SemHash: データクリーニング効率を向上させるセマンティックテキスト重複排除の高速実装包括的な紹介 SemHashは、意味的類似性によってデータセットの重複を除去するための軽量で柔軟なツールです。Model2Vecの高速な埋め込み生成と、Vicinityの効率的なANN(近似最近傍)類似検索を組み合わせています。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前09530
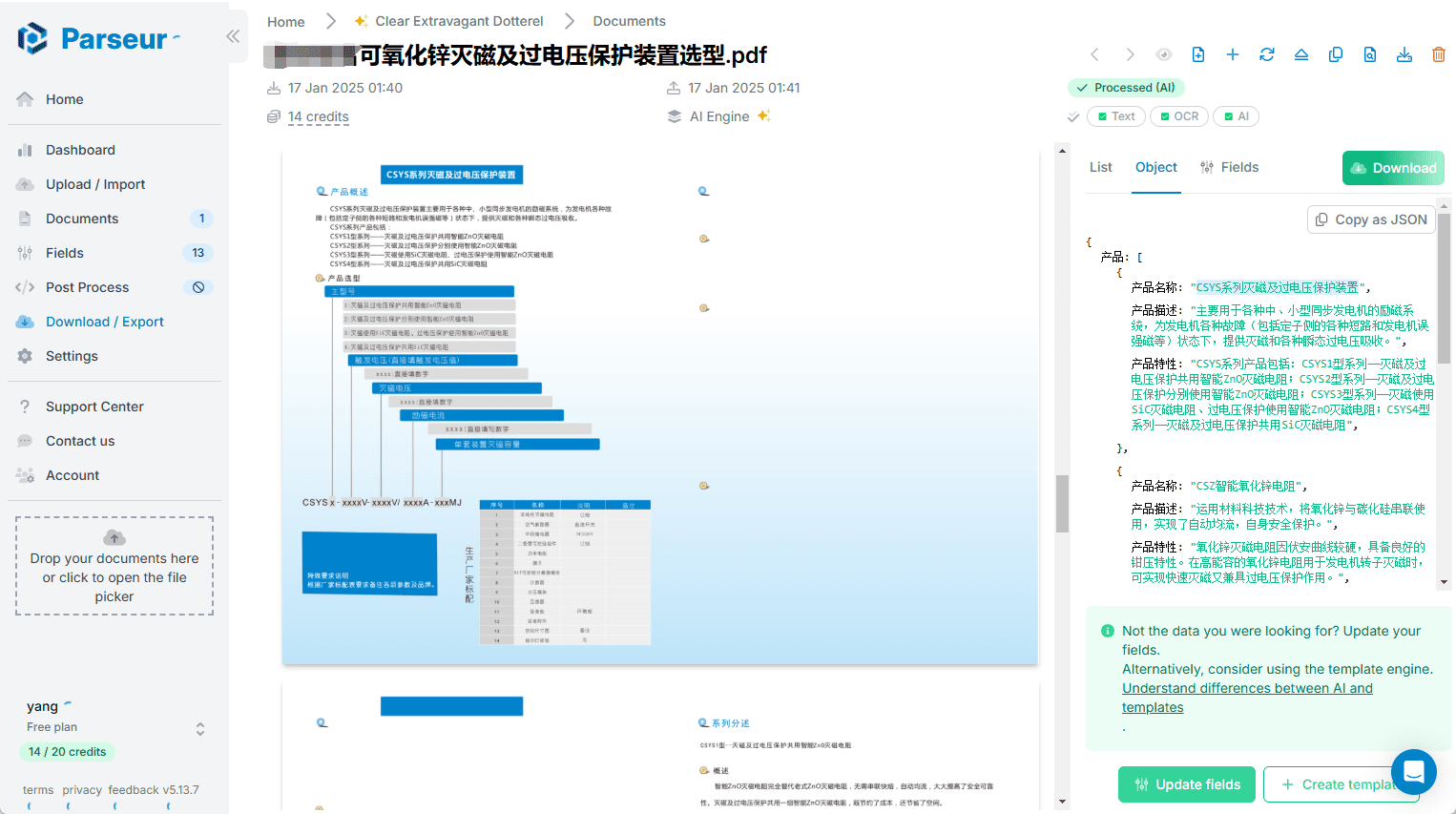
Parseur: 文書データの自動抽出、様々な文書からの構造化テキスト抽出概要 Parseurは、PDF、電子メール、その他のドキュメントからテキストデータを自動的に抽出するために設計された、業界をリードするAIデータ抽出ソフトウェアです。Parseurを使用すると、ユーザーは簡単に非構造化データを構造化データに変換し、様々なアプリケーションに送信することができます...最新のAIツール# ドキュメントの抽出とクリーニング5ヶ月前09390
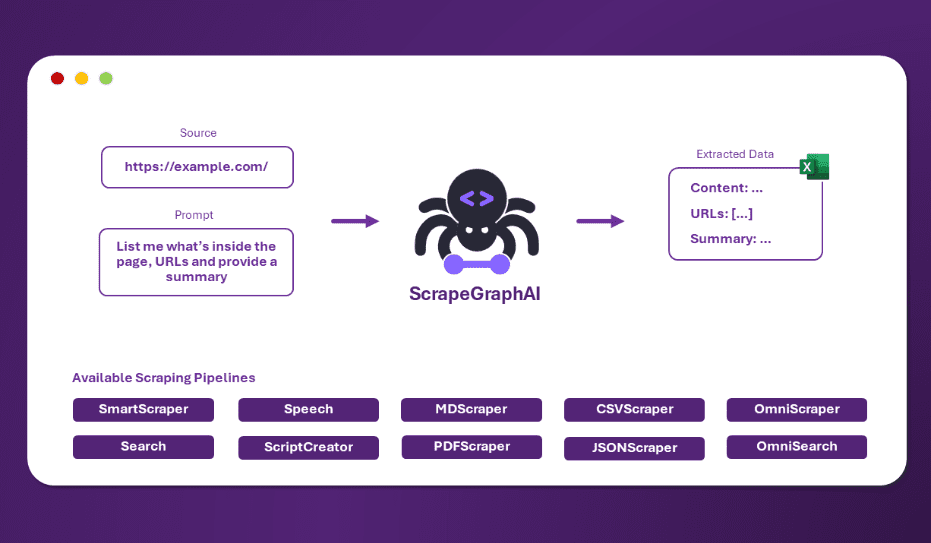
ScrapeGraphAI:ウェブクローリングのための単一のキューワード、ルールを書く必要のないインテリジェントなウェブコンテンツ抽出ツール综合介绍 ScrapeGraphAI是一个创新的Python网页抓取库,它巧妙地结合了大语言模型(LLM)和直接图逻辑来创建网站和本地文档的抓取管道。这个工具的独特之处在于它的简单性和强大功能的完美平...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前09140
NVインジェスト:複雑なフォーマットのドキュメントを解析し、マルチモーダルデータをメタデータとテキストに抽出する。包括的な紹介 NV Ingest (NVIDIA Ingest)は、何十万もの複雑で厄介な非構造化PDFやその他の企業ドキュメントを解析するために設計された、早期アクセス可能なマイクロサービス群です。これらのドキュメントをメタデータとテキストに変換し、検索に埋め込むことができます...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.1K0
Trellis: 構造化されていないドキュメントを構造化されたEXCEL形式のデータ、PDFに高速変換(有料)概要 Trellisは、複雑な非構造化データソースを構造化されたSQL形式に変換することに特化したデータプラットフォームです。Trellisは、その強力なAIエンジンを通じて、財務文書、音声通話、電子メールなどの幅広いデータソースを処理し、使用可能なデータに変換することができます。最新のAIツール# ドキュメントの抽出とクリーニング5ヶ月前08270
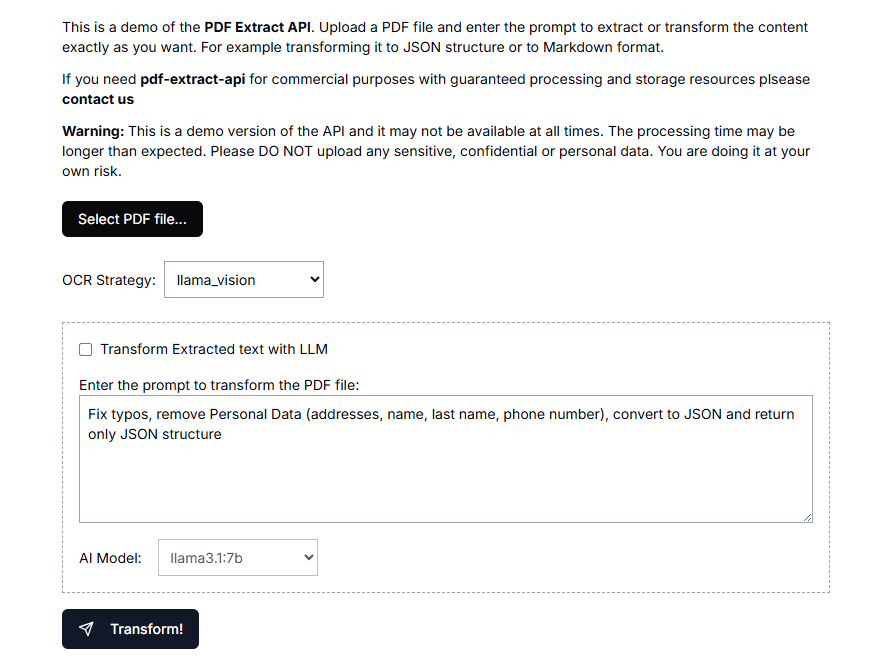
テキスト抽出 API (text-extract-api): テキスト情報の視覚的抽出、匿名化 PDF 抽出ツール综合介绍 文本提取API(text-extract-api)是一个强大的工具,旨在从各种文档格式(如PDF、Word、PPTX等)中提取和解析内容。该API利用最先进的光学字符识别(OCR)技术和Ol...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング5ヶ月前01.3K0
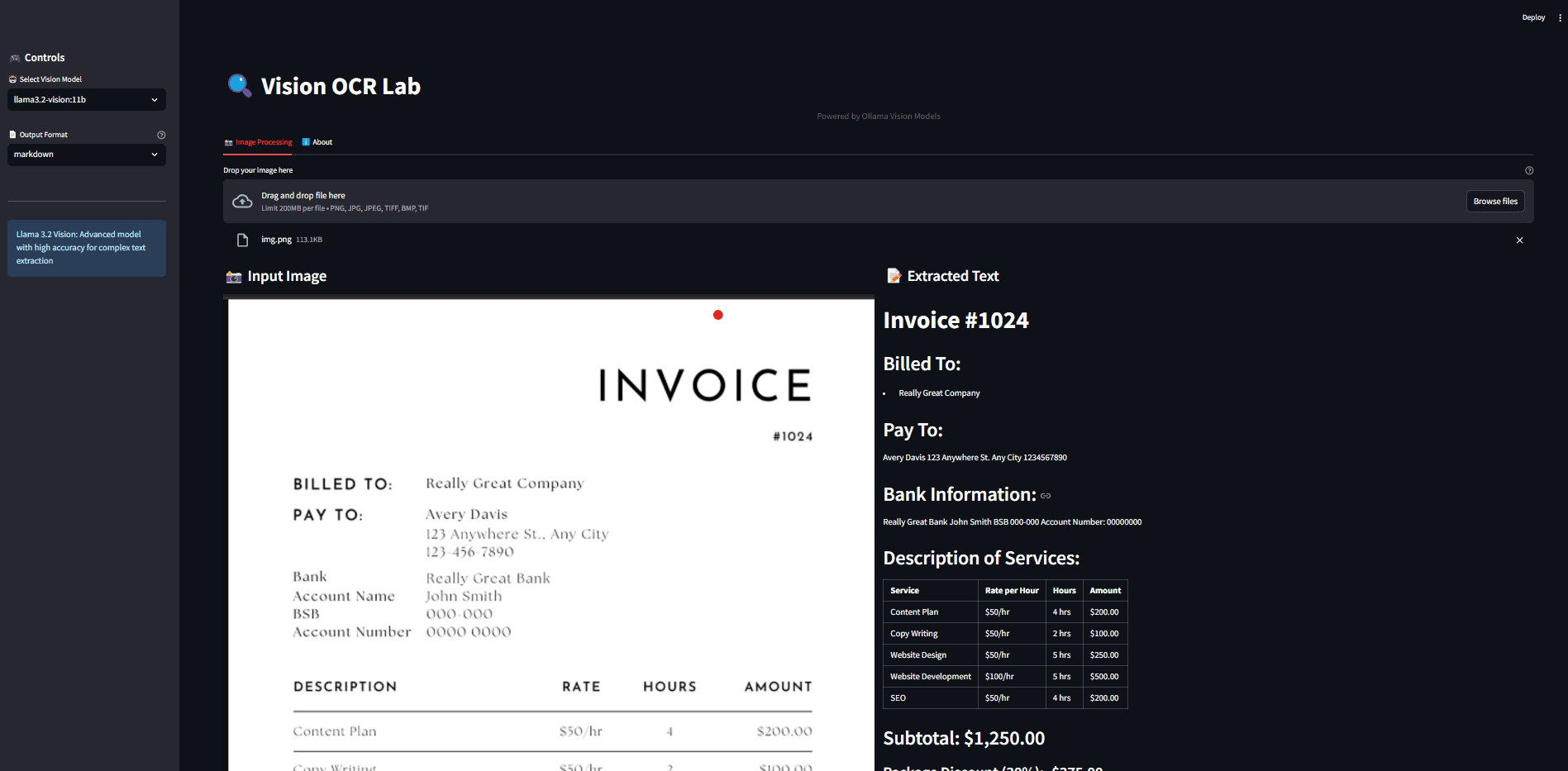
Ollama OCR: Ollamaの視覚モデルを使った画像からのテキスト抽出综合介绍 Ollama OCR是一个强大的光学字符识别(OCR)工具包,它利用Ollama平台提供的最先进视觉语言模型来从图像中提取文本。该项目既可作为Python包使用,也提供了用户友好的Strea...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング5ヶ月前01.9K0
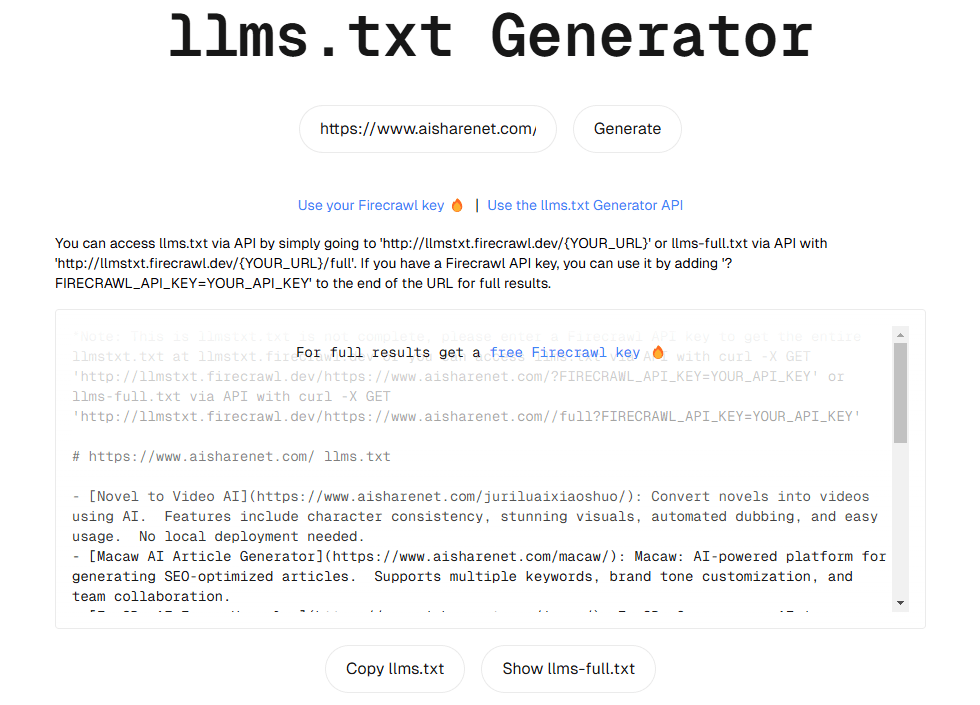
llms.txt Generator: Webサイトのコンテンツを素早くキャプチャし、LLMトレーニング用テキストデータセットを生成します。综合介绍 llmstxt-generator 是一个专业的网站内容提取和整合工具,专门为大语言模型(LLM)的训练和推理准备高质量文本数据集。该工具由 Mendable AI 开发,采用 @firec...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.2K0
ExtractThinker: ドキュメントを構造化データに抽出・分類し、ドキュメント処理プロセスを最適化します。综合介绍 ExtractThinker 是一个灵活的文档智能工具,利用大型语言模型(LLMs)从文档中提取和分类结构化数据,提供类似 ORM 的无缝文档处理工作流。它支持多种文档加载器,包括 Tess...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.1K0
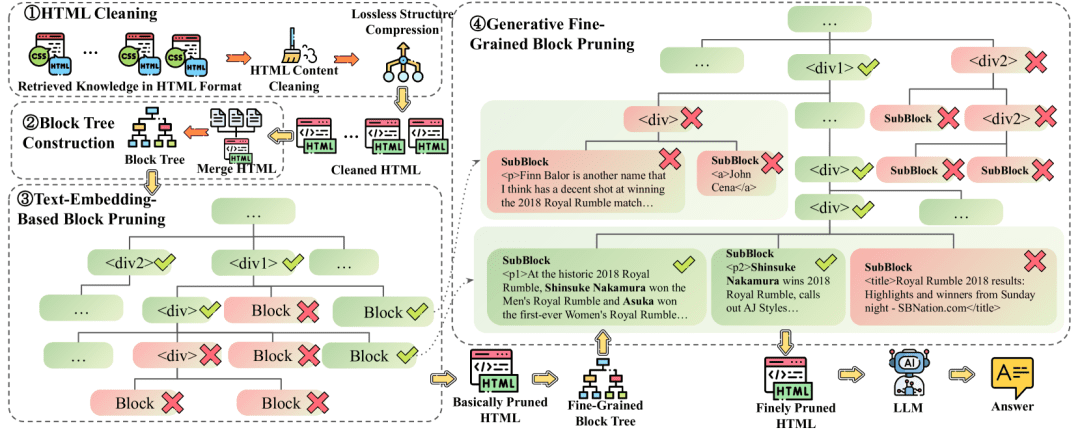
HtmlRAG:効率的なHTML検索拡張生成システムの構築、RAGシステムにおけるHTML文書の検索と処理の最適化综合介绍 HtmlRAG是一个创新的开源项目,专注于改进检索增强生成(RAG)系统中的HTML文档处理方法。该项目提出了一种新颖的方法,认为在RAG系统中使用HTML格式比纯文本更有效。项目包含了完整...最新のAIツール# ドキュメントの抽出とクリーニング# 知識検索とRAGフレームワーク5ヶ月前09140
Maxun:ウェブデータを自動的にクロールし、APIやスプレッドシートに変換するオープンソースのコード不要プラットフォーム综合介绍 Maxun是一个开源的无代码网页数据提取平台,用户可以在几分钟内训练机器人,自动抓取网页数据并将其转换为API或电子表格。该平台支持分页和滚动,能够适应网站布局的变化,提供强大的数据抓取功能...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.2K0
Vision Parse: 視覚言語モデルを用いたPDFドキュメントのMarkdownフォーマットへのインテリジェント変換综合介绍 Vision Parse是一个革命性的文档处理工具,它巧妙地结合了最先进的视觉语言模型(Vision Language Models)技术,能够将PDF文档智能转换为优质的Markdown格...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング5ヶ月前01.1K0
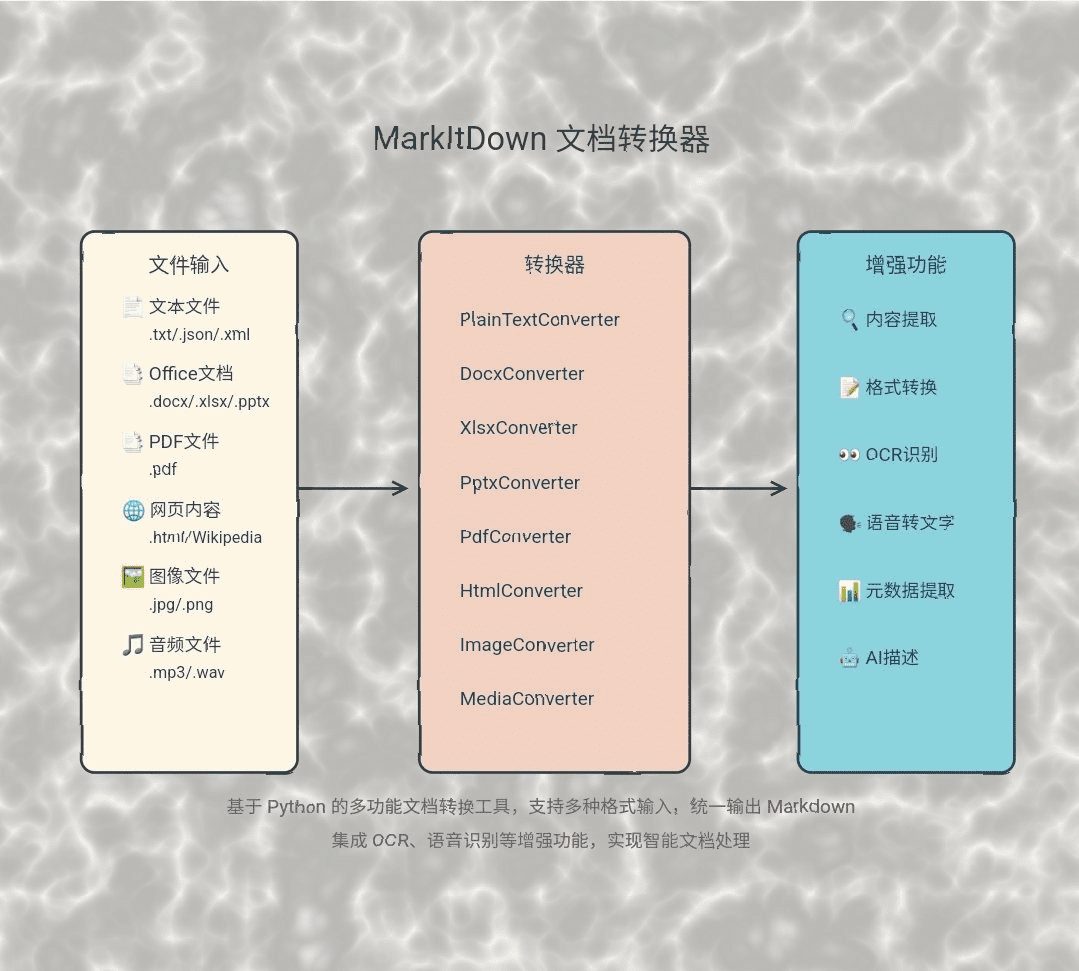
MarkItDown:Microsoftドキュメントインテリジェント変換ツール、様々なファイルをMarkdown形式に変換综合介绍 MarkItDown是由微软开发的一个Python工具,旨在将各种文件和办公文档转换为Markdown格式。该工具支持多种文件类型,包括PDF、PowerPoint、Word、Excel、图...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01.7K0
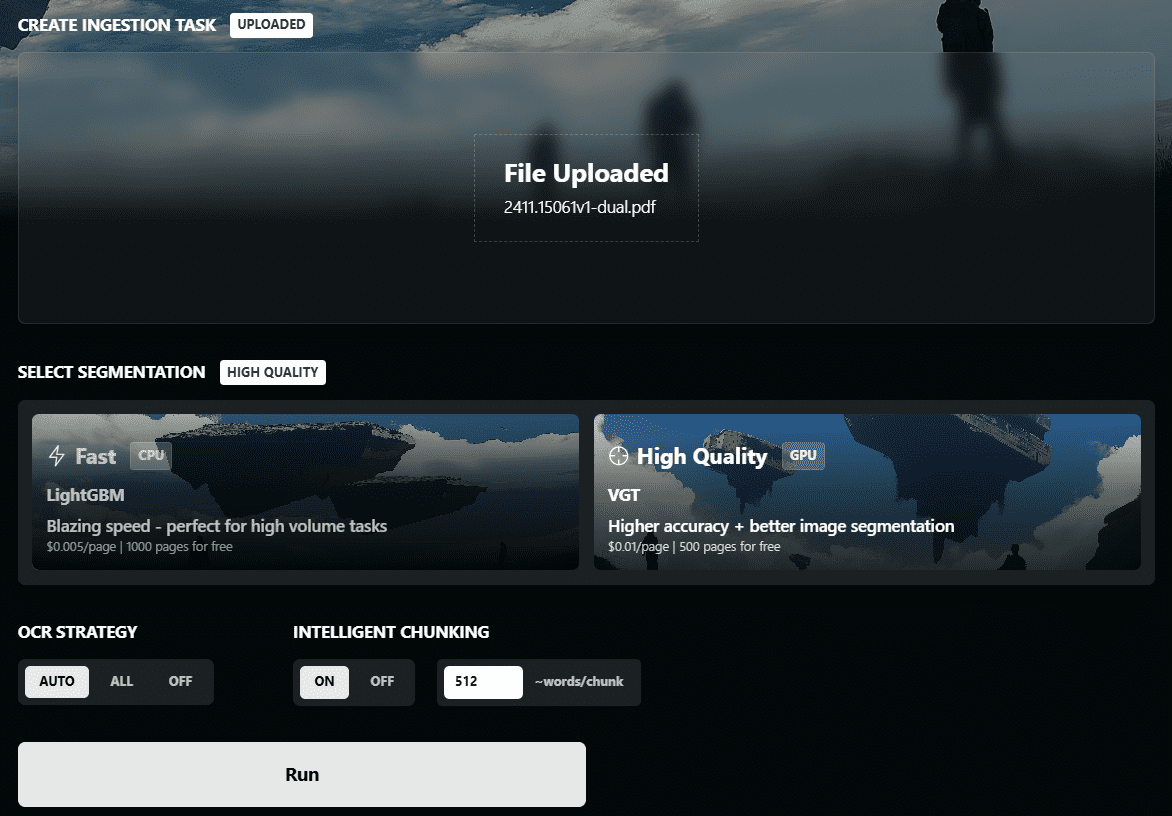
Chunkr: 文書の取り込みにビジュアルモデルを使用し、テキストの段落階層に基づくインテリジェントなチャンキングを行うオールインワンサービス。综合介绍 Chunkr 是一个自托管的 API,专门用于将 PDF、PPTX、DOCX 和 Excel 文件转换为适合 RAG(检索增强生成)和 LLM(大语言模型)使用的数据。该项目由 Lumina...最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング6ヶ月前01.1K0
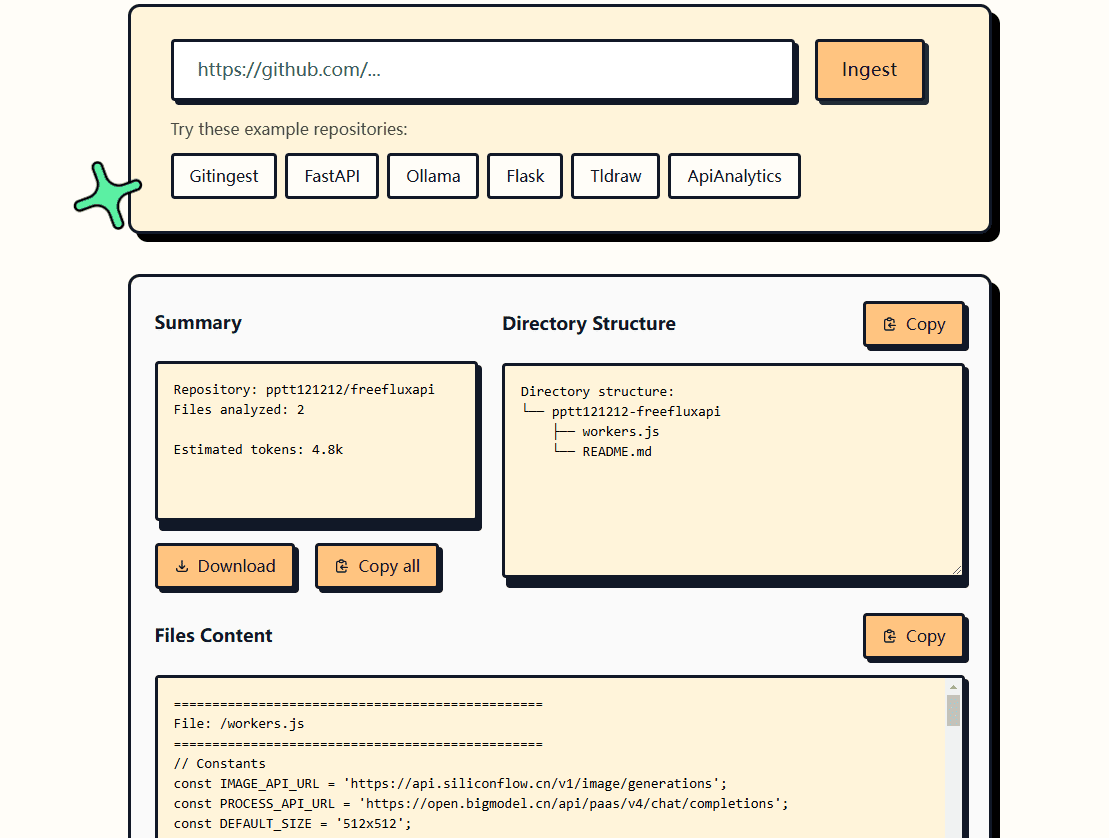
GitIngest: GithubのコードリポジトリをLLMの理解に適したテキストに素早く変換概要 GitIngestは、GitHubのコードリポジトリをLarge Language Model (LLM)のヒントに適したテキストに変換するためのオープンソースツールです。簡単な操作で、あらゆるGitHubリポジトリの内容を抽出し、LLMヒントに適合するように整形することができます。最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01.7K0
E2M: 複数のファイル形式をMarkdownに変換し、簡単に統一されたドキュメントフォーマットを実現する综合介绍 E2M(Everything to Markdown)是一个开源的Python库,旨在将多种文件格式转换为Markdown格式。该工具支持包括doc、docx、epub、html、htm、u...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01K0
Docling:様々なフォーマットのドキュメントをサポート MarkdownやJSONへの解析とエクスポート PDFサポート OCR包括的な紹介 Doclingは、PDF、DOCX、PPTX、XLSX、画像、HTML、AsciiDocおよびMarkdownを含む幅広い文書形式をサポートする強力な文書解析およびエクスポートツールです。最新のAIツール# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング6ヶ月前01.8K0
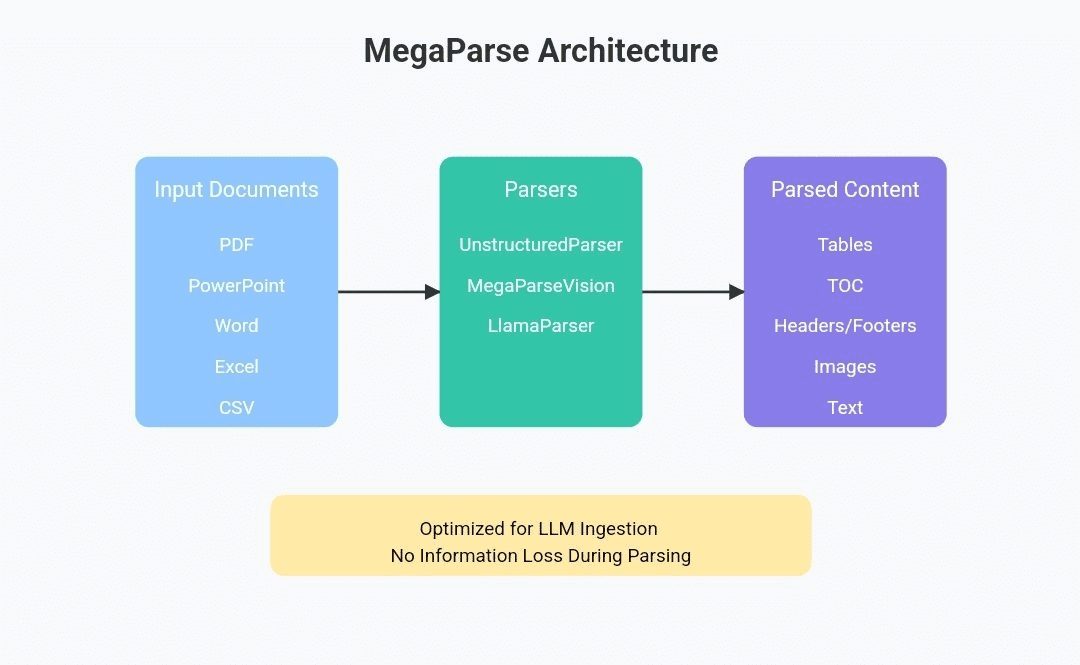
MegaParse:各タイプのドキュメントをLLMで利用可能なデータに解析し、表や写真などドキュメント内のすべての情報をそのまま保存する。综合介绍 MegaParse 是一个强大且多功能的文件解析工具,专为大语言模型(LLM)的数据处理优化而设计。无论是处理文本、PDF、PowerPoint 演示文稿还是 Word 文档,MegaPar...最新のAIツール# AI Java オープンソースプロジェクト# ドキュメントの抽出とクリーニング6ヶ月前01.5K0
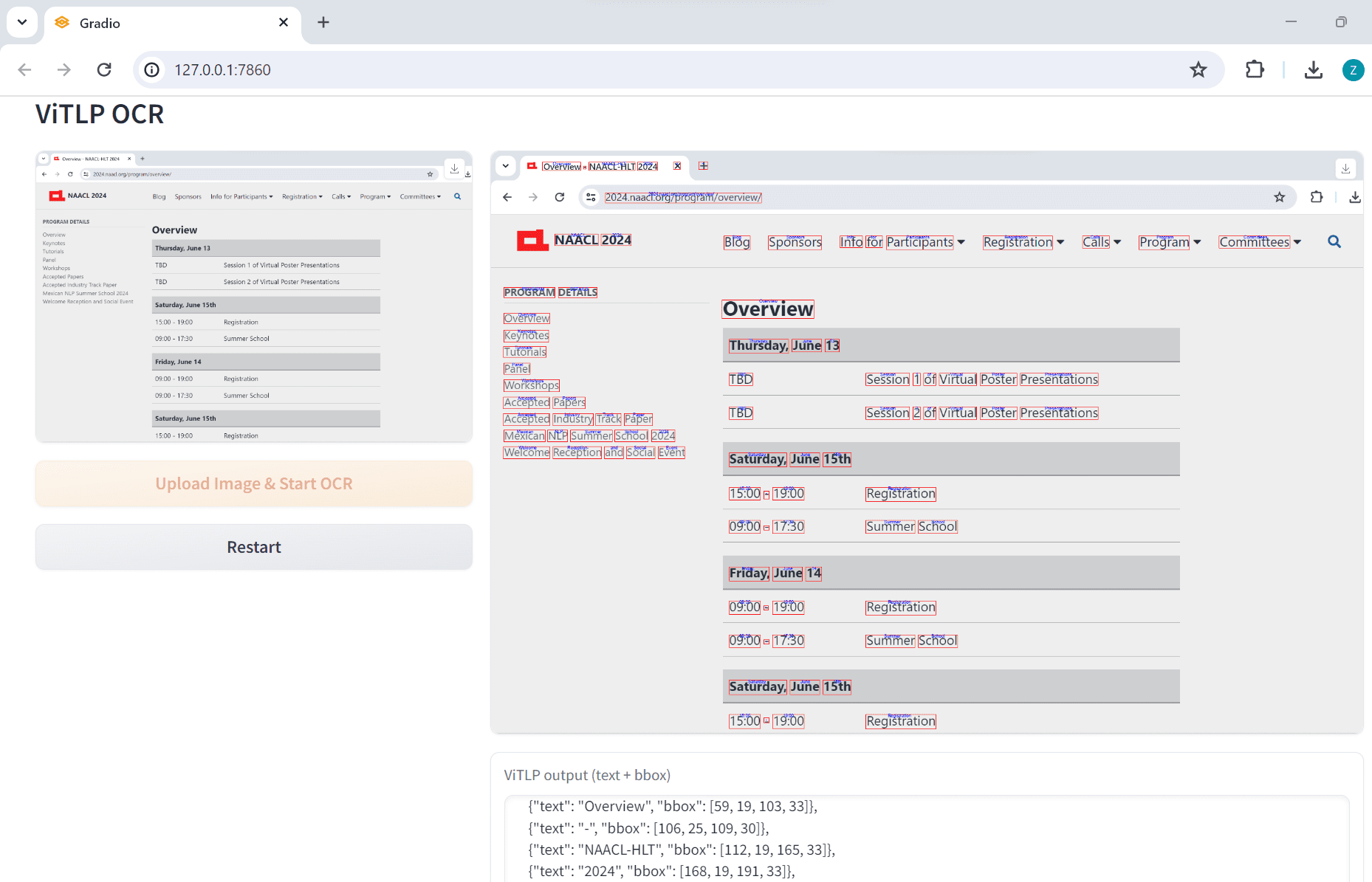
ViTLP: 組版が複雑なPDF文書から構造化データを抽出し、テキストレイアウトのための事前学習済みモデルを視覚的に誘導して生成する综合介绍 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)是一个开源项目,旨在通...最新のAIツール# OCR# ドキュメントの抽出とクリーニング6ヶ月前09940