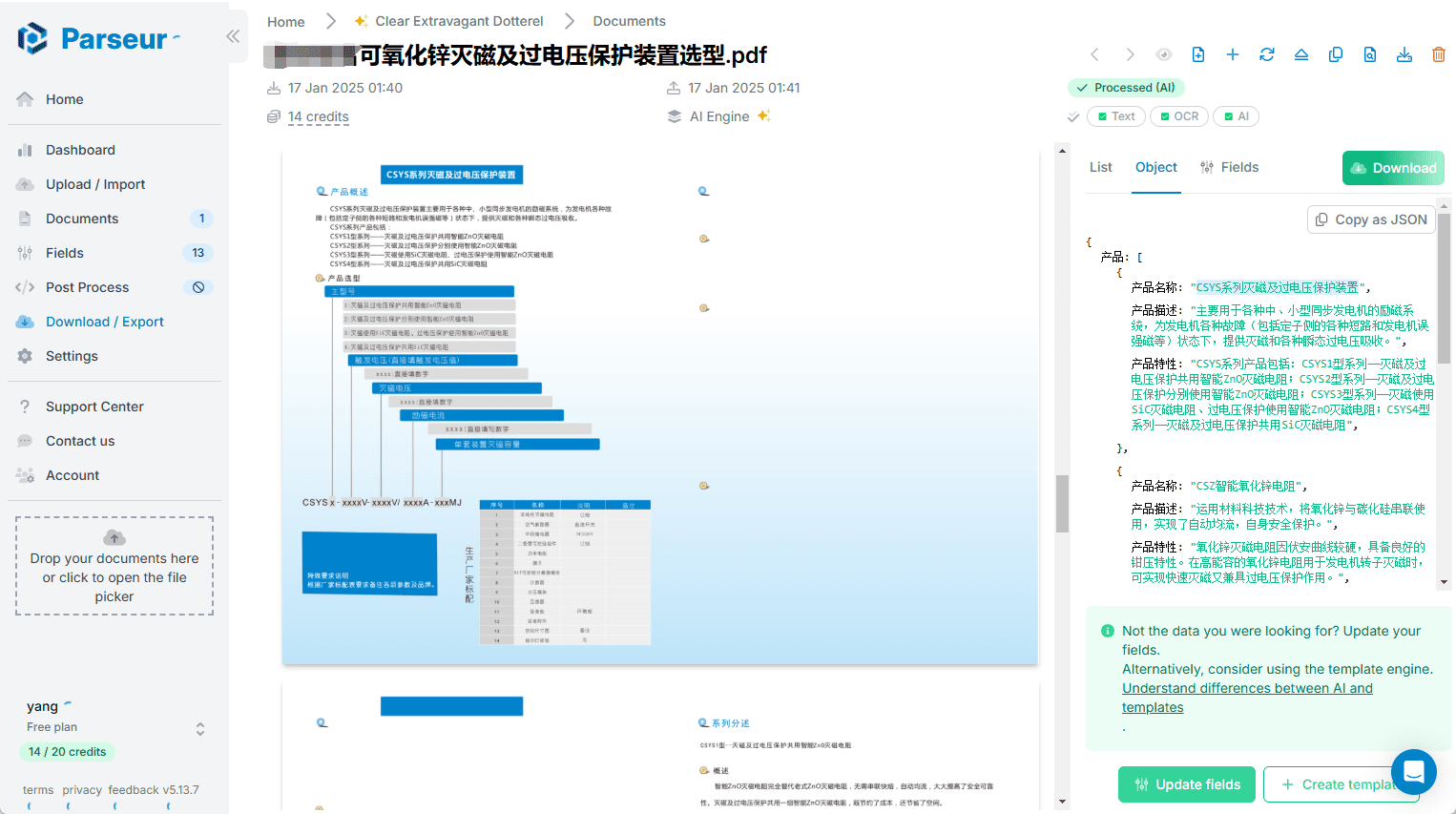
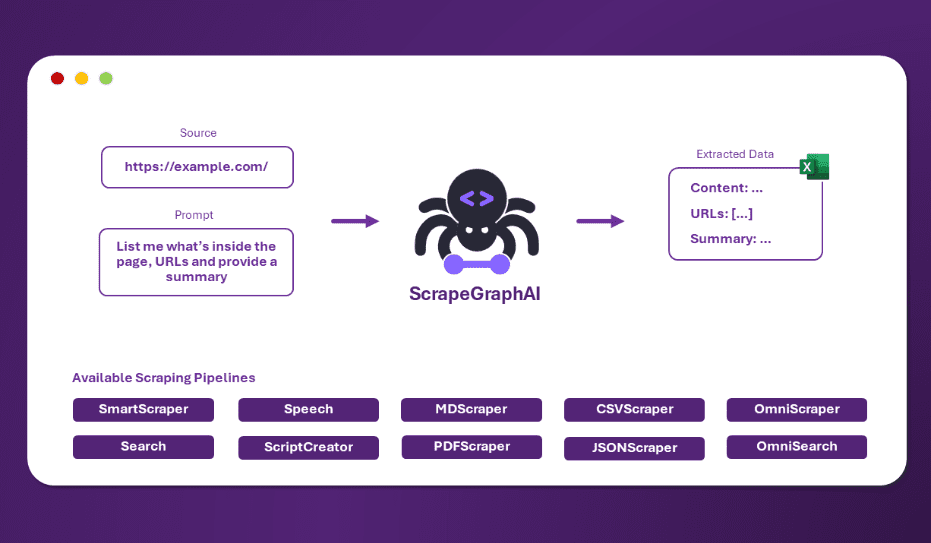
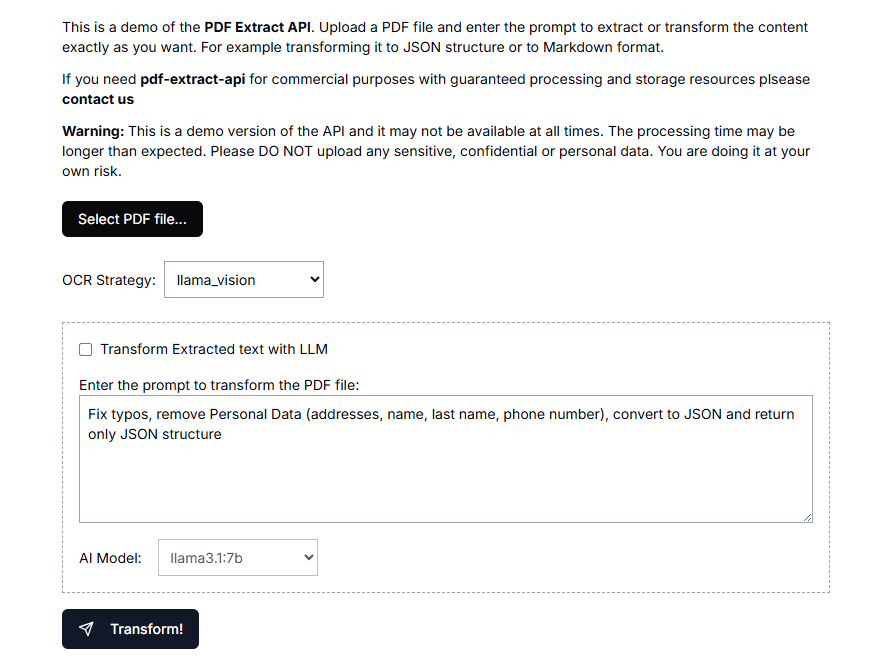
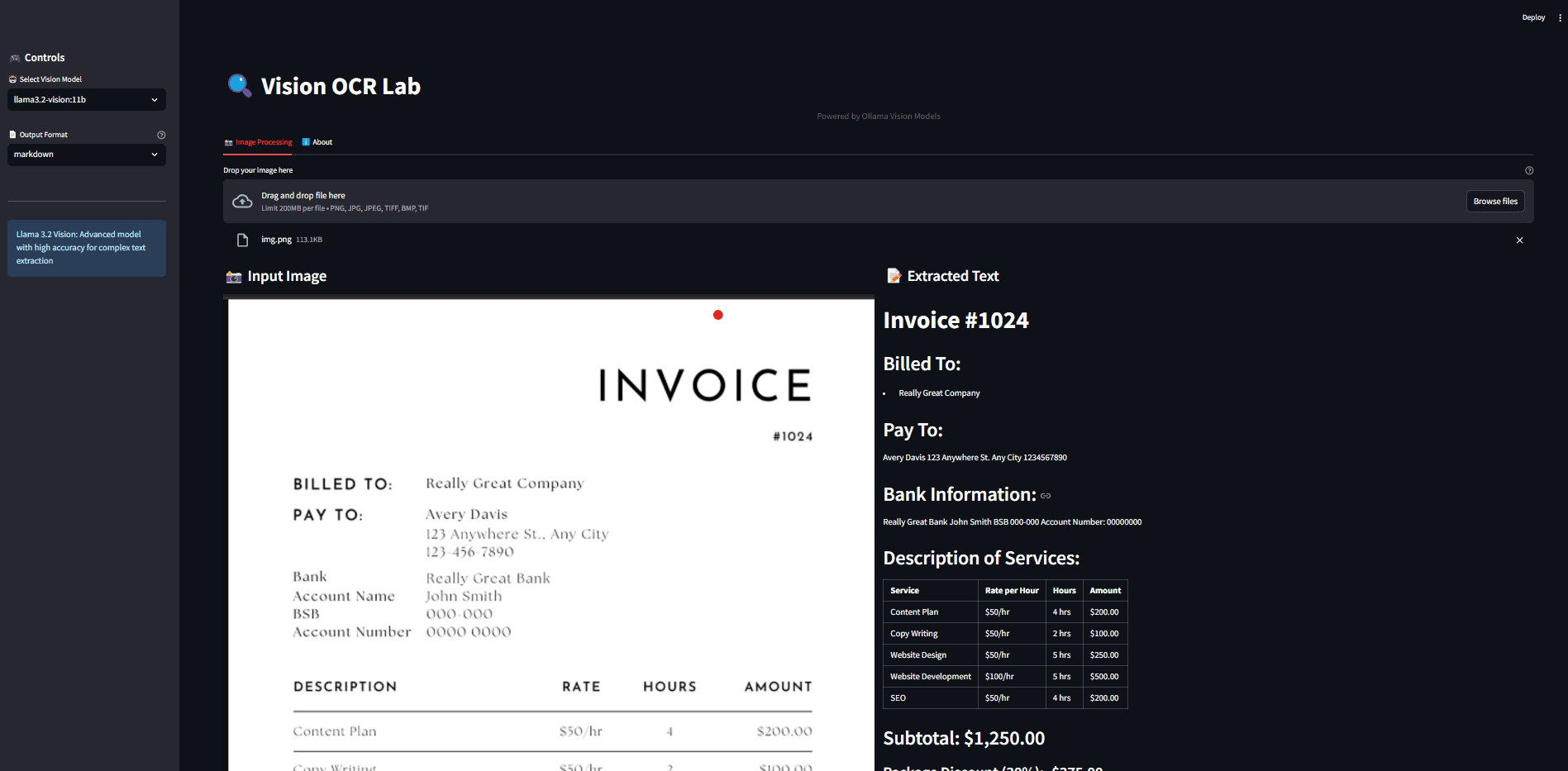
SemHash: Schnelle Implementierung der semantischen Text-Deduplizierung zur Verbesserung der Effizienz der Datenbereinigung
Umfassende Einführung SemHash ist ein leichtgewichtiges und flexibles Werkzeug zum Entduplizieren von Datensätzen durch semantische Ähnlichkeit. Es kombiniert die schnelle Einbettungsgenerierung von Model2Vec mit der effizienten ANN (approximate nearest neighbour) Ähnlichkeitssuche von Vicinity.SemHa...