UnDatas.IO: API-Dienst für die genaue Analyse verschiedener Arten von unstrukturierten Daten (kostenpflichtig)
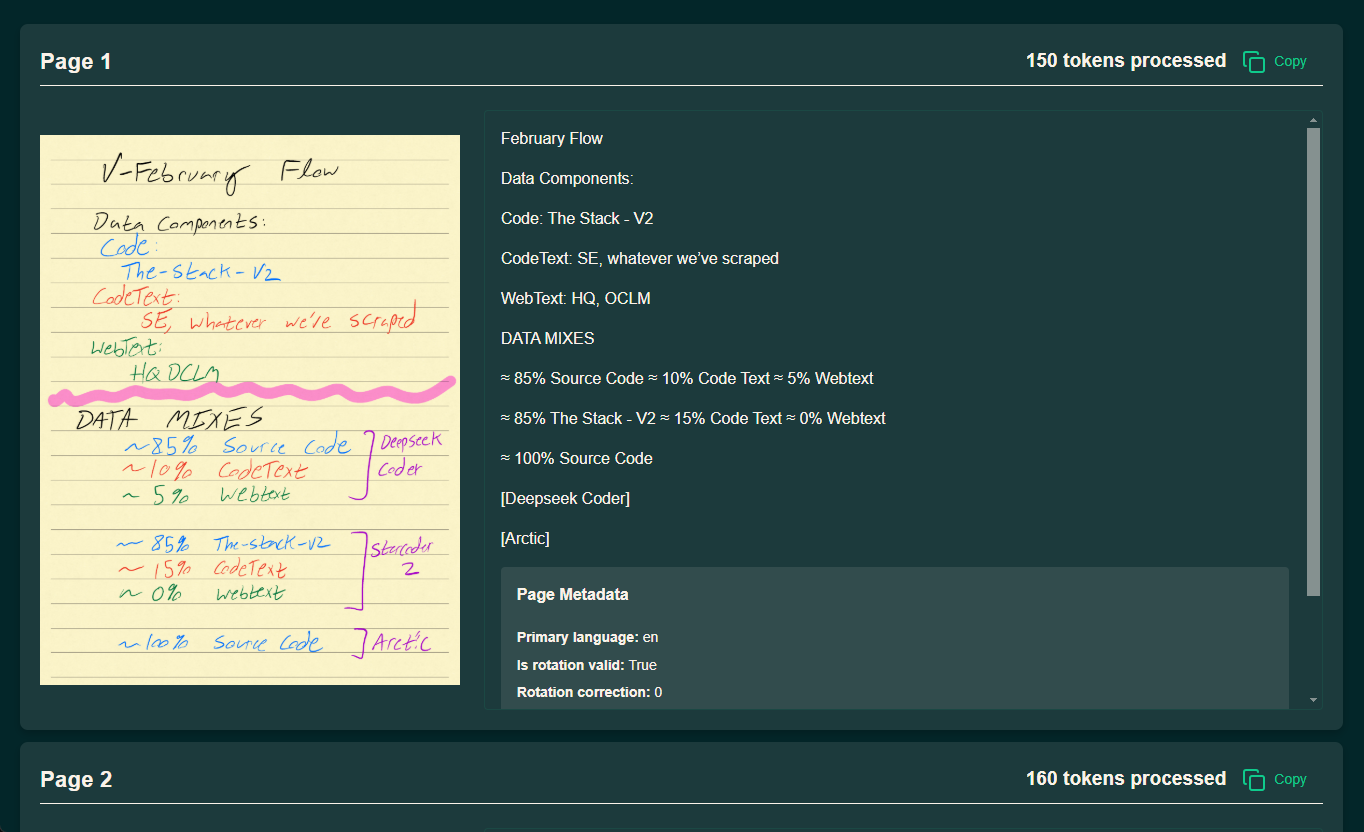
Umfassende Einführung UnDatas.IO ist eine Plattform, die sich auf das Parsing und die Verarbeitung unstrukturierter Daten konzentriert. Sie nutzt fortschrittliche Technologien zur automatischen Erkennung von Dokumentenlayouts und zur Klassifizierung von Tabellen, Bildern, Formeln und Text, wodurch der Datenverarbeitungsprozess erheblich vereinfacht wird. Die Plattform spart nicht nur viel Zeit beim Sortieren der Daten...